Bridging the Gap Between Preference Alignment and Machine Unlearning
作者: Xiaohua Feng, Yuyuan Li, Huwei Ji, Jiaming Zhang, Li Zhang, Tianyu Du, Chaochao Chen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-04-09
备注: 17 pages
💡 一句话要点
提出U2A框架,通过选择性遗忘负样本提升大语言模型偏好对齐性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好对齐 大语言模型 机器遗忘 双层优化 负样本选择
📋 核心要点
- 现有RLHF等偏好对齐方法依赖大量高质量数据,成本高昂且训练不稳定,限制了其在低资源场景的应用。
- 论文提出U2A框架,通过双层优化选择并遗忘对偏好对齐影响最大的负样本,从而提升模型性能。
- 实验结果表明,U2A框架能够有效提升偏好对齐性能,验证了选择性遗忘负样本策略的有效性。
📝 摘要(中文)
尽管大语言模型(LLMs)的偏好对齐(PA)取得了进展,但主流方法如基于人类反馈的强化学习(RLHF)面临着显著的挑战。这些方法需要高质量的正向偏好示例数据集,获取成本高昂,且由于训练不稳定,计算量大,限制了它们在低资源场景中的使用。LLM遗忘技术提供了一种有前景的替代方案,通过直接消除负面示例的影响。然而,目前的研究主要集中在经验验证上,缺乏系统的定量分析。为了弥合这一差距,我们提出了一个框架来探索PA和LLM遗忘之间的关系。具体来说,我们引入了一种基于双层优化的方法来量化遗忘特定负面示例对PA性能的影响。我们的分析表明,并非所有负面示例在遗忘时对对齐改进的贡献相同,并且效果因示例而异。基于这一洞察,我们提出了一个关键问题:如何优化选择和加权负面示例以进行遗忘,从而最大化PA性能?为了回答这个问题,我们提出了一个名为Unlearning to Align(U2A)的框架,该框架利用双层优化来有效地选择和遗忘示例,以实现最佳的PA性能。我们通过广泛的实验验证了所提出的方法,结果证实了其有效性。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)等偏好对齐方法,需要大量高质量的正向偏好数据,获取成本高昂,且训练过程计算密集且不稳定。此外,现有LLM遗忘技术主要集中于经验验证,缺乏对遗忘与偏好对齐之间关系的系统性定量分析。
核心思路:论文的核心思路是通过选择性地遗忘负样本来提升偏好对齐性能。并非所有负样本对偏好对齐的贡献相同,因此,通过优化选择那些对偏好对齐影响最大的负样本进行遗忘,可以更有效地提升模型性能。这种方法旨在降低数据需求和计算成本,同时提高训练的稳定性。
技术框架:U2A框架采用双层优化结构。外层优化目标是最大化偏好对齐性能,内层优化目标是选择和加权用于遗忘的负样本。框架包含以下主要步骤:1) 使用双层优化方法量化遗忘特定负样本对偏好对齐性能的影响;2) 基于量化结果,选择对偏好对齐影响最大的负样本;3) 使用LLM遗忘技术,从模型中移除所选负样本的影响。
关键创新:论文的关键创新在于提出了一个将LLM遗忘技术应用于偏好对齐问题的框架,并采用双层优化方法来选择和加权用于遗忘的负样本。与现有方法相比,U2A框架不需要大量正向偏好数据,而是通过选择性地遗忘负样本来提升模型性能,从而降低了数据需求和计算成本。
关键设计:U2A框架的关键设计包括:1) 使用双层优化来学习负样本的权重,外层优化偏好对齐目标,内层优化负样本权重;2) 使用特定的遗忘算法(具体算法未知,论文中未明确说明)来移除所选负样本的影响;3) 采用合适的偏好对齐评估指标(具体指标未知,论文中未明确说明)来评估U2A框架的性能。
🖼️ 关键图片
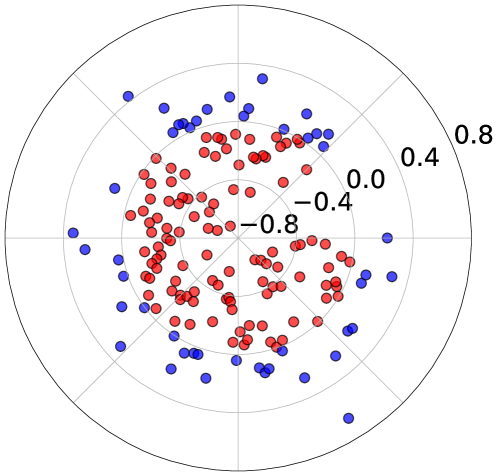
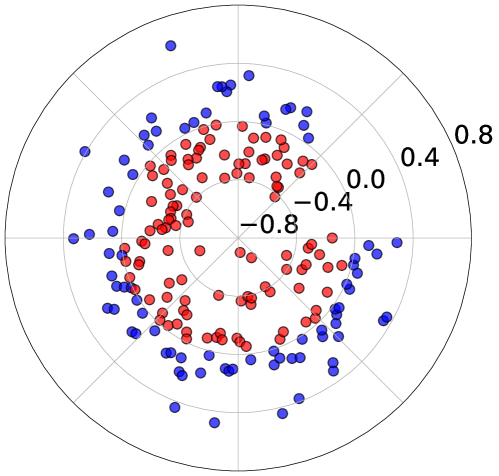
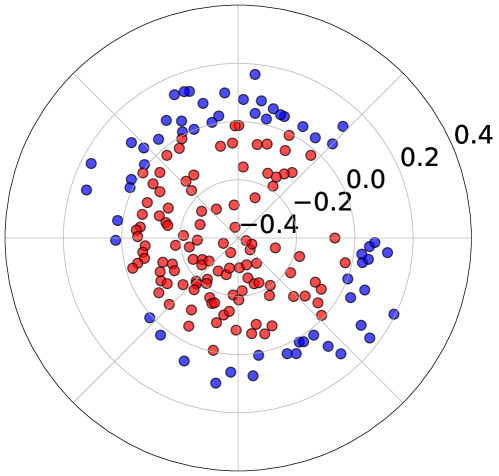
📊 实验亮点
论文通过实验验证了U2A框架的有效性,结果表明,U2A框架能够显著提升偏好对齐性能。具体的性能数据、对比基线和提升幅度在摘要中未明确给出,需要在论文正文中查找。实验结果证实了选择性遗忘负样本策略的有效性。
🎯 应用场景
该研究成果可应用于各种需要偏好对齐的大语言模型应用场景,例如对话系统、文本生成、推荐系统等。通过选择性遗忘负样本,可以提升模型在低资源场景下的偏好对齐性能,降低数据标注成本,并提高模型的鲁棒性和安全性。未来,该方法可以进一步扩展到其他机器学习任务中。
📄 摘要(原文)
Despite advances in Preference Alignment (PA) for Large Language Models (LLMs), mainstream methods like Reinforcement Learning with Human Feedback (RLHF) face notable challenges. These approaches require high-quality datasets of positive preference examples, which are costly to obtain and computationally intensive due to training instability, limiting their use in low-resource scenarios. LLM unlearning technique presents a promising alternative, by directly removing the influence of negative examples. However, current research has primarily focused on empirical validation, lacking systematic quantitative analysis. To bridge this gap, we propose a framework to explore the relationship between PA and LLM unlearning. Specifically, we introduce a bi-level optimization-based method to quantify the impact of unlearning specific negative examples on PA performance. Our analysis reveals that not all negative examples contribute equally to alignment improvement when unlearned, and the effect varies significantly across examples. Building on this insight, we pose a crucial question: how can we optimally select and weight negative examples for unlearning to maximize PA performance? To answer this, we propose a framework called Unlearning to Align (U2A), which leverages bi-level optimization to efficiently select and unlearn examples for optimal PA performance. We validate the proposed method through extensive experiments, with results confirming its effectiveness.