VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
作者: Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, Wenhu Chen
分类: cs.LG, cs.AI
发布日期: 2025-04-10 (更新: 2025-05-08)
备注: Preprint
💡 一句话要点
VL-Rethinker:利用强化学习激励视觉语言模型进行自我反思,提升复杂推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 强化学习 自我反思 复杂推理 选择性样本回放
📋 核心要点
- 现有视觉语言模型在复杂推理任务中,慢思考能力不足,限制了其性能,尤其是在需要深度反思的场景下。
- 论文提出VL-Rethinker,通过强化学习,结合选择性样本回放和强制反思机制,激励模型进行自我反思,提升推理能力。
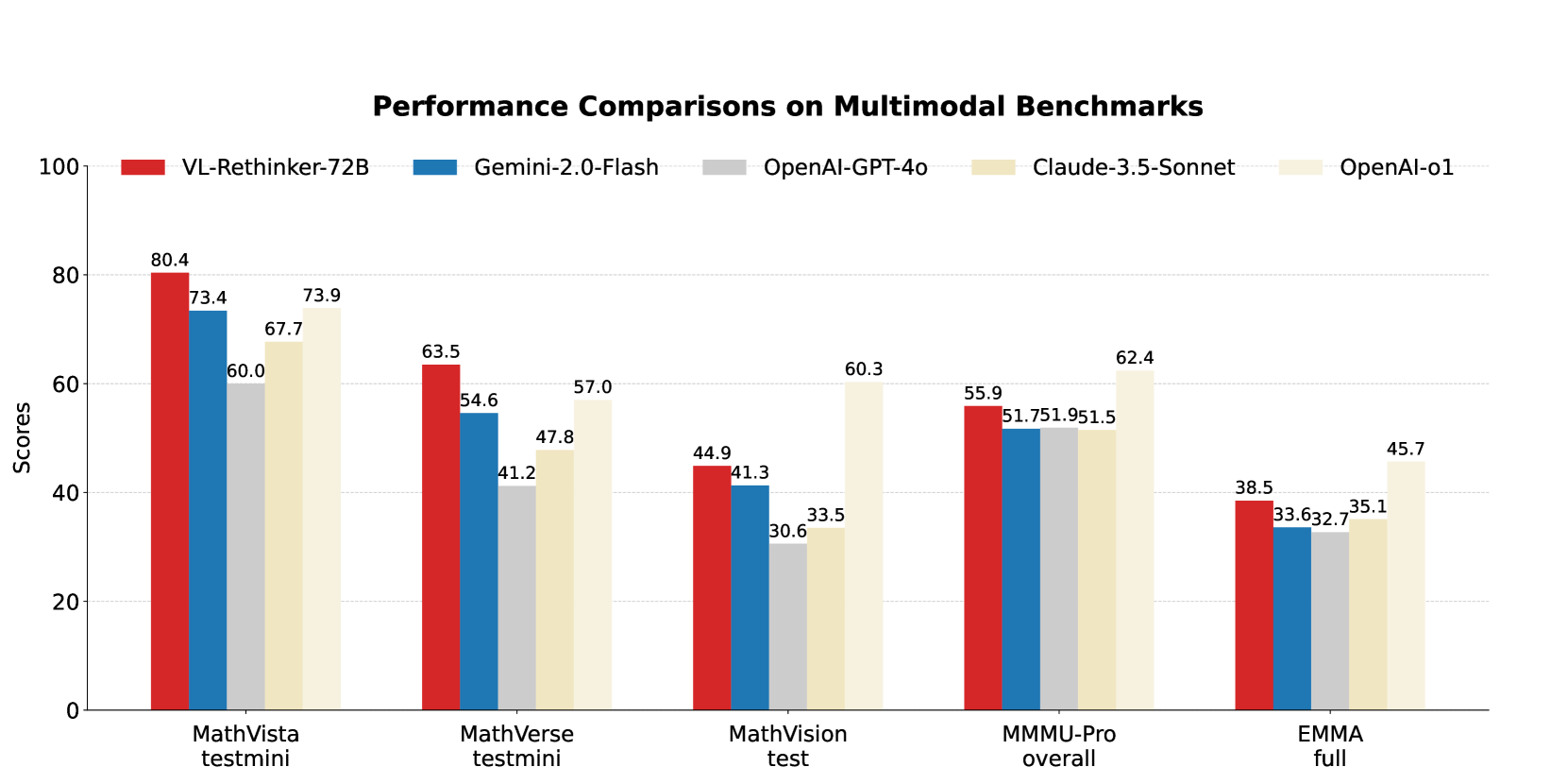
- 实验表明,VL-Rethinker在多个基准测试中取得了显著的性能提升,包括MathVista和MathVerse等,并缩小了与闭源模型的差距。
📝 摘要(中文)
本文旨在通过强化学习提升视觉语言模型的慢思考能力,从而推进技术水平,无需依赖知识蒸馏。首先,作者改进了GRPO算法,提出选择性样本回放(SSR)技术,以解决优势消失问题。虽然该方法表现良好,但训练后的RL模型自我反思或自我验证能力有限。为了进一步鼓励慢思考,作者引入了强制反思(Forced Rethinking),在RL训练中,在rollout结束时附加一个反思触发token,显式地强制执行自我反思推理步骤。通过结合这两种技术,模型VL-Rethinker在MathVista和MathVerse上分别实现了80.4%和63.5%的state-of-the-art分数。VL-Rethinker还在MathVision、MMMU-Pro、EMMA和MEGA-Bench等多学科基准测试中实现了开源SoTA,缩小了与OpenAI-o1的差距。实验结果表明了该方法的有效性。
🔬 方法详解
问题定义:现有视觉语言模型,即使是大型模型,在需要复杂推理和多步思考的任务上,性能仍然受限。它们通常采用“快思考”模式,缺乏像人类一样的自我反思和验证能力,导致在需要深度推理的视觉语言任务中表现不佳。现有方法要么依赖于昂贵的知识蒸馏,要么无法有效激励模型进行自我反思。
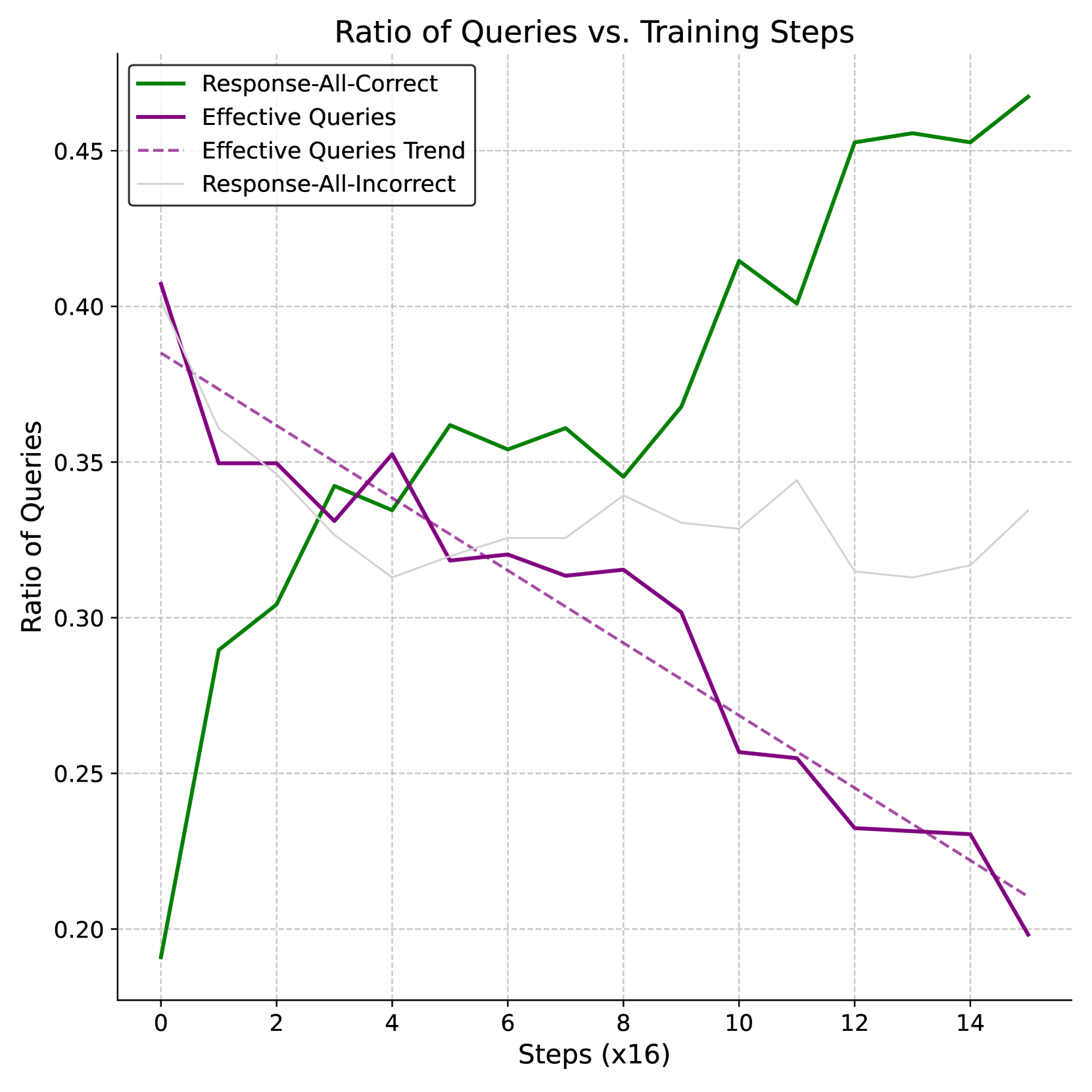
核心思路:论文的核心思路是通过强化学习,显式地激励视觉语言模型进行自我反思。具体来说,通过引入“强制反思”机制,迫使模型在完成推理过程后,进行额外的反思步骤,从而提高其推理的准确性和可靠性。同时,使用选择性样本回放来稳定强化学习训练。
技术框架:VL-Rethinker的训练框架基于强化学习。首先,使用GRPO算法进行初步训练,并引入选择性样本回放(SSR)来解决优势消失问题。然后,在rollout的末尾添加一个特殊的“反思触发token”,强制模型进行自我反思。整个训练过程旨在优化模型的推理策略,使其能够更好地利用自我反思来提高性能。
关键创新:论文的关键创新在于“强制反思”机制,它通过在强化学习训练中显式地添加反思步骤,有效地激励了模型进行自我反思。与以往方法相比,该方法不需要依赖知识蒸馏,并且能够更直接地提升模型的推理能力。选择性样本回放(SSR)也是一个创新点,它解决了强化学习训练中常见的优势消失问题。
关键设计:在强化学习训练中,奖励函数的设计至关重要。论文中奖励函数可能结合了任务完成的准确率以及反思步骤的质量。具体参数设置未知。强制反思token的选择以及其在模型中的嵌入方式也是关键设计。选择性样本回放的具体实现方式,例如选择哪些样本进行回放,以及回放的频率,也会影响训练效果。具体细节未知。
🖼️ 关键图片

📊 实验亮点
VL-Rethinker在MathVista上取得了80.4%的state-of-the-art分数,在MathVerse上取得了63.5%的state-of-the-art分数。此外,该模型还在MathVision、MMMU-Pro、EMMA和MEGA-Bench等多学科基准测试中实现了开源SoTA,缩小了与OpenAI-o1的差距。这些实验结果表明,VL-Rethinker在复杂推理任务中具有显著的优势。
🎯 应用场景
VL-Rethinker的研究成果可应用于需要复杂推理和多步思考的视觉语言任务,例如视觉问答、图像理解、机器人导航等。该方法可以提高机器人在复杂环境中的决策能力,并提升视觉语言模型在教育、医疗等领域的应用效果。未来,该技术有望推动通用人工智能的发展,使机器能够更好地理解和解决现实世界中的复杂问题。
📄 摘要(原文)
Recently, slow-thinking systems like GPT-o1 and DeepSeek-R1 have demonstrated great potential in solving challenging problems through explicit reflection. They significantly outperform the best fast-thinking models, such as GPT-4o, on various math and science benchmarks. However, their multimodal reasoning capabilities remain on par with fast-thinking models. For instance, GPT-o1's performance on benchmarks like MathVista, MathVerse, and MathVision is similar to fast-thinking models. In this paper, we aim to enhance the slow-thinking capabilities of vision-language models using reinforcement learning (without relying on distillation) to advance the state of the art. First, we adapt the GRPO algorithm with a novel technique called Selective Sample Replay (SSR) to address the vanishing advantages problem. While this approach yields strong performance, the resulting RL-trained models exhibit limited self-reflection or self-verification. To further encourage slow-thinking, we introduce Forced Rethinking, which appends a rethinking trigger token to the end of rollouts in RL training, explicitly enforcing a self-reflection reasoning step. By combining these two techniques, our model, VL-Rethinker, advances state-of-the-art scores on MathVista, MathVerse to achieve 80.4%, 63.5% respectively. VL-Rethinker also achieves open-source SoTA on multi-disciplinary benchmarks such as MathVision, MMMU-Pro, EMMA, and MEGA-Bench, narrowing the gap with OpenAI-o1. Our empirical results show the effectiveness of our approaches.