C3PO: Critical-Layer, Core-Expert, Collaborative Pathway Optimization for Test-Time Expert Re-Mixing
作者: Zhongyang Li, Ziyue Li, Tianyi Zhou
分类: cs.LG
发布日期: 2025-04-10
💡 一句话要点
提出C3PO以解决MoE模型测试时专家路径优化问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家 测试时优化 路径优化 大规模语言模型 机器学习 自然语言处理 模型效率
📋 核心要点
- 现有的混合专家模型在测试时的专家路径选择存在显著的准确率损失,导致性能未能达到预期。
- 论文提出了一种新的测试时优化方法,通过对不同层次的专家进行重加权,适应每个测试样本的需求。
- C3PO在六个基准测试中表现出7-15%的准确率提升,且在参数效率上超越了更大规模的模型。
📝 摘要(中文)
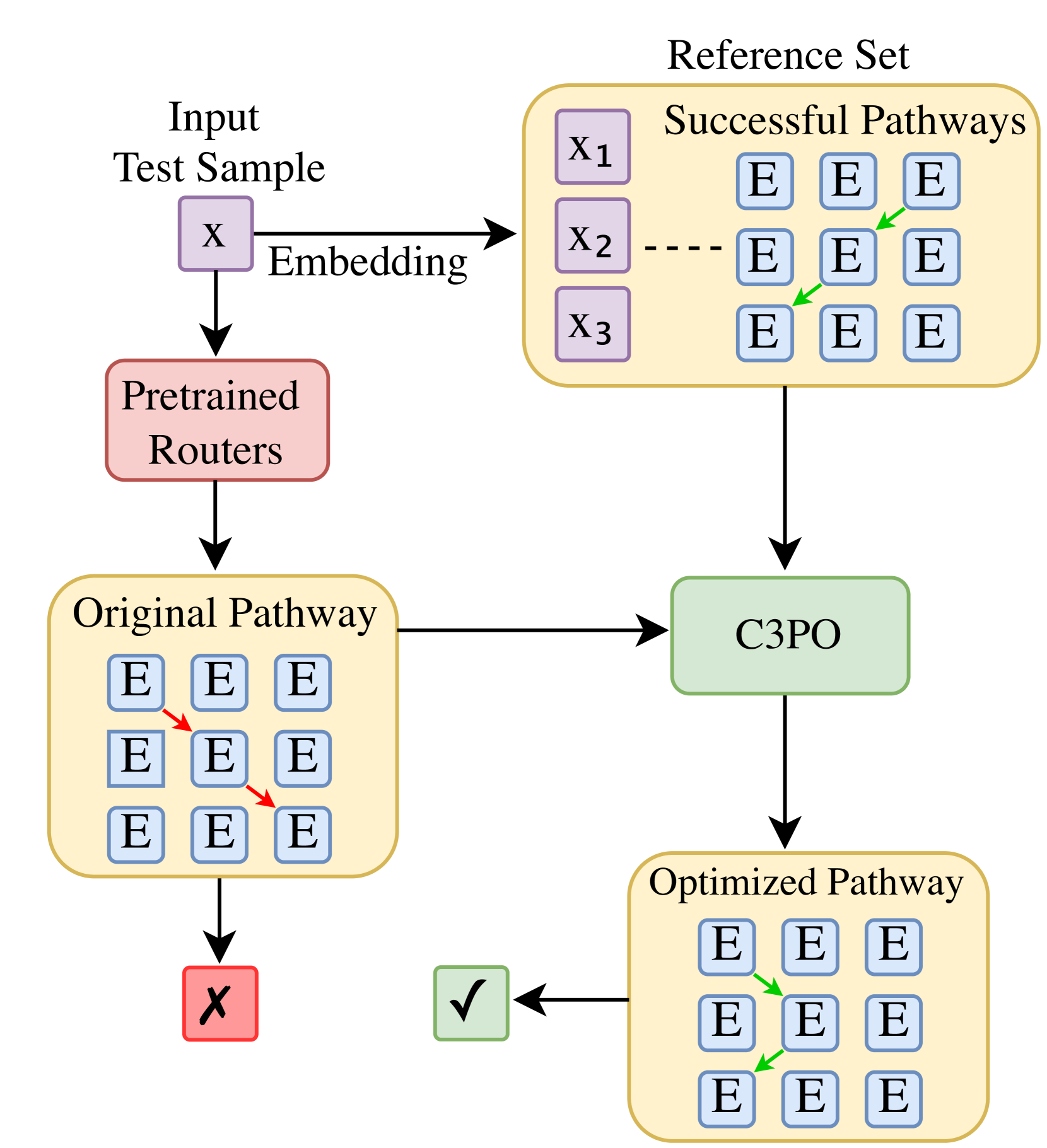
混合专家(MoE)的大型语言模型(LLM)在专家路径选择上存在显著的子最优问题,我们的研究发现,基于预训练的简单专家选择方法导致了10-20%的准确率差距。为此,我们开发了一种新型的测试时优化方法,通过对不同层次的专家进行重加权或“重混合”,以适应每个测试样本。由于测试样本的真实标签未知,我们提出了基于“成功邻居”的替代目标进行优化。我们引入了三种替代目标和相应算法,基于模式寻找、核回归和相似参考样本的平均损失。通过仅优化关键层次中核心专家的混合权重,我们提出了“关键层次、核心专家、协作路径优化(C3PO)”。在六个广泛使用的基准测试中,C3PO在两个最新的MoE LLM上均表现出7-15%的准确率提升,显著超越了常用的测试时学习基线。
🔬 方法详解
问题定义:本论文旨在解决混合专家(MoE)模型在测试时专家路径选择的子最优问题。现有方法基于预训练的简单专家选择,导致10-20%的准确率差距,影响模型性能。
核心思路:我们提出了一种新的测试时优化方法,称为C3PO,通过对不同层次的专家进行重加权或“重混合”,以适应每个测试样本的特征。此方法利用样本的“成功邻居”来定义替代目标,从而在缺乏真实标签的情况下进行优化。
技术框架:C3PO的整体架构包括三个主要模块:首先,识别测试样本的“成功邻居”;其次,基于这些邻居定义替代目标;最后,优化关键层次中核心专家的混合权重,以实现高效的路径优化。
关键创新:C3PO的主要创新在于通过优化关键层次的核心专家混合权重,显著减少了计算成本,同时保持了与全路径优化相似的性能。这一方法与传统的全路径优化方法本质上不同,提供了更高的效率。
关键设计:在设计中,我们引入了三种替代目标,分别基于模式寻找、核回归和相似参考样本的平均损失。这些设计使得优化过程更加灵活且高效,同时确保了模型的准确性。我们还进行了全面的消融研究,以验证各个组件的有效性。
🖼️ 关键图片


📊 实验亮点
C3PO在六个基准测试中实现了7-15%的准确率提升,显著超越了传统的测试时学习基线,如上下文学习和提示调优。此外,C3PO使得拥有1-3B参数的MoE模型在性能上超越了7-9B参数的模型,展示了其在效率上的优势。
🎯 应用场景
C3PO的研究成果在多个领域具有潜在应用价值,尤其是在需要高效推理的自然语言处理任务中。通过优化专家路径,C3PO能够在资源受限的环境中提升模型性能,适用于实时翻译、对话系统等场景。未来,该方法可能推动更高效的模型设计和应用,进一步提升人工智能系统的智能水平。
📄 摘要(原文)
Mixture-of-Experts (MoE) Large Language Models (LLMs) suffer from severely sub-optimal expert pathways-our study reveals that naive expert selection learned from pretraining leaves a surprising 10-20% accuracy gap for improvement. Motivated by this observation, we develop a novel class of test-time optimization methods to re-weight or "re-mixing" the experts in different layers jointly for each test sample. Since the test sample's ground truth is unknown, we propose to optimize a surrogate objective defined by the sample's "successful neighbors" from a reference set of samples. We introduce three surrogates and algorithms based on mode-finding, kernel regression, and the average loss of similar reference samples/tasks. To reduce the cost of optimizing whole pathways, we apply our algorithms merely to the core experts' mixing weights in critical layers, which enjoy similar performance but save significant computation. This leads to "Critical-Layer, Core-Expert, Collaborative Pathway Optimization (C3PO)". We apply C3PO to two recent MoE LLMs and examine it on six widely-used benchmarks. It consistently improves the base model by 7-15% in accuracy and outperforms widely used test-time learning baselines, e.g., in-context learning and prompt/prefix tuning, by a large margin. Moreover, C3PO enables MoE LLMs with 1-3B active parameters to outperform LLMs of 7-9B parameters, hence improving MoE's advantages on efficiency. Our thorough ablation study further sheds novel insights on achieving test-time improvement on MoE.