Smart Exploration in Reinforcement Learning using Bounded Uncertainty Models
作者: J. S. van Hulst, W. P. M. H. Heemels, D. J. Antunes
分类: cs.LG, eess.SY
发布日期: 2025-04-08 (更新: 2025-10-30)
备注: Accepted for Presentation at 64th IEEE Conference on Decision and Control, CDC 2025, Rio de Janeiro, Brazil, 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于有界不确定性模型的强化学习智能探索方法,加速学习过程。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 智能探索 有界不确定性模型 Q函数 模型集优化
📋 核心要点
- 强化学习需要大量数据,探索效率低是主要瓶颈,难以快速学习最优策略。
- 利用包含真实模型的模型集,优化Q函数上下界,指导智能体高效探索。
- BUMEX方法在基准测试中显著加速了学习过程,验证了其有效性。
📝 摘要(中文)
强化学习(RL)是解决不确定环境中决策问题的强大框架,但通常需要大量数据才能学习到最优策略。本文通过结合先验模型知识来指导探索并加速学习过程,从而应对这一挑战。具体而言,我们假设可以访问包含真实转移核和奖励函数的模型集。我们在此模型集上进行优化,以获得Q函数的上下界,然后使用这些上下界来指导agent的探索。我们为所提出的探索策略类下Q函数收敛到最优Q函数提供了理论保证。此外,我们还引入了模型集优化问题的数据驱动正则化版本,以确保探索策略类收敛到最优策略。最后,我们表明,当模型集具有特定结构(即有界参数MDP (BMDP) 框架)时,正则化的模型集优化问题变得凸且易于实现。在这种情况下,我们还在温和的假设下证明了有限时间收敛到最优策略。我们在仿真研究中证明了所提出的探索策略(我们称之为BUMEX(基于有界不确定性模型的探索))的有效性。结果表明,所提出的方法可以显著加速基准示例中的学习。
🔬 方法详解
问题定义:强化学习在复杂环境中需要大量的探索才能找到最优策略,效率低下。现有的探索方法往往是随机的,或者依赖于对环境的初步估计,但这些估计可能不准确,导致探索方向错误,浪费计算资源。因此,如何有效地利用先验知识来指导探索,加速学习过程,是本文要解决的核心问题。
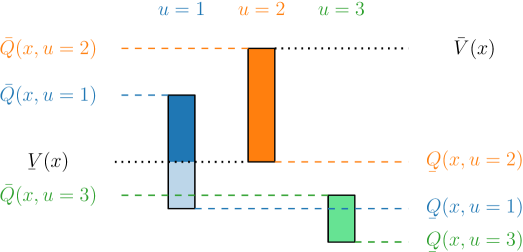
核心思路:本文的核心思路是利用一个包含真实环境模型的模型集,通过优化这个模型集来获得Q函数的上下界。这些上下界可以作为探索的指导,智能体倾向于探索那些Q函数值不确定性高的状态-动作对,从而更有效地发现潜在的最优策略。这种方法避免了盲目探索,并能充分利用已知的环境信息。
技术框架:BUMEX方法的整体框架如下:1. 模型集构建:基于先验知识构建一个包含真实转移核和奖励函数的模型集。2. Q函数上下界优化:在模型集上进行优化,计算Q函数的上下界。3. 探索策略设计:基于Q函数的上下界,设计探索策略,引导智能体选择具有高不确定性的状态-动作对。4. 策略迭代:智能体与环境交互,收集数据,更新模型集和Q函数上下界,重复步骤2和3,直到收敛。
关键创新:本文的关键创新在于提出了一种基于有界不确定性模型的强化学习探索方法。与传统的探索方法相比,BUMEX方法能够更有效地利用先验知识,避免盲目探索,从而加速学习过程。此外,本文还提供了理论保证,证明了在所提出的探索策略类下,Q函数能够收敛到最优Q函数。
关键设计:在模型集优化方面,本文引入了数据驱动的正则化项,以确保探索策略的收敛性。当模型集具有特定结构(即有界参数MDP (BMDP) 框架)时,正则化的模型集优化问题可以转化为凸优化问题,从而更容易求解。具体的探索策略可以采用ε-greedy策略,其中ε的值与Q函数上下界的不确定性成正比。
🖼️ 关键图片
📊 实验亮点
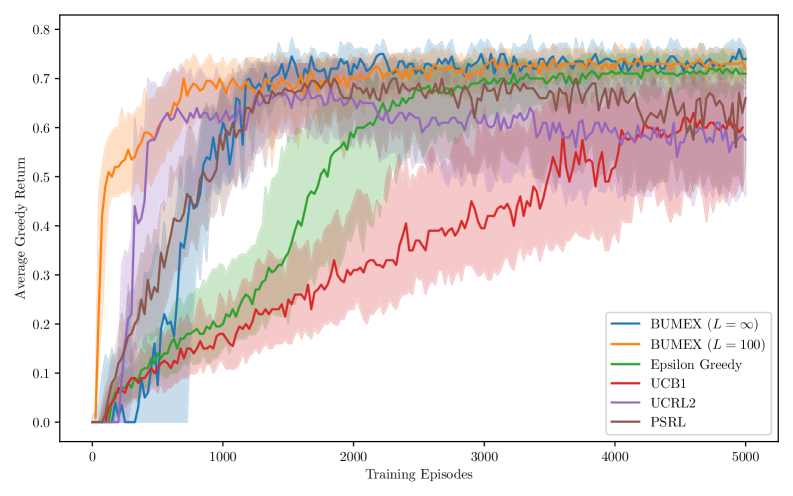
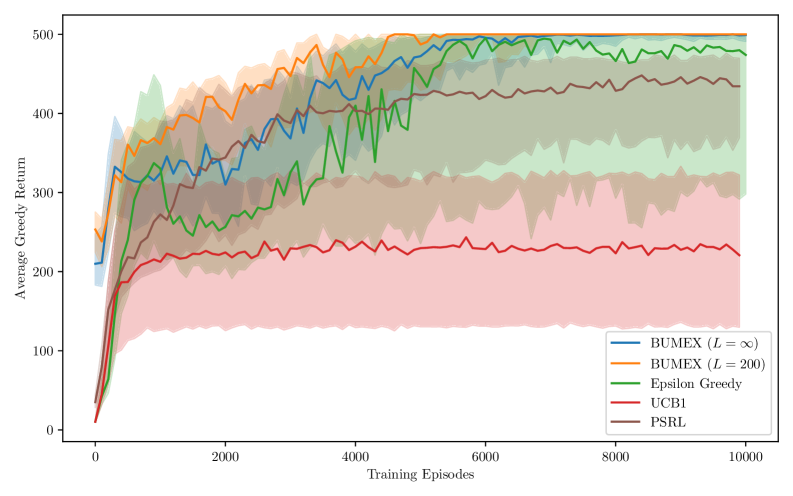
实验结果表明,BUMEX方法在基准测试中能够显著加速学习过程。例如,在某些任务中,BUMEX方法能够比传统的强化学习算法更快地达到最优策略,并且所需的样本数量更少。具体的数据和对比基线可以在论文的实验部分找到。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、游戏AI等领域。通过利用先验知识,可以显著减少智能体在复杂环境中的探索时间,提高学习效率,从而更快地部署和应用强化学习算法。未来,该方法可以扩展到更复杂的模型集和探索策略,进一步提升其性能和适用性。
📄 摘要(原文)
Reinforcement learning (RL) is a powerful framework for decision-making in uncertain environments, but it often requires large amounts of data to learn an optimal policy. We address this challenge by incorporating prior model knowledge to guide exploration and accelerate the learning process. Specifically, we assume access to a model set that contains the true transition kernel and reward function. We optimize over this model set to obtain upper and lower bounds on the Q-function, which are then used to guide the exploration of the agent. We provide theoretical guarantees on the convergence of the Q-function to the optimal Q-function under the proposed class of exploring policies. Furthermore, we also introduce a data-driven regularized version of the model set optimization problem that ensures the convergence of the class of exploring policies to the optimal policy. Lastly, we show that when the model set has a specific structure, namely the bounded-parameter MDP (BMDP) framework, the regularized model set optimization problem becomes convex and simple to implement. In this setting, we also prove finite-time convergence to the optimal policy under mild assumptions. We demonstrate the effectiveness of the proposed exploration strategy, which we call BUMEX (Bounded Uncertainty Model-based Exploration), in a simulation study. The results indicate that the proposed method can significantly accelerate learning in benchmark examples. A toolbox is available at https://github.com/JvHulst/BUMEX.