GraphRAFT: Retrieval Augmented Fine-Tuning for Knowledge Graphs on Graph Databases
作者: Alfred Clemedtson, Borun Shi
分类: cs.LG, cs.CL, cs.IR
发布日期: 2025-04-07 (更新: 2025-11-12)
💡 一句话要点
GraphRAFT:用于图数据库知识图谱的检索增强微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 图数据库 检索增强生成 大型语言模型 图查询语言
📋 核心要点
- 现有GraphRAG方法在检索步骤上存在不足,要么忽略检索,要么检索过程抽象低效,无法直接应用于图数据库。
- GraphRAFT通过微调LLM生成可证明正确的Cypher查询,从图数据库中检索高质量子图,从而实现准确问答。
- 实验表明GraphRAFT具有样本效率,性能随训练数据增加而提升,并在多个指标上显著优于现有方法。
📝 摘要(中文)
大型语言模型(LLM)在语言处理和推理方面表现出色,但在被问及私有数据时容易产生幻觉。检索增强生成(RAG)检索相关数据,使其适应LLM的上下文窗口,并提示LLM给出答案。GraphRAG将此方法扩展到结构化知识图谱(KG)以及关于多跳实体的提问。目前大多数GraphRAG方法要么忽略检索步骤,要么采用抽象或低效的临时检索过程。这阻碍了它们在存储于支持图查询语言的图数据库中的KG上的应用。本文提出了GraphRAFT,一个检索和推理框架,它对LLM进行微调,以生成可证明正确的Cypher查询,从而检索高质量的子图上下文并产生准确的答案。我们的方法是第一个可以开箱即用并用于存储在原生图数据库中的KG的解决方案。基准测试表明,我们的方法具有样本效率,并且可以随着训练数据的可用性而扩展。在大型文本属性KG上的两个具有挑战性的问答任务中,我们的方法在所有四个标准指标上都明显优于所有最先进的模型。
🔬 方法详解
问题定义:论文旨在解决现有GraphRAG方法在图数据库上的知识图谱问答任务中,检索效率低、无法直接应用的问题。现有方法要么忽略检索步骤,要么使用效率低下的检索策略,无法充分利用图数据库的查询能力,导致问答准确率不高。
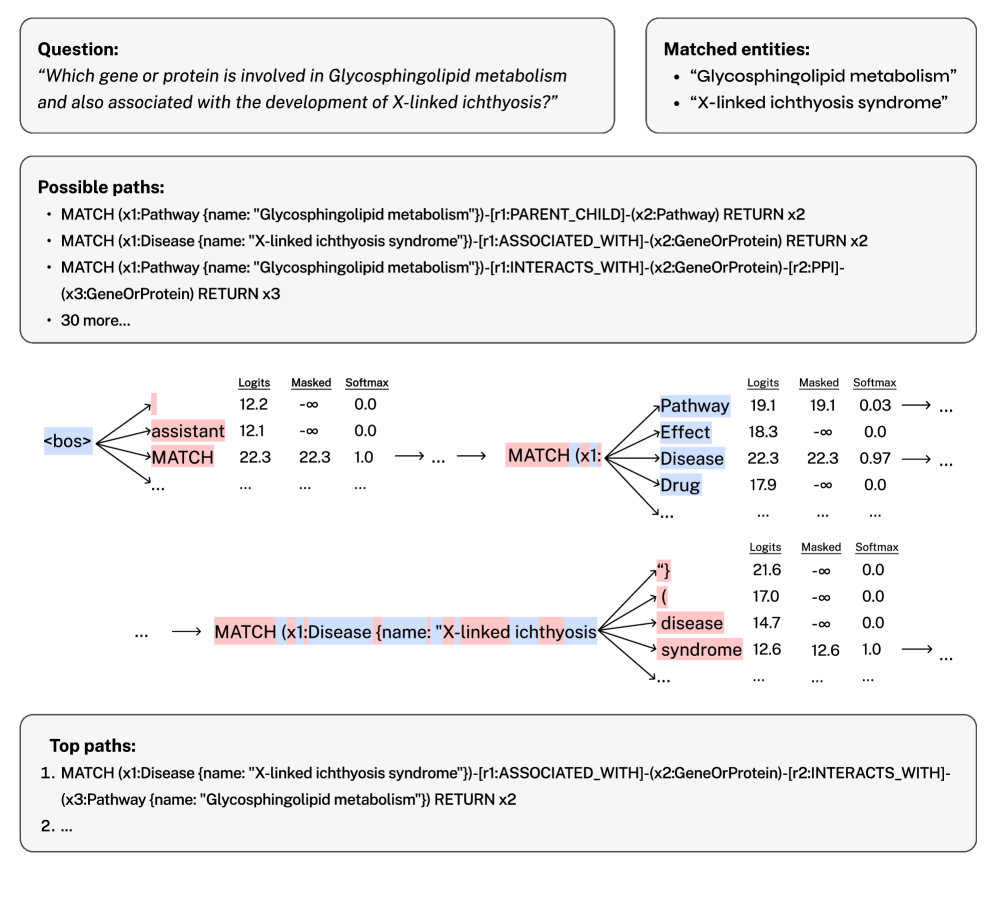
核心思路:论文的核心思路是利用LLM生成图数据库的查询语言(Cypher),从而直接从图数据库中检索相关的子图信息,作为LLM的上下文,进而提升问答的准确性。通过微调LLM,使其能够生成高质量的Cypher查询,从而实现高效的知识检索。
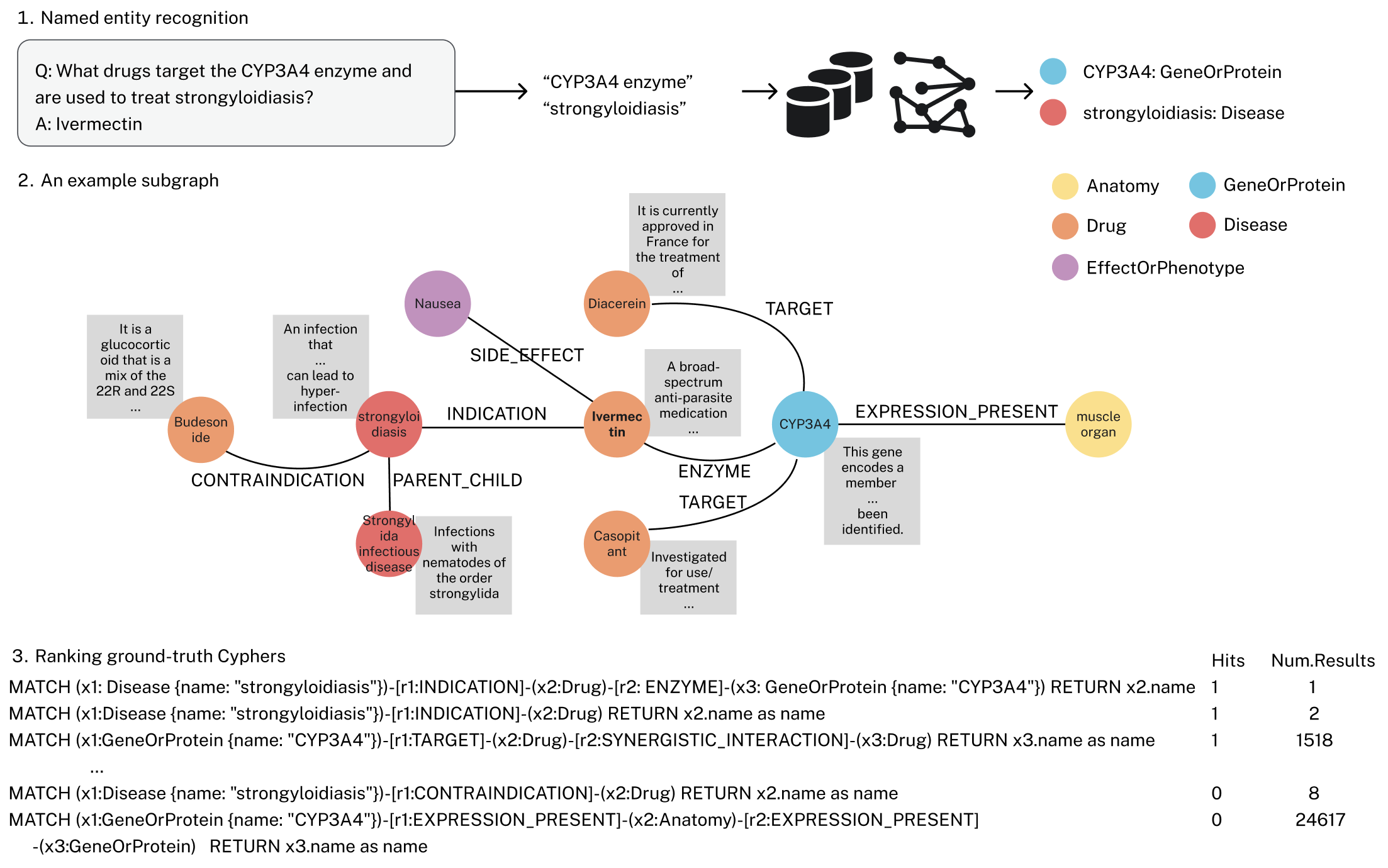
技术框架:GraphRAFT框架主要包含两个阶段:检索阶段和推理阶段。在检索阶段,首先将问题输入到微调后的LLM中,LLM生成Cypher查询语句。然后,使用生成的Cypher查询在图数据库中检索相关的子图。在推理阶段,将检索到的子图信息和原始问题一起输入到LLM中,LLM根据上下文信息生成最终的答案。
关键创新:GraphRAFT的关键创新在于利用LLM直接生成图数据库的查询语句,从而实现高效的知识检索。与现有方法相比,GraphRAFT能够充分利用图数据库的查询能力,避免了复杂的图嵌入和相似度计算过程,提高了检索效率和问答准确率。此外,GraphRAFT通过微调LLM,使其能够生成可证明正确的Cypher查询,保证了检索结果的可靠性。
关键设计:GraphRAFT的关键设计包括:1) 使用Cypher作为查询语言,因为它是一种广泛使用的图数据库查询语言,具有强大的表达能力。2) 使用微调后的LLM生成Cypher查询,通过训练数据来指导LLM生成高质量的查询语句。3) 使用检索到的子图信息作为LLM的上下文,从而提高问答的准确性。具体的损失函数和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
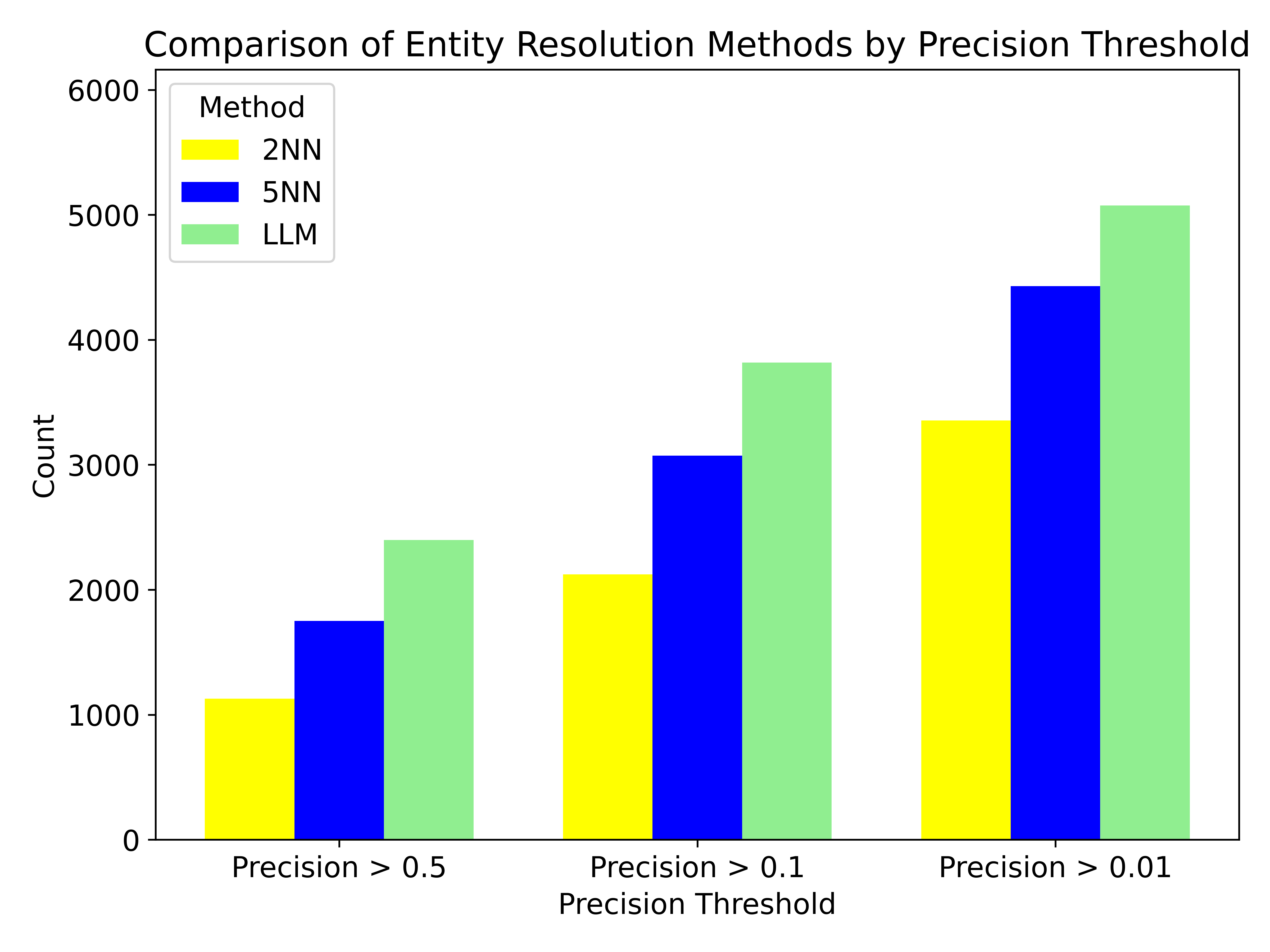
实验结果表明,GraphRAFT在两个具有挑战性的问答任务中,显著优于所有最先进的模型。具体性能数据和提升幅度在摘要中提到“在所有四个标准指标上都明显优于所有最先进的模型”,但未给出具体数值。实验还表明GraphRAFT具有样本效率,并且可以随着训练数据的可用性而扩展。
🎯 应用场景
GraphRAFT可应用于各种需要知识图谱问答的场景,例如智能客服、金融风控、医疗诊断等。通过高效地从图数据库中检索知识,GraphRAFT可以帮助用户快速获取准确的信息,提高决策效率。未来,GraphRAFT可以进一步扩展到其他类型的图数据库和查询语言,并与其他技术(如知识图谱补全、实体链接)相结合,以实现更强大的知识图谱应用。
📄 摘要(原文)
Large language models have shown remarkable language processing and reasoning ability but are prone to hallucinate when asked about private data. Retrieval-augmented generation (RAG) retrieves relevant data that fit into an LLM's context window and prompts the LLM for an answer. GraphRAG extends this approach to structured Knowledge Graphs (KGs) and questions regarding entities multiple hops away. The majority of recent GraphRAG methods either overlook the retrieval step or have ad hoc retrieval processes that are abstract or inefficient. This prevents them from being adopted when the KGs are stored in graph databases supporting graph query languages. In this work, we present GraphRAFT, a retrieve-and-reason framework that finetunes LLMs to generate provably correct Cypher queries to retrieve high-quality subgraph contexts and produce accurate answers. Our method is the first such solution that can be taken off-the-shelf and used on KGs stored in native graph DBs. Benchmarks suggest that our method is sample-efficient and scales with the availability of training data. Our method achieves significantly better results than all state-of-the-art models across all four standard metrics on two challenging Q&As on large text-attributed KGs.