Hogwild! Inference: Parallel LLM Generation via Concurrent Attention
作者: Gleb Rodionov, Roman Garipov, Alina Shutova, George Yakushev, Erik Schultheis, Vage Egiazarian, Anton Sinitsin, Denis Kuznedelev, Dan Alistarh
分类: cs.LG, cs.CL
发布日期: 2025-04-08 (更新: 2025-11-17)
备注: 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
💡 一句话要点
Hogwild! Inference:通过并发注意力机制实现LLM并行生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 并行推理 大型语言模型 注意力机制 并发计算 Key-Value缓存
📋 核心要点
- 现有LLM推理速度慢,限制了其在复杂任务中的应用,需要更高效的并行推理方法。
- 提出Hogwild! Inference,允许多个LLM实例并行运行,通过共享注意力缓存实现协作。
- 实验表明,该方法无需额外微调即可实现LLM的并行推理,并有效利用并行硬件。
📝 摘要(中文)
大型语言模型(LLM)已经展示了通过高级推理、长文本生成和工具使用来解决日益复杂的任务的能力。解决这些任务通常涉及长时间的推理计算。在人类解决问题时,一种常见的加速工作策略是协作:将问题分解为子任务,同时探索不同的策略等。最近的研究表明,LLM也可以通过实施显式合作框架并行运行,例如投票机制或显式创建可以并行执行的独立子任务。然而,这些框架可能并不适用于所有类型的任务,这可能会阻碍它们的应用。在这项工作中,我们提出了一种不同的设计方法:我们并行运行LLM“worker”,允许它们通过并发更新的注意力缓存进行同步,并提示这些worker决定如何最好地协作。我们的方法允许LLM实例针对手头的问题提出自己的协作策略,同时“看到”彼此在并发KV缓存中的记忆。我们通过Hogwild! Inference来实现这种方法:一个并行LLM推理引擎,其中同一LLM的多个实例并行运行,具有相同的注意力缓存,可以“即时”访问彼此的记忆。Hogwild! Inference利用旋转位置嵌入(RoPE)来避免重新计算,同时提高并行硬件利用率。我们发现,现代具有推理能力的LLM可以在共享Key-Value缓存的情况下执行推理,而无需额外的微调。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理速度慢的问题。现有方法,如投票机制或独立子任务并行执行,存在适用性受限的问题,无法充分利用LLM的并行计算潜力。
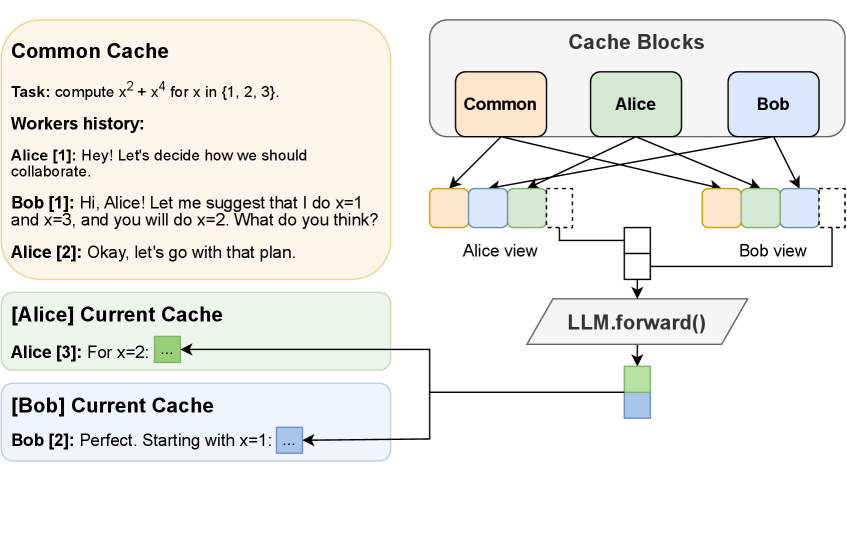
核心思路:核心思路是允许多个LLM实例(称为“worker”)并行运行,并共享一个并发更新的注意力缓存(Key-Value cache)。这些worker可以“看到”彼此的记忆,从而动态地协作解决问题,而无需预定义的协作策略。
技术框架:Hogwild! Inference 引擎包含多个并行运行的LLM实例,每个实例都访问同一个注意力缓存。当一个worker生成新的token时,其对应的Key和Value会被立即写入共享缓存,其他worker可以立即访问这些信息。这种即时访问机制使得worker之间能够进行有效的协作。
关键创新:最重要的创新点在于并发注意力机制,允许多个LLM实例在没有显式同步或协调的情况下共享和利用彼此的记忆。这种方法避免了传统并行方法中常见的通信瓶颈和同步开销。
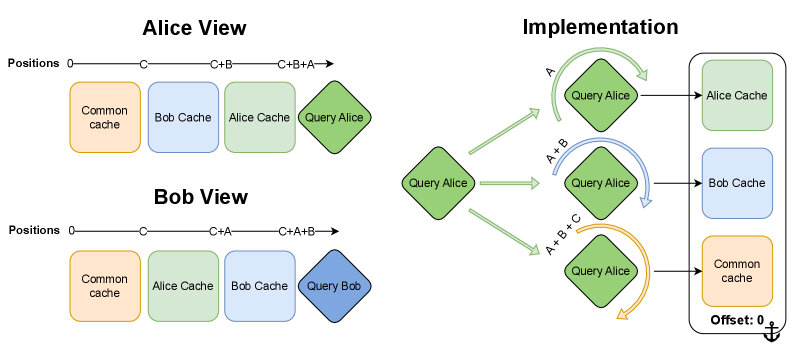
关键设计:该方法利用旋转位置嵌入(RoPE)来避免在并行推理过程中进行重复计算,从而提高硬件利用率。此外,论文强调,现代具有推理能力的LLM可以直接应用于Hogwild! Inference,无需额外的微调。
🖼️ 关键图片
📊 实验亮点
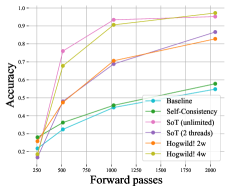
实验结果表明,现代具有推理能力的LLM可以直接应用于Hogwild! Inference,无需额外的微调。通过共享Key-Value缓存,多个LLM实例可以并行推理,显著提高推理速度和硬件利用率。具体的性能数据和对比基线在论文中给出,展示了该方法在并行LLM推理方面的优势。
🎯 应用场景
Hogwild! Inference 可应用于需要快速推理和并行处理的各种场景,例如实时对话系统、大规模文本生成、复杂问题求解和多智能体协作。该方法能够显著提高LLM的推理速度,使其能够更好地应对计算密集型任务,并为未来的LLM应用开辟新的可能性。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involves long inference-time computations. In human problem solving, a common strategy to expedite work is collaboration: by dividing the problem into sub-tasks, exploring different strategies concurrently, etc. Recent research has shown that LLMs can also operate in parallel by implementing explicit cooperation frameworks, such as voting mechanisms or the explicit creation of independent sub-tasks that can be executed in parallel. However, each of these frameworks may not be suitable for all types of tasks, which can hinder their applicability. In this work, we propose a different design approach: we run LLM "workers" in parallel , allowing them to synchronize via a concurrently-updated attention cache and prompt these workers to decide how best to collaborate. Our approach allows the LLM instances to come up with their own collaboration strategy for the problem at hand, all the while "seeing" each other's memory in the concurrent KV cache. We implement this approach via Hogwild! Inference: a parallel LLM inference engine where multiple instances of the same LLM run in parallel with the same attention cache, with "instant" access to each other's memory. Hogwild! Inference takes advantage of Rotary Position Embeddings (RoPE) to avoid recomputation while improving parallel hardware utilization. We find that modern reasoning-capable LLMs can perform inference with shared Key-Value cache out of the box, without additional fine-tuning.