VectorLiteRAG: Latency-Aware and Fine-Grained Resource Partitioning for Efficient RAG
作者: Junkyum Kim, Divya Mahajan
分类: cs.LG
发布日期: 2025-04-11 (更新: 2025-08-25)
💡 一句话要点
VectorLiteRAG:面向低延迟的RAG系统细粒度资源分配方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RAG系统 向量检索 大型语言模型 资源分配 性能优化 索引分区 低延迟
📋 核心要点
- 现有RAG系统在共享GPU资源时,向量检索与LLM推理相互干扰,导致性能下降,尤其是在高负载或大索引下。
- VectorLiteRAG通过性能建模和访问模式分析,实现细粒度的GPU资源分配,优化CPU/GPU索引分区,减少资源争用。
- 实验表明,VectorLiteRAG在各种配置下均能提升SLO吞吐量,最高可达1.5倍,且无需额外硬件资源。
📝 摘要(中文)
检索增强生成(RAG)系统结合了向量相似性搜索和大型语言模型(LLM),以提供准确的、上下文感知的响应。然而,将向量检索器和LLM共同部署在共享GPU基础设施上会带来重大挑战:向量搜索是内存和I/O密集型的,而LLM推理需要高吞吐量和低延迟。简单的资源共享通常会导致严重的性能下降,尤其是在高请求负载或大型索引大小的情况下。我们提出了VectorLiteRAG,一个易于部署的RAG系统,它可以在不需要额外硬件资源的情况下实现符合延迟要求的推理。VectorLiteRAG引入了一种基于详细性能建模和访问模式分析的细粒度GPU资源分配机制。通过估计搜索延迟和查询命中率分布,它确定了CPU和GPU层之间的最佳索引分区点,以最大限度地减少争用并最大化吞吐量。我们的评估表明,与朴素基线和最先进的替代方案相比,VectorLiteRAG始终在所有测试配置(包括小型和大型LLM以及小型和大型向量数据库)中扩展了符合SLO的请求速率范围。在最佳情况下,VectorLiteRAG在不影响生成质量或需要额外计算资源的情况下,将可实现的SLO吞吐量提高了高达1.5倍。
🔬 方法详解
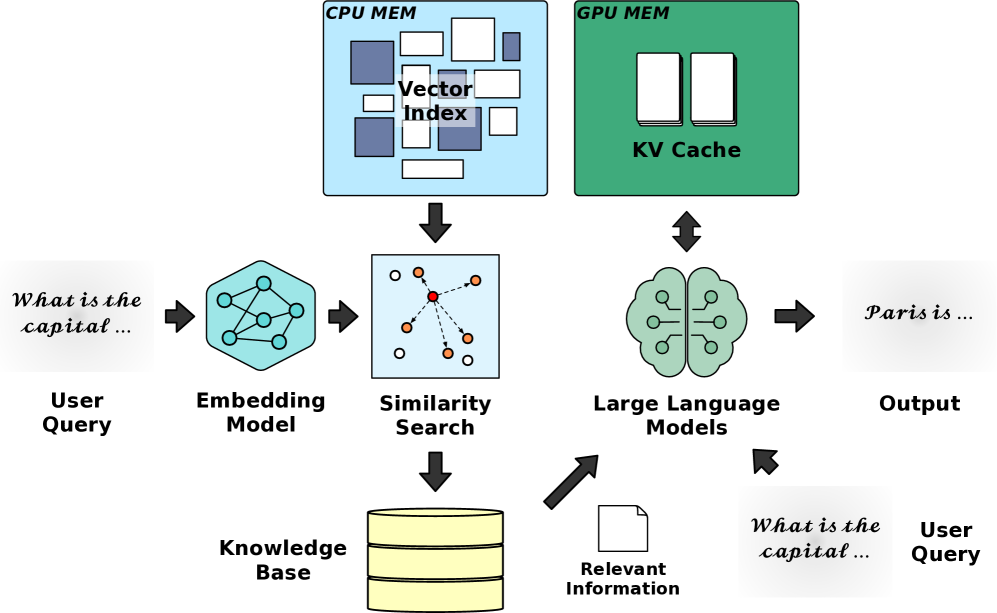
问题定义:现有RAG系统在共享GPU资源时,向量检索(内存/IO密集)和LLM推理(计算密集,低延迟要求)相互竞争,导致整体性能下降。尤其是在高并发请求和大索引规模下,资源争用问题更加严重,难以保证服务质量(SLO)。
核心思路:VectorLiteRAG的核心思路是通过细粒度的资源分配和索引分区,将向量检索和LLM推理的资源需求进行解耦,从而减少资源争用,提高整体吞吐量并满足延迟要求。关键在于根据实际负载和数据特性,动态地调整CPU和GPU之间的索引划分比例。
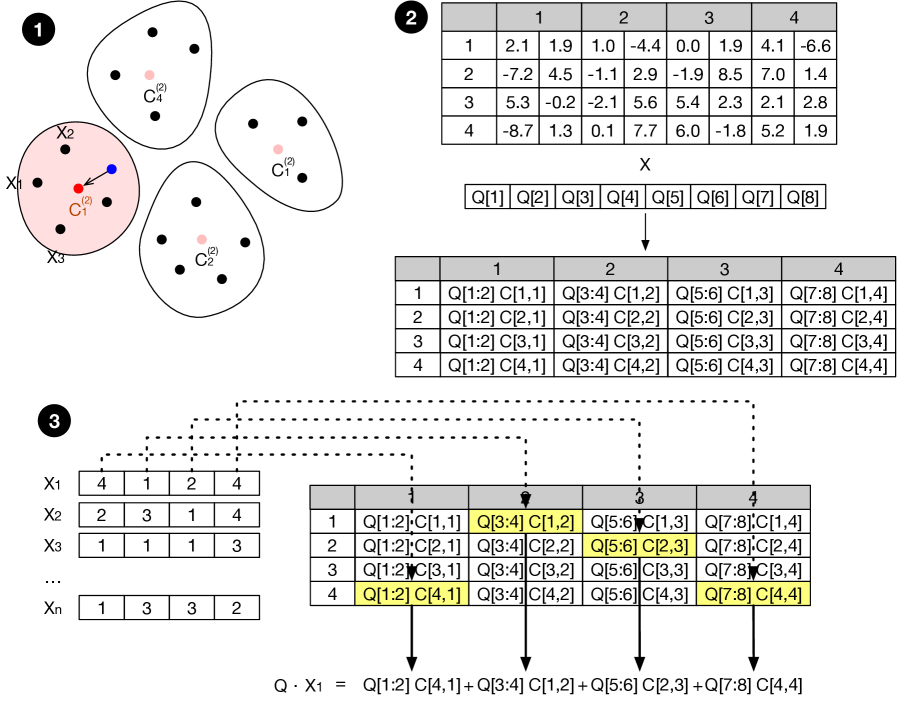
技术框架:VectorLiteRAG包含以下主要模块:1) 性能建模模块:对向量检索和LLM推理的性能进行建模,预测不同资源分配下的延迟和吞吐量。2) 访问模式分析模块:分析查询的访问模式,例如查询命中率分布。3) 索引分区优化模块:基于性能模型和访问模式分析,确定最佳的CPU/GPU索引分区点。4) 资源分配模块:根据优化后的索引分区,动态地分配GPU资源给向量检索和LLM推理。
关键创新:VectorLiteRAG的关键创新在于其细粒度的资源分配机制和基于性能建模的索引分区优化策略。与传统的静态资源分配方法不同,VectorLiteRAG能够根据实际负载和数据特性,动态地调整资源分配,从而更好地适应不同的应用场景。此外,基于性能建模的索引分区优化策略能够有效地预测不同分区方案下的性能,从而选择最佳的分区方案。
关键设计:VectorLiteRAG的关键设计包括:1) 性能模型的选择:需要选择合适的性能模型来准确地预测向量检索和LLM推理的延迟和吞吐量。2) 访问模式分析方法:需要设计有效的访问模式分析方法来准确地估计查询命中率分布。3) 索引分区优化算法:需要设计高效的优化算法来找到最佳的CPU/GPU索引分区点。4) 资源分配策略:需要设计合理的资源分配策略来保证向量检索和LLM推理的资源需求。
🖼️ 关键图片
📊 实验亮点
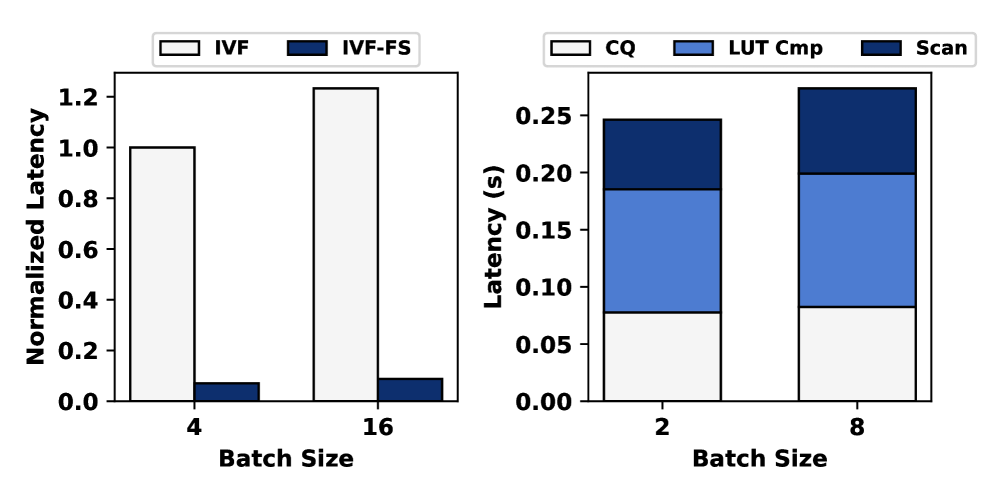
实验结果表明,VectorLiteRAG在各种配置下均能提升SLO吞吐量。与朴素基线相比,VectorLiteRAG在最佳情况下可以将SLO吞吐量提高高达1.5倍,且无需额外的硬件资源。此外,VectorLiteRAG在小型和大型LLM以及小型和大型向量数据库上均表现出良好的性能。
🎯 应用场景
VectorLiteRAG适用于需要低延迟和高吞吐量的RAG应用场景,例如智能客服、问答系统、知识库检索等。该研究成果可以帮助企业在有限的硬件资源下,构建更高效、更可靠的RAG系统,提升用户体验,降低运营成本。未来,该技术可以进一步扩展到其他类型的AI应用中,例如推荐系统、搜索系统等。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) systems combine vector similarity search with large language models (LLMs) to deliver accurate, context-aware responses. However, co-locating the vector retriever and the LLM on shared GPU infrastructure introduces significant challenges: vector search is memory and I/O intensive, while LLM inference demands high throughput and low latency. Naive resource sharing often leads to severe performance degradation, particularly under high request load or large index sizes. We present VectorLiteRAG, a deployment-friendly RAG system that achieves latency-compliant inference without requiring additional hardware resources. VectorLiteRAG introduces a fine-grained GPU resource allocation mechanism based on detailed performance modeling and access pattern analysis. By estimating search latency and query hit rate distributions, it identifies an optimal index partitioning point across CPU and GPU tiers to minimize contention and maximize throughput. Our evaluations show that VectorLiteRAG consistently expands the SLO compliant request rate range across all tested configurations, including both small and large LLMs, and small and large vector databases compared to naive baselines and state of the art alternatives. In the best case, VectorLiteRAG improves the attainable SLO throughput by up to 1.5 times without compromising generation quality or requiring additional compute resources.