Achieving binary weight and activation for LLMs using Post-Training Quantization
作者: Siqing Song, Chuang Wang, Ruiqi Wang, Yi Yang, Xu-Yao Zhang
分类: cs.LG, cs.AI
发布日期: 2025-04-07 (更新: 2025-06-30)
🔗 代码/项目: GITHUB
💡 一句话要点
提出W(1+1)A(1*4)量化框架,实现LLM二值化,显著降低计算成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型量化 后训练量化 二值化 模型压缩 Hessian感知 细粒度分组 激活值量化
📋 核心要点
- 现有LLM量化技术在低于4比特精度(W4A4)时性能显著下降,无法有效降低计算成本。
- 论文提出W(1+1)A(1*4)量化方案,通过细粒度分组和通道扩展,提升二值化量化精度。
- 实验表明,该方法在多个任务上超越了W2A4的SOTA基线,向完全二值化LLM迈进。
📝 摘要(中文)
本文提出了一种后训练量化框架,使用W(1+1)A(1*4)配置,即权重被量化为1比特,并额外使用1比特进行细粒度分组,激活值被量化为1比特,但通道数增加了4倍。对于权重量化,我们提出利用Hessian感知的细粒度分组以及基于EM的量化方案。对于激活量化,我们将INT4量化的激活值等价地分解为4 * INT1格式,并同时平滑基于量化误差的缩放因子,从而进一步减少激活值中的量化误差。我们的方法在多个任务上超越了W2A4的最先进LLM量化基线,推动了现有LLM量化方法向完全二值化模型发展。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)量化到1比特精度时性能显著下降的问题。现有的量化技术在权重和激活值精度低于4比特时(W4A4)会遭受明显的性能损失,限制了模型压缩和加速的潜力。因此,如何在保持LLM性能的同时,实现更激进的二值化(W1A1)成为一个关键挑战。
核心思路:论文的核心思路是通过更精细的量化策略来弥补二值化带来的信息损失。对于权重,采用Hessian感知的细粒度分组,允许不同组的权重使用不同的量化参数,从而更好地适应权重的分布。对于激活值,通过增加通道数和误差平滑,减少量化误差的影响。
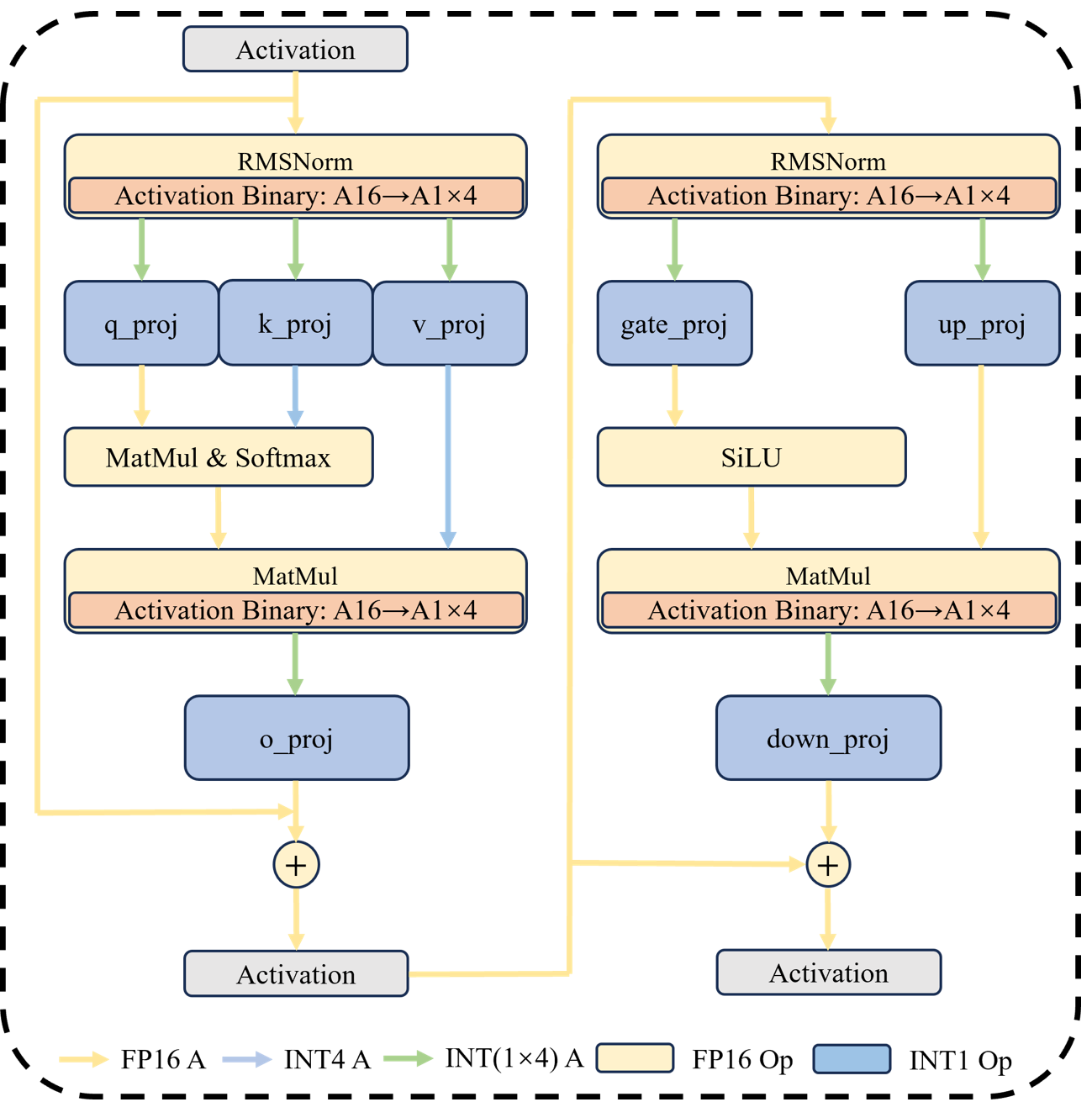
技术框架:该方法是一个后训练量化(PTQ)框架,主要包含两个模块:权重二值化和激活值二值化。权重二值化模块使用Hessian感知的细粒度分组和EM算法进行量化。激活值二值化模块将INT4量化的激活值分解为4 * INT1格式,并进行缩放因子平滑。整个流程无需重新训练模型,可以直接对预训练的LLM进行量化。
关键创新:该方法最重要的创新点在于W(1+1)A(1*4)的量化配置。与传统的W1A1量化相比,该方法通过额外的1比特权重分组和4倍通道扩展,显著提升了量化精度。Hessian感知的分组策略能够更好地捕捉权重的分布特征,而激活值的分解和缩放因子平滑则能够有效减少量化误差。
关键设计:在权重量化方面,Hessian矩阵被用于指导权重的分组,使得具有相似Hessian特征的权重被分到同一组。EM算法用于优化每个组的量化参数。在激活值量化方面,INT4量化被分解为4个INT1量化,每个INT1量化对应一个通道,从而实现了通道扩展。缩放因子平滑基于量化误差进行,旨在减少量化带来的信息损失。
🖼️ 关键图片

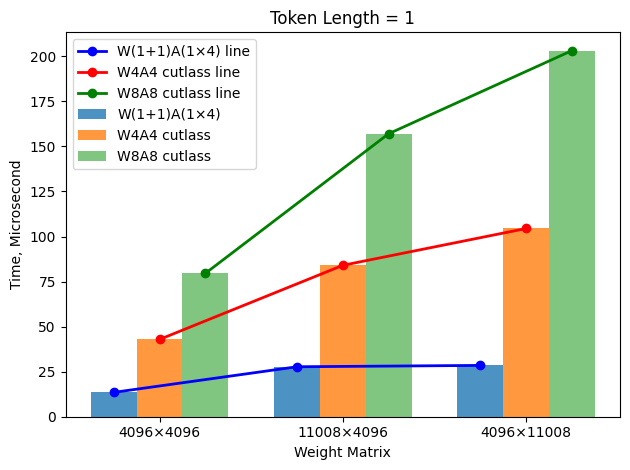
📊 实验亮点
该方法在多个任务上超越了W2A4的最先进LLM量化基线,证明了W(1+1)A(1*4)量化配置的有效性。实验结果表明,该方法能够在保持LLM性能的同时,实现更激进的二值化,为LLM在资源受限环境下的部署提供了新的可能性。具体性能数据未知,但摘要明确指出超越了SOTA。
🎯 应用场景
该研究成果可应用于各种需要低计算成本和低存储空间的场景,例如移动设备上的LLM部署、边缘计算设备上的自然语言处理任务等。通过将LLM量化到二值化精度,可以显著降低模型的计算复杂度和存储需求,从而使其能够在资源受限的设备上运行,并加速推理速度。
📄 摘要(原文)
Quantizing large language models (LLMs) to 1-bit precision significantly reduces computational costs, but existing quantization techniques suffer from noticeable performance degradation when using weight and activation precisions below 4 bits (W4A4). In this paper, we propose a post-training quantization framework with W(1+1)A(1*4) configuration, where weights are quantized to 1 bit with an additional 1 bit for fine-grain grouping and activations are quantized to 1 bit with a 4-fold increase in the number of channels. For weight quantization, we propose utilizing Hessian-aware fine-grained grouping along with an EM-based quantization scheme. For activation quantization, we decompose INT4-quantized activations into a 4 * INT1 format equivalently and simultaneously smooth the scaling factors based on quantization errors, which further reduces the quantization errors in activations. Our method surpasses state-of-the-art (SOTA) LLM quantization baselines on W2A4 across multiple tasks, pushing the boundaries of existing LLM quantization methods toward fully binarized models. Code is available at https://github.com/JimmyCrave/LLM-PTQ-binarization.