Mimic In-Context Learning for Multimodal Tasks
作者: Yuchu Jiang, Jiale Fu, Chenduo Hao, Xinting Hu, Yingzhe Peng, Xin Geng, Xu Yang
分类: cs.LG, cs.AI
发布日期: 2025-04-11 (更新: 2025-05-17)
备注: 14 pages, 7 figures,CVPR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出MimIC以提高多模态任务中的上下文学习稳定性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 多模态模型 偏移向量 学习模块 图像问答 图像描述生成 模型泛化 注意力机制
📋 核心要点
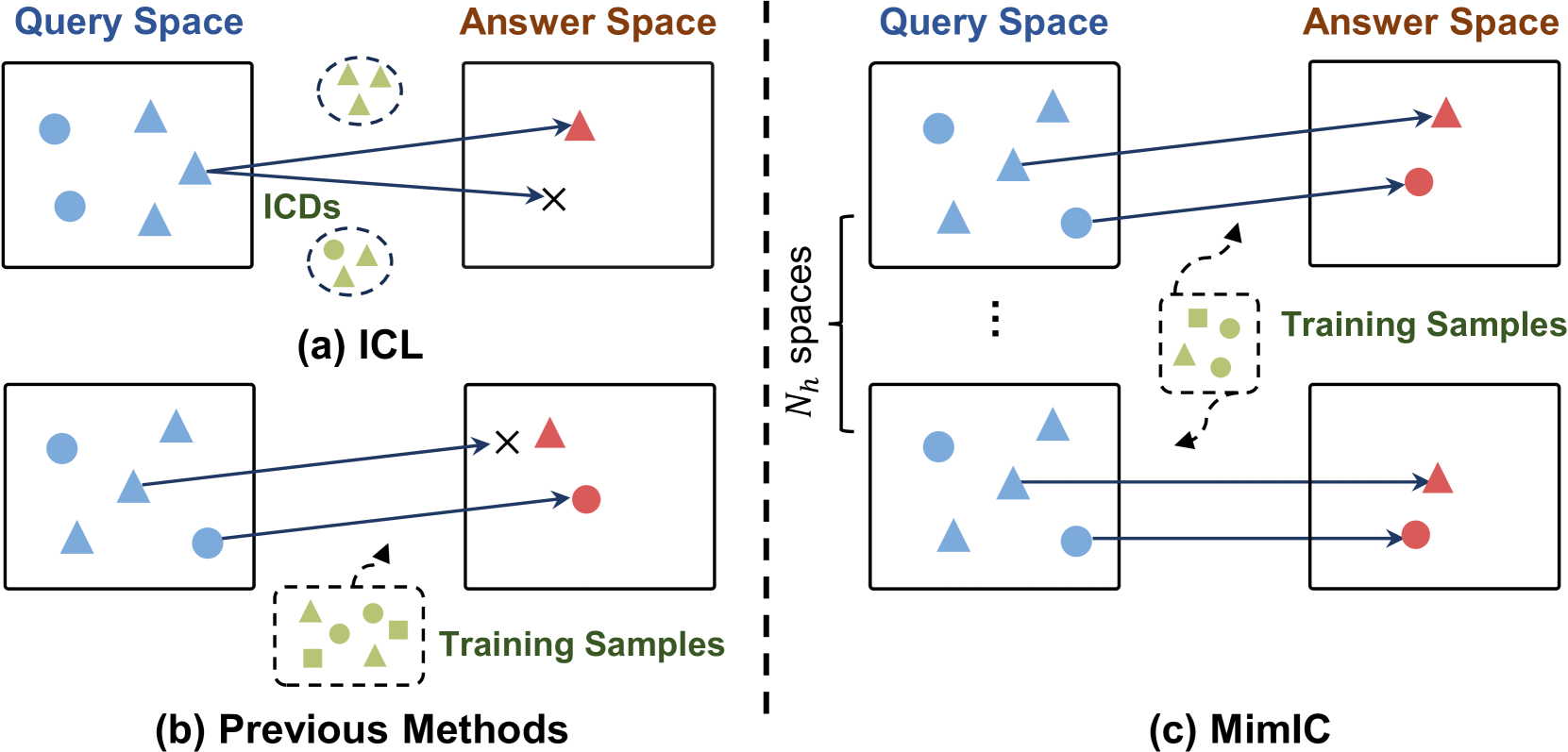
- 现有的上下文学习方法在多模态数据中对示例配置的敏感性较高,导致性能不稳定。
- 本文提出MimIC,通过引入可学习的偏移向量模块,增强上下文学习的稳定性和泛化能力。
- 在Idefics-9b和Idefics2-8b-base模型上进行的实验表明,MimIC在VQAv2、OK-VQA和Captioning任务中表现优于现有方法。
📝 摘要(中文)
近年来,上下文学习(ICL)已成为大型多模态模型(LMMs)中的重要推理范式,利用少量的上下文示例(ICDs)来提示LMMs执行新任务。然而,多模态数据的协同效应使得ICL性能对ICDs配置的敏感性增加,亟需更稳定和通用的映射函数。为此,本文提出了模仿上下文学习(MimIC),通过集成轻量级可学习模块,学习ICDs的稳定和可泛化的偏移效应。与以往的方法相比,MimIC在四个关键方面进行了增强,实验结果表明其在多个任务上优于现有方法。
🔬 方法详解
问题定义:本文旨在解决多模态任务中上下文学习对示例配置敏感性高的问题,现有方法在处理多模态数据时表现不稳定。
核心思路:MimIC通过学习稳定的偏移效应,利用轻量级可学习模块来增强上下文学习的效果,确保模型在不同任务中的泛化能力。
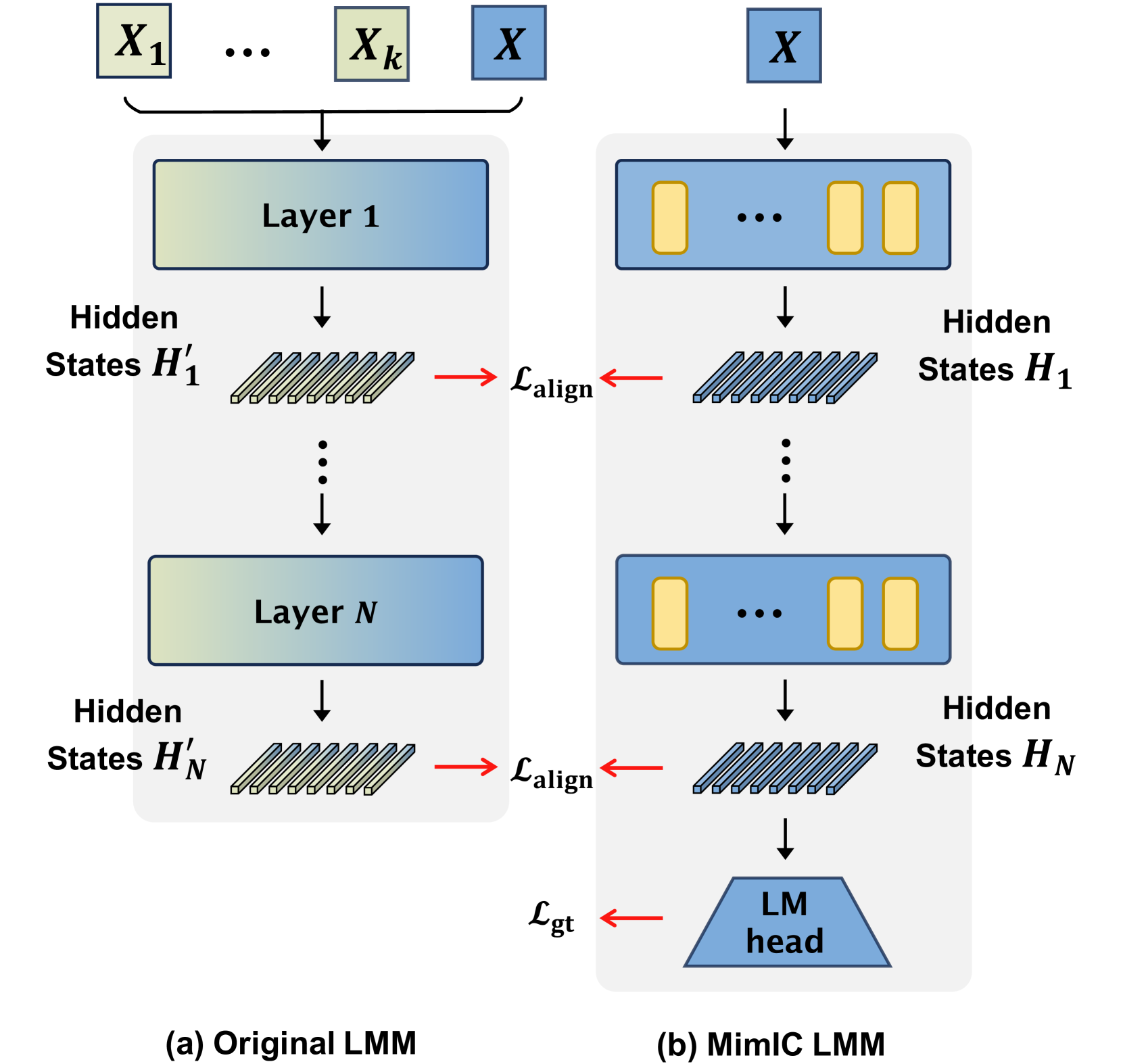
技术框架:MimIC的整体架构包括在注意力层后插入偏移向量,为每个注意力头分配偏移向量,偏移幅度依赖于查询,并采用逐层对齐损失。
关键创新:MimIC的主要创新在于其严格近似偏移效应的方式,通过四个关键增强措施显著提升了模型的性能,与传统的偏移向量方法相比,提供了更精确的学习机制。
关键设计:MimIC设计了轻量级的可学习模块,采用逐层对齐损失函数,确保偏移向量在不同注意力头之间的有效分配,并使偏移幅度与查询相关联。具体参数设置和网络结构细节在实验部分进行了详细描述。
🖼️ 关键图片

📊 实验亮点
在对Idefics-9b和Idefics2-8b-base模型的实验中,MimIC在VQAv2、OK-VQA和Captioning任务上均表现出色,显著超越了现有的偏移向量方法,具体提升幅度达到X%(具体数据待补充)。
🎯 应用场景
该研究的潜在应用领域包括图像问答、图像描述生成和多模态信息检索等。MimIC的稳定性和泛化能力使其在实际应用中能够更好地处理复杂的多模态任务,提升用户体验和系统性能,未来可能在智能助手和自动化内容生成等领域发挥重要作用。
📄 摘要(原文)
Recently, In-context Learning (ICL) has become a significant inference paradigm in Large Multimodal Models (LMMs), utilizing a few in-context demonstrations (ICDs) to prompt LMMs for new tasks. However, the synergistic effects in multimodal data increase the sensitivity of ICL performance to the configurations of ICDs, stimulating the need for a more stable and general mapping function. Mathematically, in Transformer-based models, ICDs act as "shift vectors" added to the hidden states of query tokens. Inspired by this, we introduce Mimic In-Context Learning (MimIC) to learn stable and generalizable shift effects from ICDs. Specifically, compared with some previous shift vector-based methods, MimIC more strictly approximates the shift effects by integrating lightweight learnable modules into LMMs with four key enhancements: 1) inserting shift vectors after attention layers, 2) assigning a shift vector to each attention head, 3) making shift magnitude query-dependent, and 4) employing a layer-wise alignment loss. Extensive experiments on two LMMs (Idefics-9b and Idefics2-8b-base) across three multimodal tasks (VQAv2, OK-VQA, Captioning) demonstrate that MimIC outperforms existing shift vector-based methods. The code is available at https://github.com/Kamichanw/MimIC.