HyperCore: The Core Framework for Building Hyperbolic Foundation Models with Comprehensive Modules
作者: Neil He, Menglin Yang, Rex Ying
分类: cs.LG, cs.AI
发布日期: 2025-04-11
备注: 11 pages, 4 figures
💡 一句话要点
HyperCore:构建双曲基础模型的全面模块化核心框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双曲神经网络 基础模型 开源框架 视觉Transformer 多模态学习 图神经网络 层次结构数据
📋 核心要点
- 现有工具缺乏构建双曲基础模型的关键组件,阻碍了双曲空间在深度学习中的应用。
- HyperCore提供了一套全面的模块,简化了双曲基础模型的构建过程,避免了重复开发。
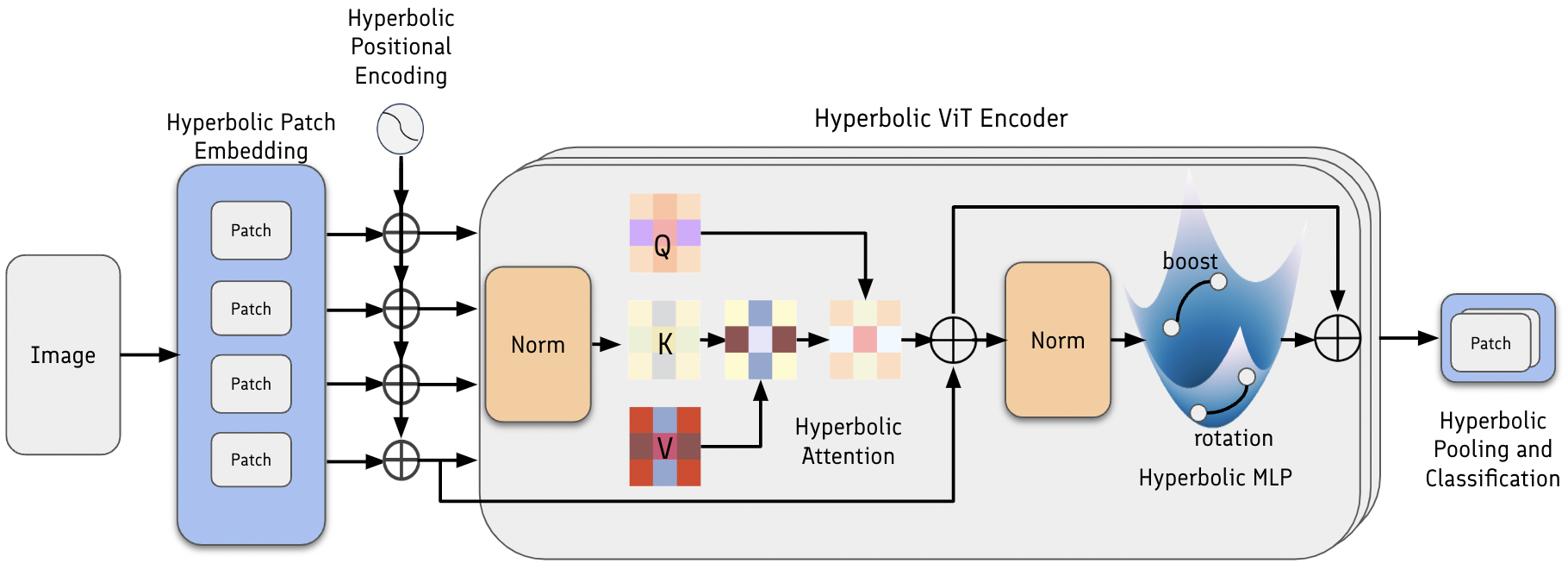
- 实验证明,基于HyperCore构建的双曲视觉Transformer (LViT) 性能优于其欧几里得版本。
📝 摘要(中文)
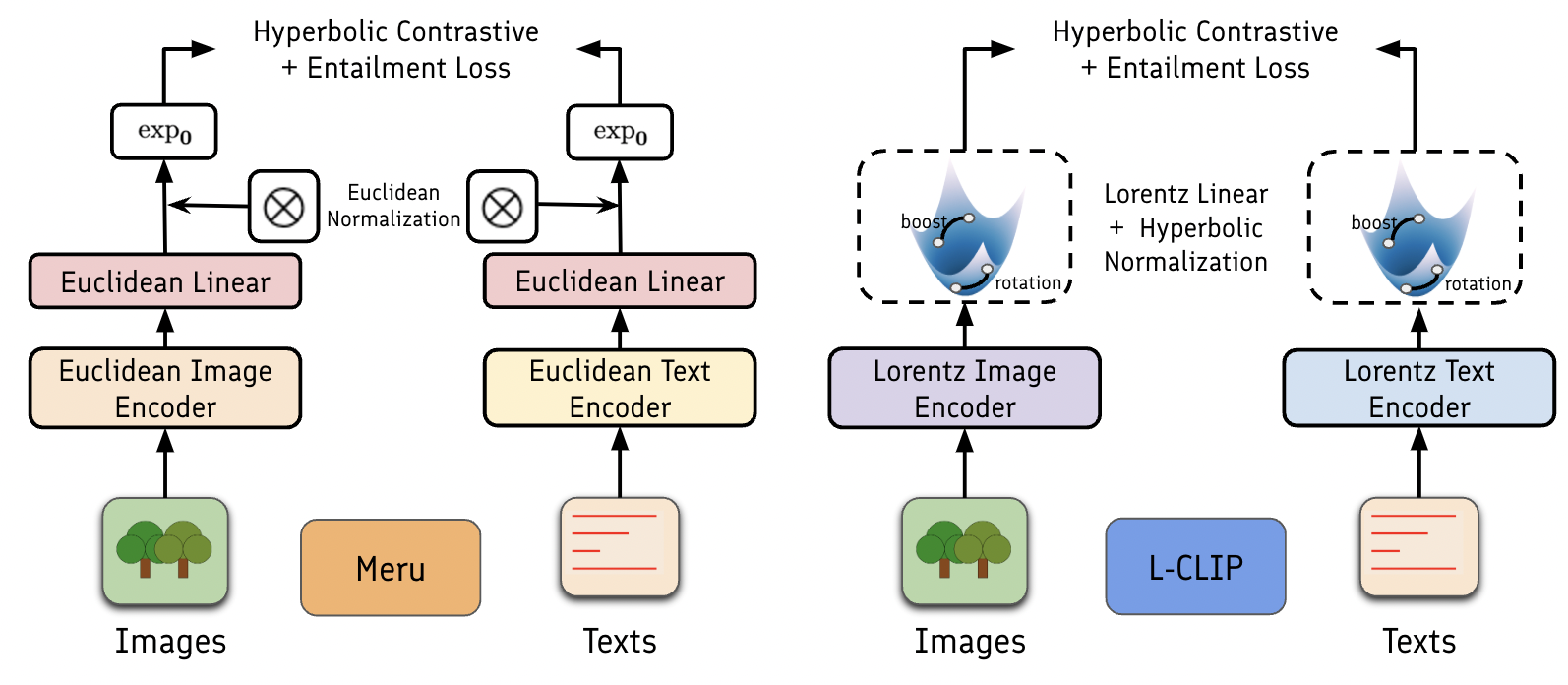
双曲神经网络已成为对跨多种模态的分层数据进行建模的强大工具。最近的研究表明,基础模型中的token分布表现出无标度特性,这表明双曲空间比欧几里得空间更适合许多预训练和下游任务。然而,现有的工具缺乏构建双曲基础模型的基本组件,使得难以利用最新的进展。我们介绍了HyperCore,这是一个全面的开源框架,它提供了构建跨多种模态的双曲基础模型的核心模块。HyperCore的模块可以轻松组合以开发新的双曲基础模型,无需从头开始大量修改欧几里得模块,并避免可能的冗余研究工作。为了展示其多功能性,我们构建并测试了第一个完全双曲的视觉Transformer(LViT)与微调流程,第一个完全双曲的多模态CLIP模型(L-CLIP),以及一个带有双曲图编码器的混合图RAG。我们的实验表明,LViT优于其欧几里得对应模型。此外,我们对双曲GNN、CNN、Transformer和视觉Transformer进行了基准测试和复现实验,以突出HyperCore的优势。
🔬 方法详解
问题定义:现有深度学习框架主要针对欧几里得空间设计,缺乏对双曲几何的有效支持。这使得研究人员在构建双曲神经网络时,需要从头开始实现许多基础模块,或者对现有的欧几里得模块进行大量修改,效率低下且容易出错。此外,缺乏统一的框架也导致了研究的碎片化和重复投入。
核心思路:HyperCore的核心思路是提供一套完整的、模块化的双曲神经网络构建工具箱。通过将常用的双曲几何操作和神经网络层封装成易于使用的模块,HyperCore降低了构建双曲模型的门槛,使得研究人员可以专注于模型设计和实验,而无需关心底层的双曲几何实现细节。
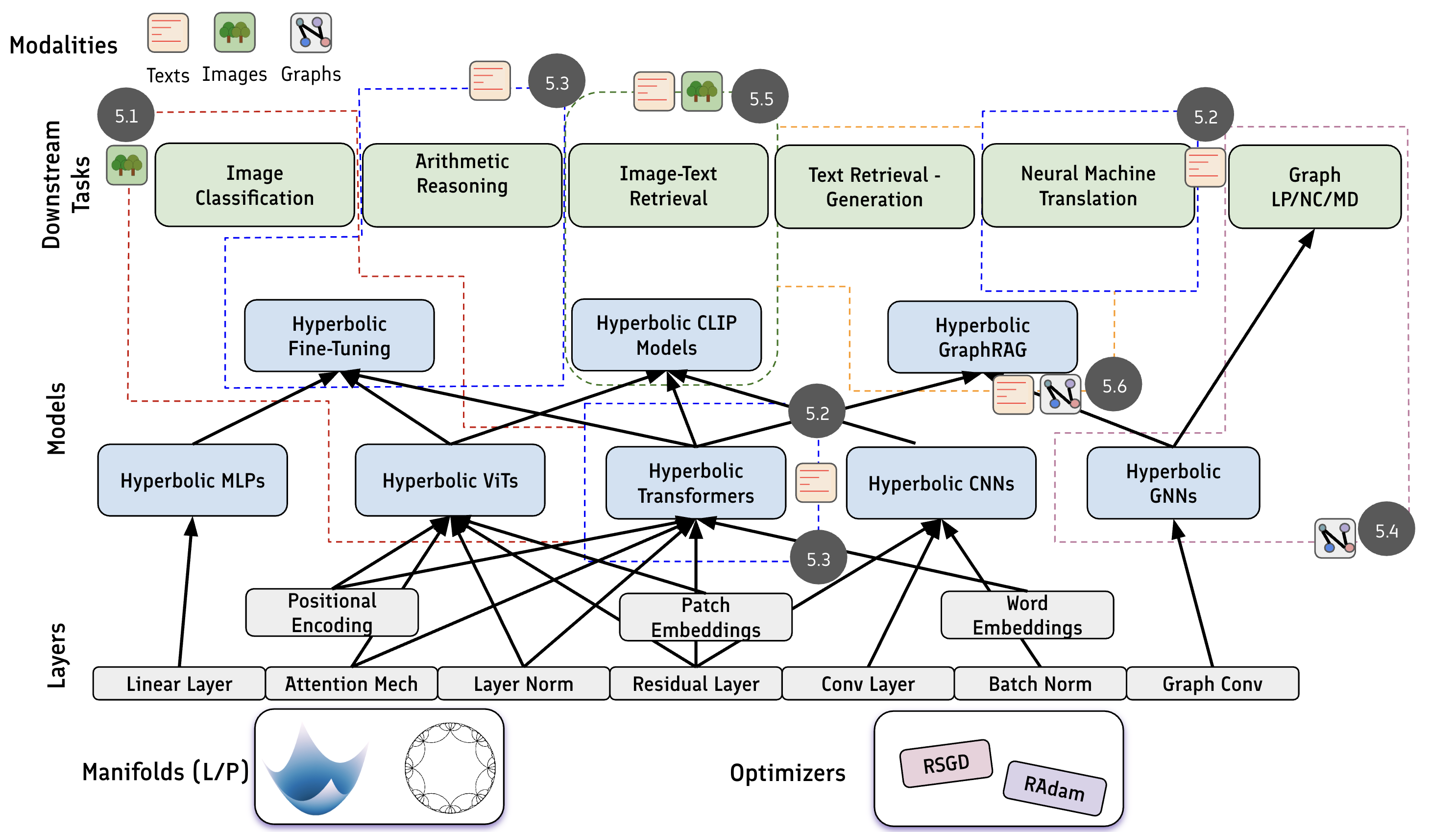
技术框架:HyperCore框架包含以下主要模块:1) 双曲几何操作模块:提供双曲空间中的距离计算、指数映射、对数映射等基本操作。2) 双曲神经网络层模块:包括双曲线性层、双曲激活函数、双曲注意力机制等。3) 模型构建模块:提供预定义的双曲模型结构,如双曲Transformer、双曲GNN等。4) 评估模块:提供双曲模型的评估指标和可视化工具。研究人员可以根据自己的需求,选择合适的模块进行组合,构建自定义的双曲神经网络模型。
关键创新:HyperCore的关键创新在于其全面性和模块化设计。它不仅提供了双曲神经网络的基本构建模块,还提供了预定义的模型结构和评估工具,使得研究人员可以快速构建、训练和评估双曲模型。此外,HyperCore的模块化设计使得研究人员可以轻松地扩展和定制框架,以适应不同的应用场景。
关键设计:HyperCore的关键设计包括:1) 使用PyTorch作为底层框架,方便研究人员使用和扩展。2) 提供了一套统一的API,使得不同的模块可以无缝集成。3) 针对不同的双曲几何模型(如Poincaré ball model, Lorentz model)提供了不同的实现,以满足不同的需求。4) 提供了详细的文档和示例代码,方便研究人员学习和使用。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于HyperCore构建的双曲视觉Transformer (LViT) 在图像分类任务上优于其欧几里得版本。此外,HyperCore还成功地构建了第一个完全双曲的多模态CLIP模型(L-CLIP),并验证了其在多模态任务上的有效性。对双曲GNN、CNN、Transformer和视觉Transformer进行了基准测试和复现实验,进一步证明了HyperCore的优势。
🎯 应用场景
HyperCore可广泛应用于需要处理层次结构数据的领域,例如知识图谱嵌入、自然语言处理、计算机视觉和推荐系统。通过利用双曲空间的特性,HyperCore可以更有效地表示和处理这些数据,从而提高模型的性能和效率。未来,HyperCore有望成为双曲深度学习领域的重要基础设施,推动相关研究的快速发展。
📄 摘要(原文)
Hyperbolic neural networks have emerged as a powerful tool for modeling hierarchical data across diverse modalities. Recent studies show that token distributions in foundation models exhibit scale-free properties, suggesting that hyperbolic space is a more suitable ambient space than Euclidean space for many pre-training and downstream tasks. However, existing tools lack essential components for building hyperbolic foundation models, making it difficult to leverage recent advancements. We introduce HyperCore, a comprehensive open-source framework that provides core modules for constructing hyperbolic foundation models across multiple modalities. HyperCore's modules can be effortlessly combined to develop novel hyperbolic foundation models, eliminating the need to extensively modify Euclidean modules from scratch and possible redundant research efforts. To demonstrate its versatility, we build and test the first fully hyperbolic vision transformers (LViT) with a fine-tuning pipeline, the first fully hyperbolic multimodal CLIP model (L-CLIP), and a hybrid Graph RAG with a hyperbolic graph encoder. Our experiments demonstrate that LViT outperforms its Euclidean counterpart. Additionally, we benchmark and reproduce experiments across hyperbolic GNNs, CNNs, Transformers, and vision Transformers to highlight HyperCore's advantages.