Distilling Knowledge from Heterogeneous Architectures for Semantic Segmentation
作者: Yanglin Huang, Kai Hu, Yuan Zhang, Zhineng Chen, Xieping Gao
分类: cs.LG, cs.CV
发布日期: 2025-04-10
备注: Accepted to AAAI 2025
💡 一句话要点
提出HeteroAKD,用于异构架构语义分割知识蒸馏,提升学生模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 语义分割 异构架构 模型压缩 深度学习
📋 核心要点
- 现有语义分割知识蒸馏方法忽略了异构架构间蕴含的丰富知识,限制了学生模型对数据的理解。
- HeteroAKD将异构架构的中间特征投影到对齐的logits空间,消除架构差异带来的影响。
- 通过师生知识混合与评估机制,HeteroAKD能够选择性地传递对学生模型有益的知识。
📝 摘要(中文)
现有的语义分割知识蒸馏(KD)方法主要集中在同构架构内指导学生模仿教师的知识。然而,这些方法忽略了具有不同归纳偏置的架构所包含的多样化知识,这对于使学生在蒸馏过程中获得更精确和全面的数据理解至关重要。为此,我们首次提出了一种通用的异构视角下的语义分割知识蒸馏方法,名为HeteroAKD。由于异构架构(如CNN和Transformer)之间存在显著差异,直接传递跨架构知识面临重大挑战。为了消除架构特定信息的影响,教师和学生的中间特征被巧妙地投影到一个对齐的logits空间中。此外,为了利用来自异构架构的多样化知识,并传递学生所需的定制知识,引入了一种师生知识混合机制(KMM)和一种师生知识评估机制(KEM)。这些机制通过评估异构师生知识之间的可靠性及其差异来实现。在三个主流基准上使用各种师生对进行的大量实验表明,我们的HeteroAKD在促进异构架构之间的蒸馏方面优于最先进的KD方法。
🔬 方法详解
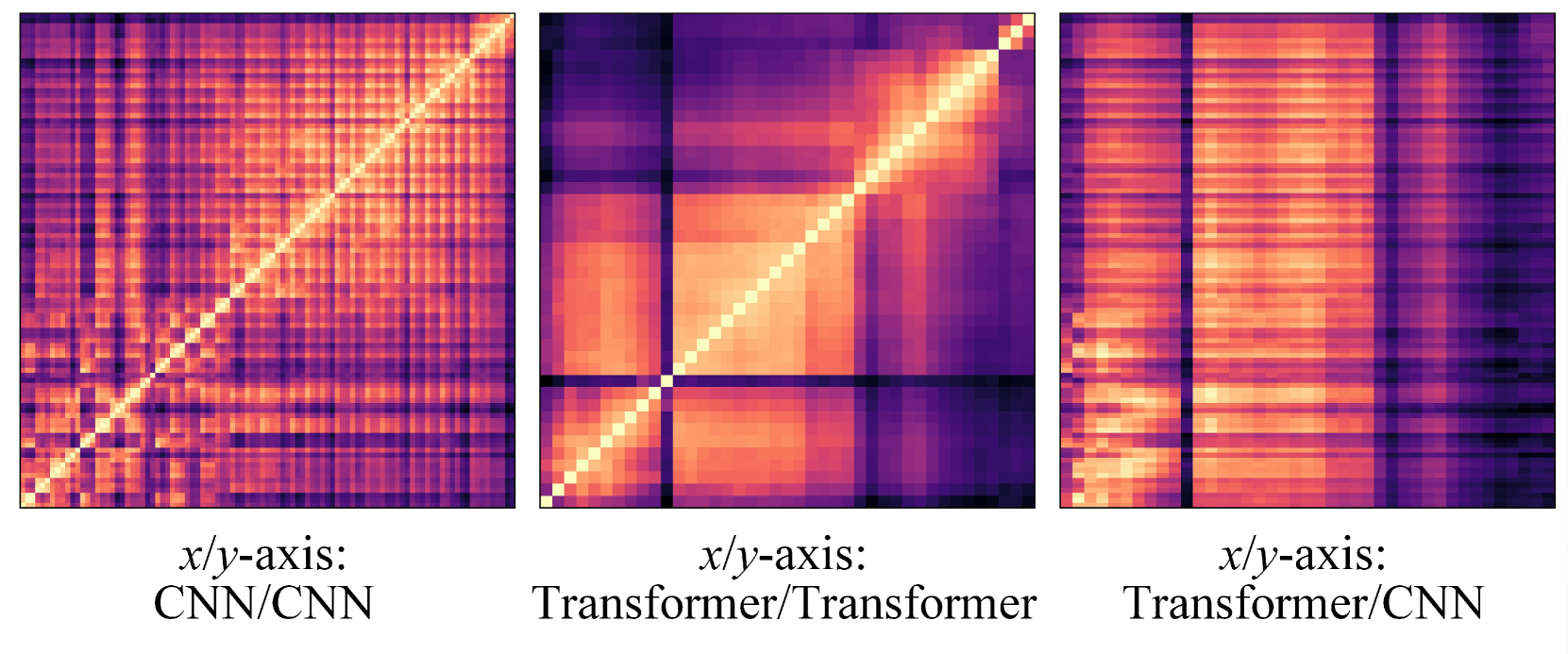
问题定义:现有的知识蒸馏方法主要关注同构架构之间的知识迁移,忽略了异构架构(例如CNN和Transformer)之间存在的知识差异。直接将CNN的知识迁移到Transformer,或者反过来,会因为架构差异导致知识传递效率低下,甚至产生负面影响。因此,如何有效地利用异构架构的知识进行蒸馏是一个亟待解决的问题。
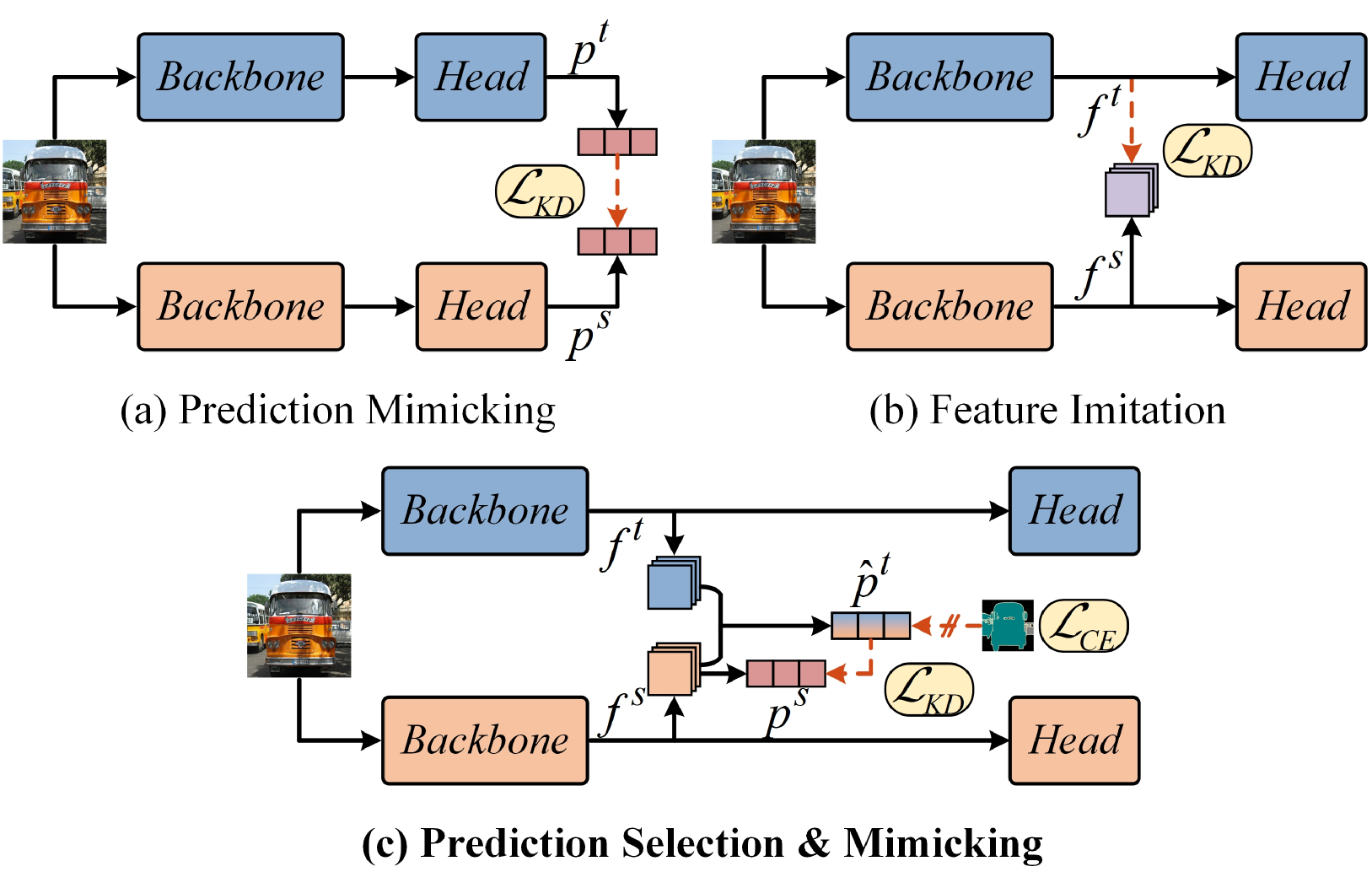
核心思路:HeteroAKD的核心思路是消除异构架构之间的差异,并将教师和学生的特征投影到一个公共的logits空间中。通过这种方式,可以避免直接比较不同架构的特征,从而更有效地进行知识迁移。此外,HeteroAKD还引入了知识混合和评估机制,用于选择性地传递对学生模型有益的知识。
技术框架:HeteroAKD主要包含以下几个模块:1) 特征投影模块:将教师和学生的中间特征投影到对齐的logits空间。2) 知识混合机制(KMM):根据教师和学生知识的可靠性,对教师的知识进行加权混合。3) 知识评估机制(KEM):评估教师和学生知识之间的差异,选择性地传递差异较大的知识。4) 损失函数:包括logits损失、特征损失和知识混合损失。
关键创新:HeteroAKD的关键创新在于:1) 首次提出了异构架构之间的知识蒸馏方法。2) 提出了特征投影模块,用于消除异构架构之间的差异。3) 提出了知识混合和评估机制,用于选择性地传递知识。与现有方法相比,HeteroAKD能够更有效地利用异构架构的知识,从而提升学生模型的性能。
关键设计:特征投影模块使用线性层将教师和学生的中间特征投影到logits空间。知识混合机制使用softmax函数计算教师和学生知识的可靠性权重。知识评估机制使用KL散度计算教师和学生知识之间的差异。损失函数包括logits损失(交叉熵损失)、特征损失(L2损失)和知识混合损失(KL散度损失)。具体参数设置需要根据不同的数据集和架构进行调整。
🖼️ 关键图片
📊 实验亮点
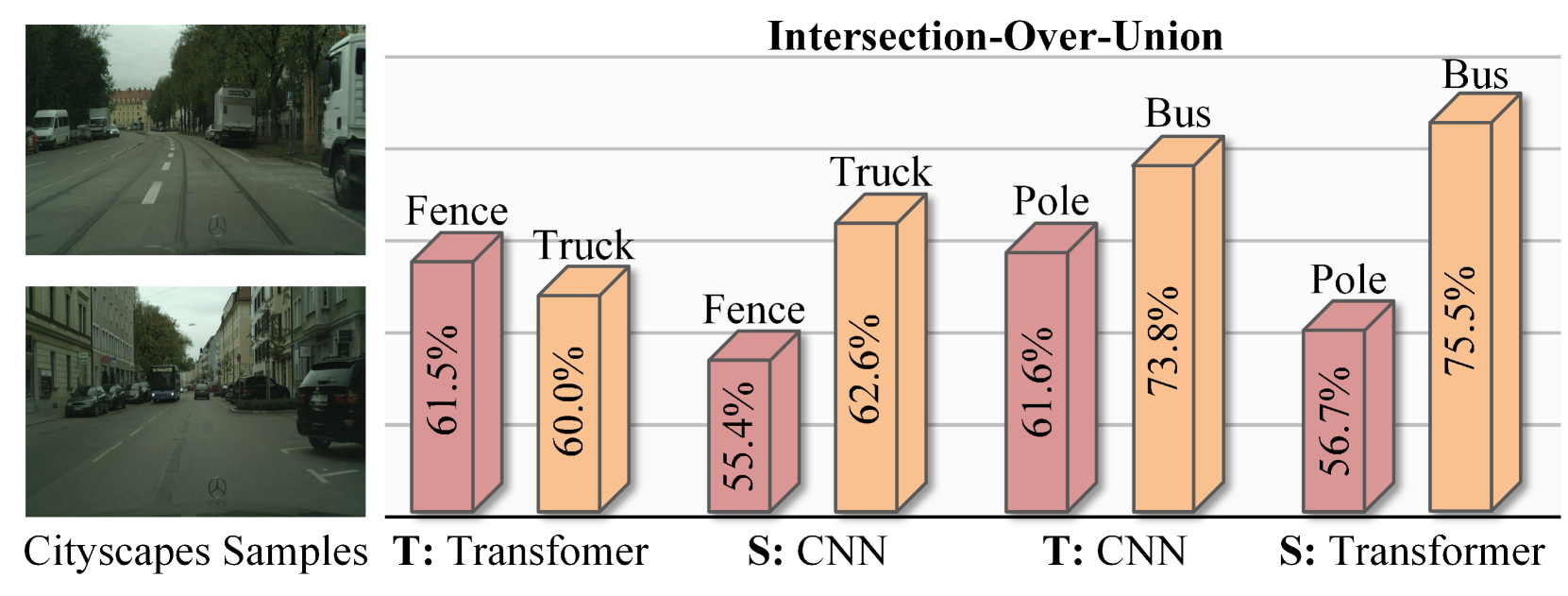
在Cityscapes、Pascal VOC和ADE20K三个主流语义分割数据集上进行了大量实验,结果表明HeteroAKD显著优于现有的知识蒸馏方法。例如,在Cityscapes数据集上,使用ResNet101作为教师模型,MobileNetV2作为学生模型,HeteroAKD相比于baseline方法提升了3.2%的mIoU。
🎯 应用场景
HeteroAKD可应用于各种需要模型轻量化和加速的语义分割场景,例如自动驾驶、机器人导航、医学图像分析等。通过将大型、高性能的教师模型知识迁移到小型、低功耗的学生模型,可以在资源受限的设备上实现高性能的语义分割,具有重要的实际应用价值和广泛的应用前景。
📄 摘要(原文)
Current knowledge distillation (KD) methods for semantic segmentation focus on guiding the student to imitate the teacher's knowledge within homogeneous architectures. However, these methods overlook the diverse knowledge contained in architectures with different inductive biases, which is crucial for enabling the student to acquire a more precise and comprehensive understanding of the data during distillation. To this end, we propose for the first time a generic knowledge distillation method for semantic segmentation from a heterogeneous perspective, named HeteroAKD. Due to the substantial disparities between heterogeneous architectures, such as CNN and Transformer, directly transferring cross-architecture knowledge presents significant challenges. To eliminate the influence of architecture-specific information, the intermediate features of both the teacher and student are skillfully projected into an aligned logits space. Furthermore, to utilize diverse knowledge from heterogeneous architectures and deliver customized knowledge required by the student, a teacher-student knowledge mixing mechanism (KMM) and a teacher-student knowledge evaluation mechanism (KEM) are introduced. These mechanisms are performed by assessing the reliability and its discrepancy between heterogeneous teacher-student knowledge. Extensive experiments conducted on three main-stream benchmarks using various teacher-student pairs demonstrate that our HeteroAKD outperforms state-of-the-art KD methods in facilitating distillation between heterogeneous architectures.