Rethinking the Foundations for Continual Reinforcement Learning
作者: Esraa Elelimy, David Szepesvari, Martha White, Michael Bowling
分类: cs.LG, cs.AI
发布日期: 2025-04-10 (更新: 2025-07-15)
期刊: RLDM, 2025. RLC,2025
💡 一句话要点
重新审视持续强化学习的基础理论,提出基于历史过程的新形式化框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 持续强化学习 历史过程 偏差后悔 马尔可夫决策过程 强化学习 非马尔可夫性
📋 核心要点
- 传统强化学习的MDP形式、非时序性关注、期望累积奖励和片段式环境,限制了其在持续学习中的应用。
- 论文提出基于历史过程的新形式化框架,并采用偏差后悔作为持续学习的评估指标,以克服传统方法的局限性。
- 论文主要集中在理论框架的构建,实验验证部分相对较少,未来工作将探索新框架下的具体算法和性能表现。
📝 摘要(中文)
传统的强化学习旨在寻找最大化期望累积奖励的最优策略,并在找到该策略后结束学习。这与持续强化学习形成对比,后者学习永不停止,智能体需要不断学习和适应。尽管这两种学习范式存在明显区别,但持续强化学习的许多进展都受到传统强化学习基础理论的影响。本文首先考察了传统强化学习的基础是否适用于持续强化学习范式。我们确定了传统强化学习基础的四个关键支柱与持续学习的目标背道而驰:马尔可夫决策过程形式、对非时序性因素的关注、期望累积奖励作为评估指标,以及包含上述三个基础的片段式基准环境。然后,我们提出了一种新的形式化框架,摒弃了第一个和第三个基础,并用历史过程作为数学形式和一种新的、为持续学习而调整的偏差后悔定义作为评估指标来代替它们。最后,我们讨论了摆脱其他两个基础的可能方法。
🔬 方法详解
问题定义:传统强化学习理论,特别是基于马尔可夫决策过程(MDP)的形式化,在持续强化学习(CRL)中存在局限性。MDP假设环境是马尔可夫的,即当前状态包含了做出最优决策所需的所有信息,这在动态变化的持续学习环境中通常不成立。此外,传统强化学习侧重于寻找一个最优策略,而忽略了智能体在学习过程中所经历的后悔值。
核心思路:论文的核心思路是抛弃传统的MDP框架,转而采用“历史过程”作为描述环境和智能体交互的数学工具。历史过程包含了智能体过去所有的观测、动作和奖励信息,能够更全面地反映环境的动态变化。同时,论文引入了“偏差后悔”作为评估指标,用于衡量智能体在持续学习过程中与最优策略之间的偏差。
技术框架:论文提出的技术框架主要包含以下几个部分:1) 使用历史过程代替MDP来描述环境;2) 定义了基于历史过程的策略和价值函数;3) 提出了偏差后悔的概念,并给出了其数学定义。整体框架旨在为持续强化学习提供一个更合适的理论基础,从而促进相关算法的研究和发展。
关键创新:最重要的技术创新点在于使用历史过程来建模环境,这与传统强化学习中基于马尔可夫假设的MDP模型有着本质区别。历史过程能够捕捉环境的非马尔可夫性,从而更准确地描述持续学习环境的动态变化。此外,偏差后悔的引入也使得对持续学习算法的评估更加合理。
关键设计:论文中并没有涉及具体的算法设计,而是侧重于理论框架的构建。关键的设计在于如何定义历史过程、策略和价值函数,以及如何计算偏差后悔。这些定义需要满足一定的数学性质,例如可计算性和可优化性,以便后续算法的设计和分析。
🖼️ 关键图片
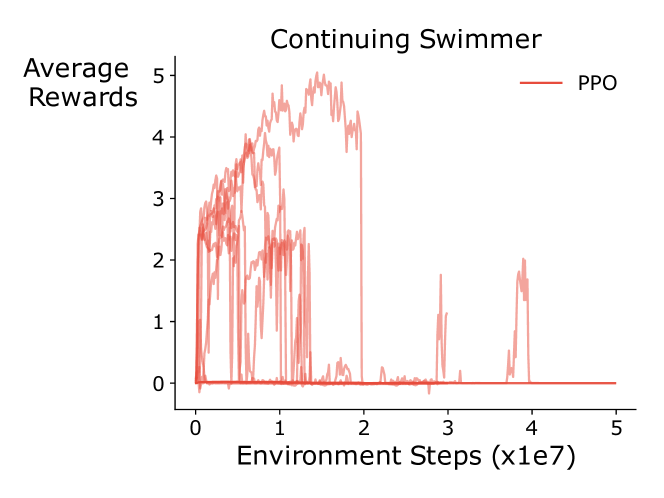
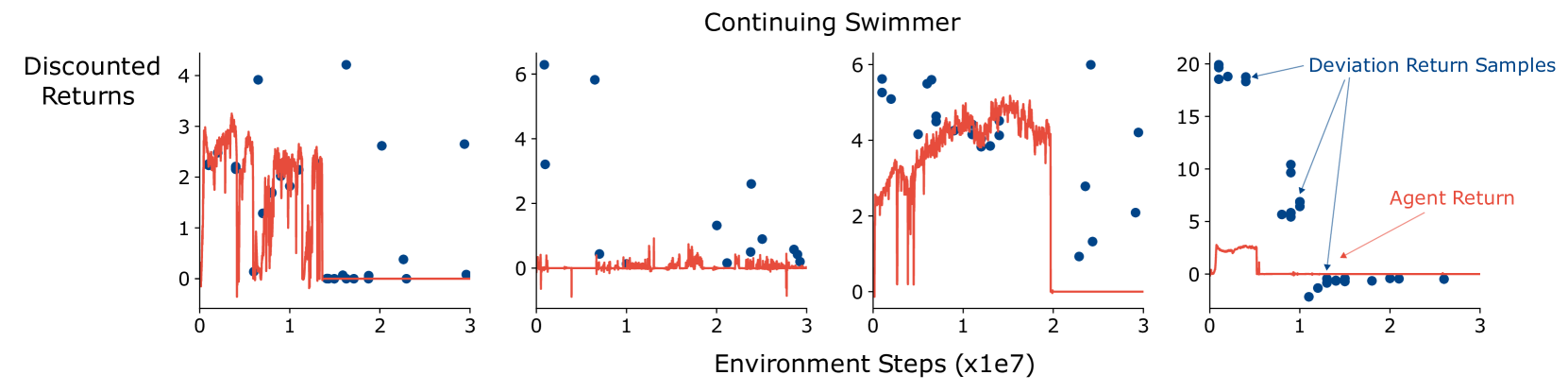
📊 实验亮点
论文的主要贡献在于提出了一个新的持续强化学习形式化框架,该框架基于历史过程和偏差后悔,旨在克服传统强化学习理论在持续学习中的局限性。虽然论文没有提供具体的实验结果,但其理论框架为后续研究提供了新的方向。
🎯 应用场景
该研究成果为持续强化学习提供了一个新的理论基础,有助于开发更适应动态变化环境的智能体。潜在应用领域包括机器人自主导航、智能交通系统、金融交易等,这些领域都需要智能体能够不断学习和适应新的环境。
📄 摘要(原文)
In the traditional view of reinforcement learning, the agent's goal is to find an optimal policy that maximizes its expected sum of rewards. Once the agent finds this policy, the learning ends. This view contrasts with \emph{continual reinforcement learning}, where learning does not end, and agents are expected to continually learn and adapt indefinitely. Despite the clear distinction between these two paradigms of learning, much of the progress in continual reinforcement learning has been shaped by foundations rooted in the traditional view of reinforcement learning. In this paper, we first examine whether the foundations of traditional reinforcement learning are suitable for the continual reinforcement learning paradigm. We identify four key pillars of the traditional reinforcement learning foundations that are antithetical to the goals of continual learning: the Markov decision process formalism, the focus on atemporal artifacts, the expected sum of rewards as an evaluation metric, and episodic benchmark environments that embrace the other three foundations. We then propose a new formalism that sheds the first and the third foundations and replaces them with the history process as a mathematical formalism and a new definition of deviation regret, adapted for continual learning, as an evaluation metric. Finally, we discuss possible approaches to shed the other two foundations.