LoRI: Reducing Cross-Task Interference in Multi-Task Low-Rank Adaptation
作者: Juzheng Zhang, Jiacheng You, Ashwinee Panda, Tom Goldstein
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-04-10 (更新: 2025-08-02)
备注: COLM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出LoRI,通过随机投影和稀疏化降低多任务低秩适配中的任务间干扰。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩适配 参数高效微调 多任务学习 持续学习 随机投影 稀疏化 任务间干扰 大型语言模型
📋 核心要点
- LoRA在多任务学习中存在参数干扰问题,导致性能下降和适配器合并困难。
- LoRI通过冻结投影矩阵A并稀疏化矩阵B,显著减少可训练参数,降低任务间干扰。
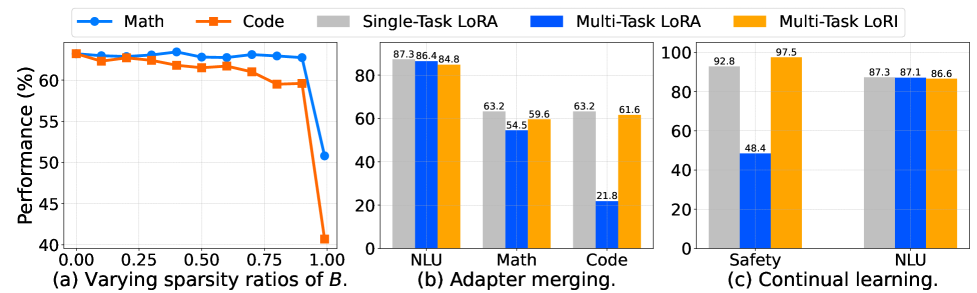
- 实验表明,LoRI在多个任务上优于现有PEFT方法,同时减少了高达95%的可训练参数。
📝 摘要(中文)
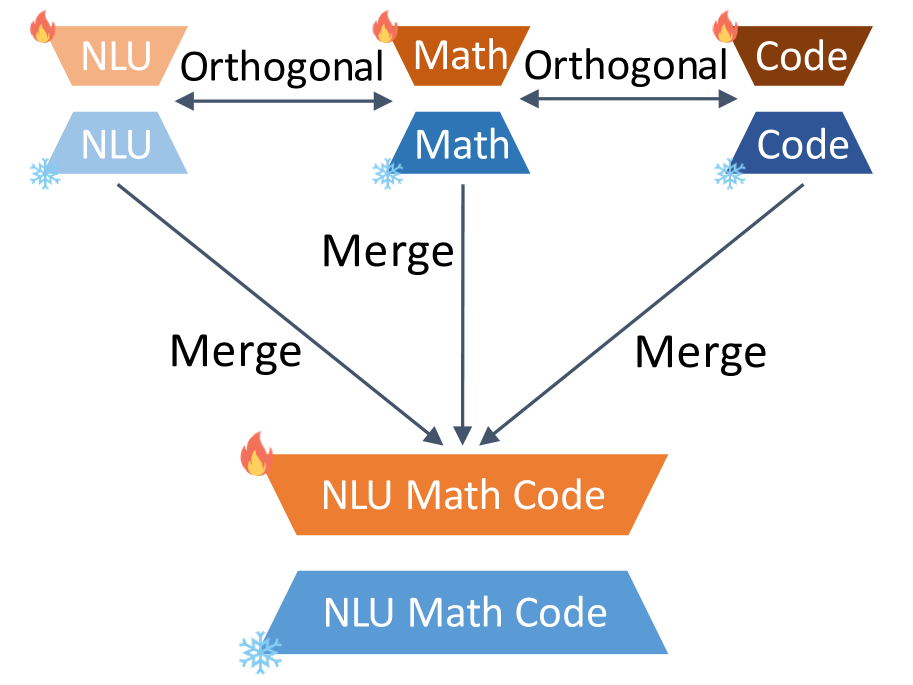
低秩适配(LoRA)已成为大型语言模型(LLM)中一种流行的参数高效微调(PEFT)方法,但它仍然会产生显著的开销,并在多任务场景中遭受参数干扰。我们提出了具有降低干扰的LoRA(LoRI),这是一种简单而有效的方法,它冻结投影矩阵$A$作为随机投影,并使用特定于任务的掩码来稀疏化矩阵$B$。这种设计大大减少了可训练参数的数量,同时保持了强大的任务性能。此外,LoRI通过利用适配器子空间之间的正交性来最小化适配器合并中的跨任务干扰,并通过使用稀疏性来减轻灾难性遗忘,从而支持持续学习。在自然语言理解、数学推理、代码生成和安全对齐任务中的大量实验表明,LoRI优于完全微调和现有的PEFT方法,同时使用的可训练参数比LoRA少95%。在多任务实验中,LoRI能够实现有效的适配器合并和持续学习,并减少跨任务干扰。
🔬 方法详解
问题定义:现有的低秩适配方法(如LoRA)在多任务学习场景中,由于不同任务的适配器参数相互干扰,导致性能下降。此外,在适配器合并时,任务间的干扰会进一步影响合并效果。因此,需要一种方法来减少任务间的干扰,同时保持参数效率。
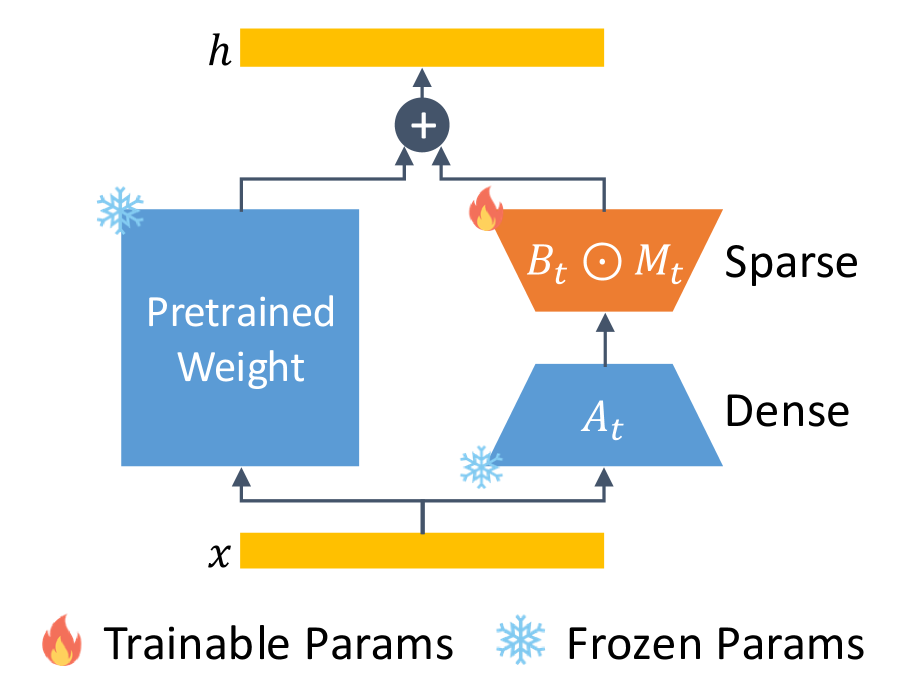
核心思路:LoRI的核心思路是通过随机投影和稀疏化来降低任务间的干扰。具体来说,LoRI冻结LoRA中的投影矩阵A,将其作为随机投影,并使用任务特定的掩码来稀疏化矩阵B。这样,不同任务的适配器参数主要集中在稀疏化的矩阵B上,从而减少了参数干扰。
技术框架:LoRI的整体框架与LoRA类似,都是在预训练语言模型的基础上添加低秩适配器。不同之处在于,LoRI冻结了LoRA中的投影矩阵A,并对矩阵B进行稀疏化。具体流程如下: 1. 在预训练语言模型的每一层添加LoRA适配器。 2. 冻结投影矩阵A,并将其初始化为随机矩阵。 3. 使用任务特定的掩码对矩阵B进行稀疏化。 4. 使用特定任务的数据对稀疏化的矩阵B进行微调。
关键创新:LoRI的关键创新在于通过随机投影和稀疏化来降低任务间的干扰。与LoRA相比,LoRI减少了可训练参数的数量,并提高了多任务学习的性能。此外,LoRI还支持适配器合并和持续学习,并能有效减轻灾难性遗忘。
关键设计:LoRI的关键设计包括: 1. 随机投影矩阵A:使用随机矩阵作为投影矩阵A,可以减少可训练参数的数量,并提高泛化能力。 2. 任务特定的稀疏掩码:使用任务特定的掩码对矩阵B进行稀疏化,可以减少任务间的干扰,并提高多任务学习的性能。 3. 稀疏度:稀疏度的选择会影响LoRI的性能。论文中通过实验确定了最佳的稀疏度。
🖼️ 关键图片
📊 实验亮点
LoRI在多个自然语言处理任务上取得了显著的性能提升。例如,在多任务学习实验中,LoRI优于LoRA和其他PEFT方法,同时使用的可训练参数减少了高达95%。在持续学习实验中,LoRI能够有效减轻灾难性遗忘,并保持较高的性能。
🎯 应用场景
LoRI可应用于各种需要参数高效微调的大型语言模型应用场景,例如多任务学习、持续学习、领域自适应等。特别是在资源受限的设备上,LoRI能够以较小的参数开销实现较好的性能,具有重要的实际应用价值。未来,LoRI可以进一步扩展到其他类型的模型和任务中。
📄 摘要(原文)
Low-Rank Adaptation (LoRA) has emerged as a popular parameter-efficient fine-tuning (PEFT) method for Large Language Models (LLMs), yet it still incurs notable overhead and suffers from parameter interference in multi-task scenarios. We propose LoRA with Reduced Interference (LoRI), a simple yet effective approach that freezes the projection matrices $A$ as random projections and sparsifies the matrices $B$ using task-specific masks. This design substantially reduces the number of trainable parameters while maintaining strong task performance. Moreover, LoRI minimizes cross-task interference in adapter merging by leveraging the orthogonality between adapter subspaces, and supports continual learning by using sparsity to mitigate catastrophic forgetting. Extensive experiments across natural language understanding, mathematical reasoning, code generation, and safety alignment tasks demonstrate that LoRI outperforms full fine-tuning and existing PEFT methods, while using up to 95% fewer trainable parameters than LoRA. In multi-task experiments, LoRI enables effective adapter merging and continual learning with reduced cross-task interference. Code is available at: https://github.com/juzhengz/LoRI