Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash
作者: Fucheng Jia, Zewen Wu, Shiqi Jiang, Huiqiang Jiang, Qianxi Zhang, Yuqing Yang, Yunxin Liu, Ju Ren, Deyu Zhang, Ting Cao
分类: cs.LG
发布日期: 2025-04-11 (更新: 2025-09-23)
💡 一句话要点
ActiveFlow:通过DRAM与Flash间主动权重交换,扩展端侧LLM部署规模
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端侧部署 大语言模型 DRAM-Flash交换 权重稀疏化 自蒸馏 内存优化 移动设备
📋 核心要点
- 现有移动设备上部署LLM受限于DRAM容量,限制了可部署模型的大小。
- ActiveFlow通过主动权重DRAM-Flash交换,动态管理内存,实现计算与数据加载重叠,并进行稀疏感知自蒸馏。
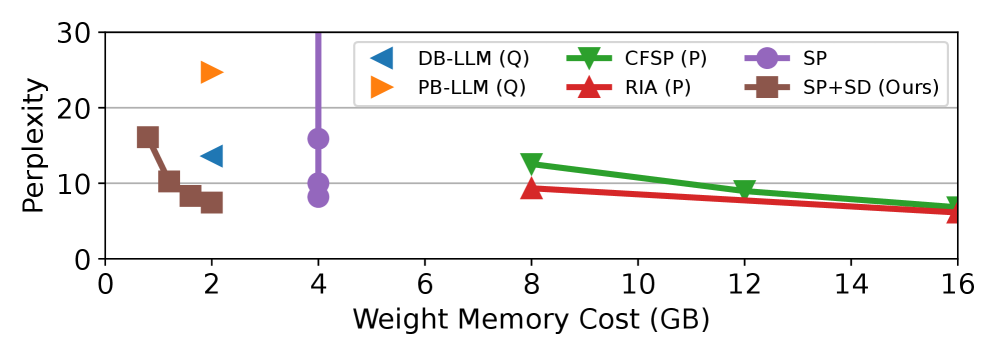
- 实验表明,ActiveFlow在性能和成本之间取得了更好的平衡,优于现有优化方法。
📝 摘要(中文)
本文提出ActiveFlow,这是一个LLM推理框架,旨在为现代LLM实现自适应DRAM使用,从而扩展可部署的模型规模。ActiveFlow基于主动权重DRAM-Flash交换的新概念,并包含三个关键技术:(1) 跨层主动权重预加载,利用当前层的激活预测后续层的活跃权重,实现计算与数据加载的重叠,并促进大数据I/O传输。(2) 稀疏感知自蒸馏,调整活跃权重以对齐密集模型输出分布,补偿上下文稀疏性引入的近似。(3) 主动权重DRAM-Flash交换流水线,基于可用内存,协调热权重缓存、预加载的活跃权重和计算相关权重之间的DRAM空间分配。实验结果表明,与现有的效率优化方法相比,ActiveFlow实现了性能-成本的帕累托最优。
🔬 方法详解
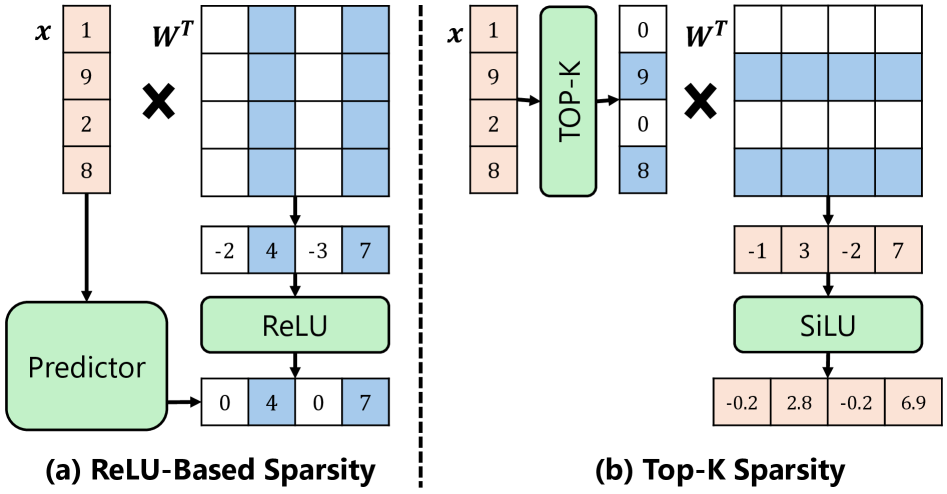
问题定义:论文旨在解决在移动设备等资源受限的边缘设备上部署大型语言模型(LLM)时,由于DRAM容量不足而导致的模型规模受限问题。现有方法通常采用模型压缩、量化等技术,但这些方法可能会牺牲模型精度。此外,传统的DRAM-Flash数据交换策略无法有效利用LLM的特性,导致性能瓶颈。
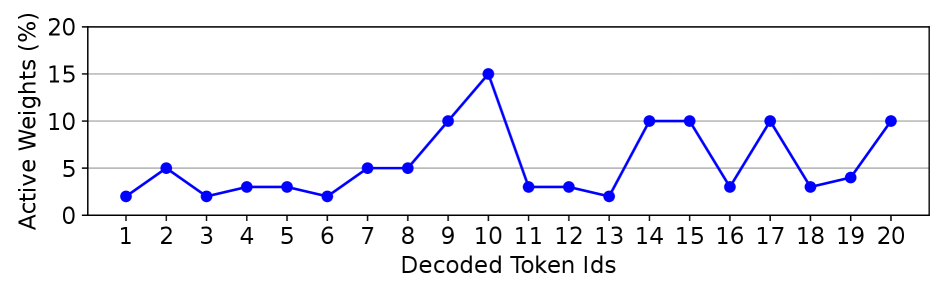
核心思路:ActiveFlow的核心思路是利用LLM中权重激活的稀疏性,只将活跃的权重加载到DRAM中进行计算,而将不活跃的权重存储在Flash中。通过预测未来层的活跃权重并提前加载,实现计算和数据加载的重叠,从而提高推理效率。同时,采用稀疏感知自蒸馏来补偿由于权重稀疏化带来的精度损失。
技术框架:ActiveFlow框架主要包含三个阶段:(1) 跨层主动权重预加载:利用当前层的激活值预测后续几层的活跃权重,并将这些权重从Flash预加载到DRAM。(2) 稀疏感知自蒸馏:通过调整活跃权重,使其输出分布尽可能接近原始密集模型的输出分布,从而弥补稀疏化带来的精度损失。(3) 主动权重DRAM-Flash交换流水线:根据当前可用DRAM空间,动态地在热权重缓存、预加载的活跃权重和计算所需的权重之间分配DRAM空间。
关键创新:ActiveFlow的关键创新在于:(1) 提出了一种基于激活值的跨层活跃权重预测方法,能够有效地预测未来层的活跃权重。(2) 引入了稀疏感知自蒸馏技术,能够在保持模型精度的同时,有效地减少计算量。(3) 设计了一种动态的DRAM-Flash交换流水线,能够根据当前可用内存,灵活地管理DRAM空间。与现有方法相比,ActiveFlow能够更好地利用LLM的特性,从而在资源受限的设备上部署更大规模的模型。
关键设计:在跨层主动权重预加载中,使用激活值预测活跃权重的方法是关键。具体实现可能涉及训练一个小型预测模型,该模型以当前层的激活值为输入,预测后续层的活跃权重。稀疏感知自蒸馏的目标函数设计需要仔细考虑,以平衡模型精度和计算复杂度。DRAM-Flash交换流水线的调度策略也需要根据具体的硬件平台和模型结构进行优化。
🖼️ 关键图片
📊 实验亮点
论文实验结果表明,ActiveFlow在端侧设备上部署LLM时,能够在保证模型精度的前提下,显著提升推理速度并降低内存占用。与现有优化方法相比,ActiveFlow在性能和成本之间取得了更好的平衡,实现了性能-成本的帕累托最优。具体的性能提升数据和对比基线需要在论文中查找。
🎯 应用场景
ActiveFlow技术可广泛应用于移动设备、嵌入式系统和边缘服务器等资源受限的场景,使得这些设备能够运行更大规模、更复杂的LLM。这将在智能助手、自然语言处理、机器翻译等领域带来更强大的功能和更好的用户体验。此外,该技术还可以降低LLM的部署成本,加速LLM在各行业的普及。
📄 摘要(原文)
Large language models (LLMs) are increasingly being deployed on mobile devices, but the limited DRAM capacity constrains the deployable model size. This paper introduces ActiveFlow, the first LLM inference framework that can achieve adaptive DRAM usage for modern LLMs (not ReLU-based), enabling the scaling up of deployable model sizes. The framework is based on the novel concept of active weight DRAM-flash swapping and incorporates three novel techniques: (1) Cross-layer active weights preloading. It uses the activations from the current layer to predict the active weights of several subsequent layers, enabling computation and data loading to overlap, as well as facilitating large I/O transfers. (2) Sparsity-aware self-distillation. It adjusts the active weights to align with the dense-model output distribution, compensating for approximations introduced by contextual sparsity. (3) Active weight DRAM-flash swapping pipeline. It orchestrates the DRAM space allocation among the hot weight cache, preloaded active weights, and computation-involved weights based on available memory. Results show ActiveFlow achieves the performance-cost Pareto frontier compared to existing efficiency optimization methods.