Quantization Error Propagation: Revisiting Layer-Wise Post-Training Quantization
作者: Yamato Arai, Yuma Ichikawa
分类: cs.LG, stat.AP, stat.ME, stat.ML
发布日期: 2025-04-13 (更新: 2026-01-13)
备注: 29 pages, 3 figures, Accepted at NeurIPS 2025
💡 一句话要点
提出量化误差传播(QEP)框架,提升低比特量化下LLM的层间量化精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化 后训练量化 大语言模型 模型压缩 误差传播 低比特量化 层间量化
📋 核心要点
- 现有层间PTQ方法在低比特量化时,由于量化误差在层间累积,导致性能显著下降。
- 论文提出QEP框架,通过显式传播和补偿量化误差,缓解误差累积问题,提升量化精度。
- 实验表明,QEP在多种LLM上显著提升了低比特量化的精度,优于现有方法。
📝 摘要(中文)
本文针对大语言模型(LLM)的层间后训练量化(PTQ)技术,指出其性能瓶颈在于量化误差在层间的累积,尤其是在低比特量化时。为了解决这个问题,作者提出了量化误差传播(QEP)框架,这是一个通用、轻量级且可扩展的框架,通过显式地传播量化误差并补偿累积误差来增强层间PTQ。QEP还提供了一个可调的传播机制,可以防止过拟合并控制计算开销,从而使该框架能够适应各种架构和资源预算。在多个LLM上的大量实验表明,QEP增强的层间PTQ比现有方法实现了更高的精度,尤其是在极低比特量化的情况下。
🔬 方法详解
问题定义:论文旨在解决层间后训练量化(PTQ)中,量化误差在网络层间传播和累积的问题。现有方法忽略了这一问题,导致在低比特量化时性能显著下降。尤其是在大语言模型(LLM)上,这种误差累积会严重影响模型的准确性。
核心思路:论文的核心思路是显式地建模和传播量化误差,并在后续层中对这些误差进行补偿。通过这种方式,可以减轻量化误差在层间的累积效应,从而提高整体的量化精度。这种方法旨在更准确地模拟量化对模型的影响,并相应地调整模型的参数。
技术框架:QEP框架主要包含两个阶段:误差传播阶段和误差补偿阶段。在误差传播阶段,每一层的量化误差被估计并传递到下一层。在误差补偿阶段,后续层利用接收到的误差信息来调整其量化参数,从而抵消累积的误差。该框架提供了一个可调的传播机制,允许用户控制误差传播的强度,以防止过拟合和控制计算开销。
关键创新:QEP的关键创新在于显式地建模和利用量化误差信息。与传统的层间PTQ方法不同,QEP不仅关注每一层的量化,还考虑了量化误差在层间的相互影响。这种全局视角使得QEP能够更有效地优化量化过程,尤其是在低比特量化的情况下。
关键设计:QEP的关键设计包括误差估计方法、误差传播策略和误差补偿机制。误差估计可以使用多种方法,例如基于梯度的估计或基于统计的估计。误差传播策略可以采用不同的权重,以控制误差传播的强度。误差补偿机制可以通过调整量化参数或引入额外的补偿项来实现。此外,QEP还提供了一个可调参数来控制误差传播的范围,以平衡精度和计算成本。
🖼️ 关键图片
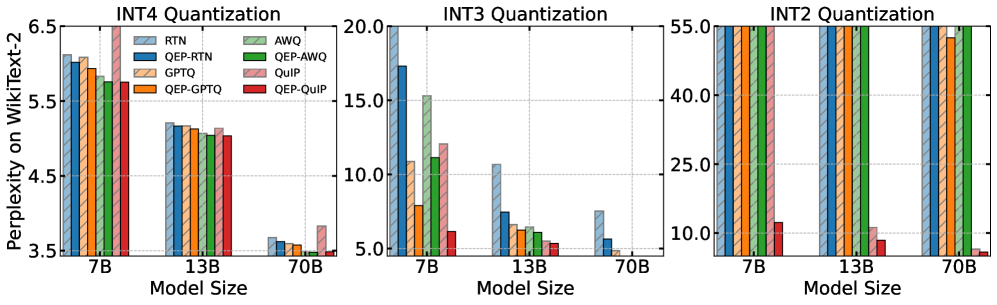
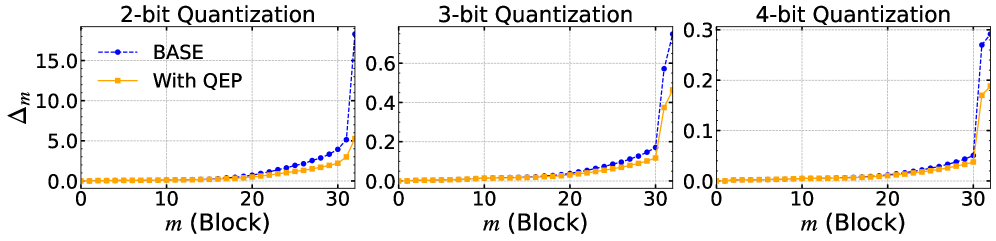
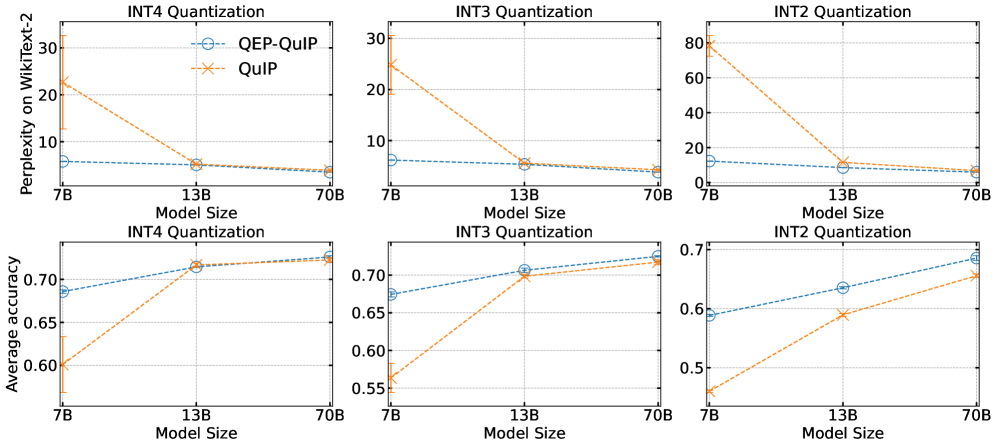
📊 实验亮点
实验结果表明,QEP增强的层间PTQ在多个LLM上实现了显著的精度提升,尤其是在极低比特量化(例如,2比特和3比特)的情况下。与现有的层间PTQ方法相比,QEP能够更好地保持模型的性能,从而验证了其有效性。
🎯 应用场景
该研究成果可应用于大语言模型的压缩和加速,尤其是在资源受限的设备上,例如移动设备和嵌入式系统。通过降低模型的存储空间和计算复杂度,QEP可以使LLM在这些设备上更高效地运行,从而促进人工智能技术的普及和应用。
📄 摘要(原文)
Layer-wise PTQ is a promising technique for compressing large language models (LLMs), due to its simplicity and effectiveness without requiring retraining. However, recent progress in this area is saturating, underscoring the need to revisit its core limitations and explore further improvements. We address this challenge by identifying a key limitation of existing layer-wise PTQ methods: the growth of quantization errors across layers significantly degrades performance, particularly in low-bit regimes. To address this fundamental issue, we propose Quantization Error Propagation (QEP), a general, lightweight, and scalable framework that enhances layer-wise PTQ by explicitly propagating quantization errors and compensating for accumulated errors. QEP also offers a tunable propagation mechanism that prevents overfitting and controls computational overhead, enabling the framework to adapt to various architectures and resource budgets. Extensive experiments on several LLMs demonstrate that QEP-enhanced layer-wise PTQ achieves substantially higher accuracy than existing methods. Notably, the gains are most pronounced in the extremely low-bit quantization regime.