Dion: Distributed Orthonormalized Updates
作者: Kwangjun Ahn, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, John Langford
分类: cs.LG, cs.AI, math.OC
发布日期: 2025-04-07 (更新: 2025-09-15)
备注: "Version 3" with various new updates
🔗 代码/项目: GITHUB
💡 一句话要点
Dion:一种可扩展的分布式正交化更新方法,加速大规模LLM训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式训练 正交化更新 大规模语言模型 优化器 摊销幂迭代
📋 核心要点
- 现有正交化更新方法依赖稠密矩阵运算,与大规模LLM训练中的权重分片不兼容,导致计算和通信成本高昂。
- Dion通过在动量缓冲上使用摊销幂迭代代替Newton-Schulz迭代,避免全矩阵重建,实现与权重分片的无缝集成。
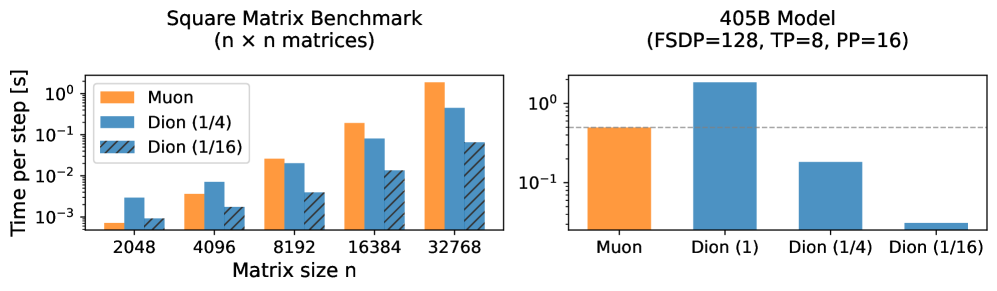
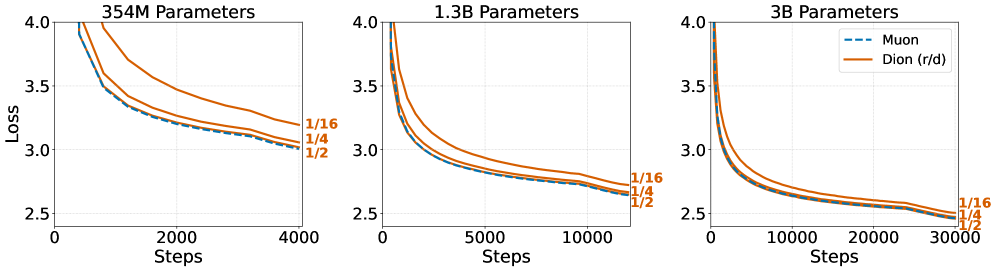
- 实验表明,Dion在1.6亿到30亿参数的语言模型上,保留正交化更新优势的同时,显著减少了训练耗时。
📝 摘要(中文)
正交化更新能够加速训练,提高稳定性,并实现稳健的超参数迁移。然而,现有方法(如Muon)依赖于稠密矩阵运算,这与大规模LLM训练中的分片权重相冲突,导致高昂的计算和通信成本。我们提出了Dion(分布式正交化),一种可扩展且高效的更新规则,它用动量缓冲上的摊销幂迭代代替Newton-Schulz迭代,避免了全矩阵重建,并与权重分片无缝集成。带有误差反馈的秩分数参数实现了低秩更新,从而在质量和显著的成本节约之间取得平衡。在参数量从1.6亿到30亿的语言模型上,Dion保留了正交化更新的优势,同时显著减少了大规模训练的实际耗时,使其成为下一代基础模型的实用优化器。
🔬 方法详解
问题定义:大规模语言模型训练中,正交化更新可以提升训练稳定性和超参数迁移能力,但现有方法如Muon依赖于稠密矩阵运算,这与权重分片策略冲突,导致巨大的计算和通信开销,成为训练瓶颈。
核心思路:Dion的核心在于避免直接进行稠密矩阵的正交化计算。它通过在动量缓冲上进行摊销幂迭代,近似计算正交化更新,从而避免了全矩阵的重建和操作,降低了计算复杂度。同时,Dion与权重分片策略兼容,能够直接应用于分布式训练。
技术框架:Dion的整体框架包括以下几个关键步骤:1. 计算梯度;2. 使用动量累积梯度信息;3. 在动量缓冲上进行摊销幂迭代,估计正交化更新矩阵;4. 将估计的正交化更新矩阵应用于模型参数。其中,动量缓冲用于存储历史梯度信息,摊销幂迭代用于近似计算正交化更新矩阵。
关键创新:Dion的关键创新在于使用摊销幂迭代来近似计算正交化更新矩阵,避免了稠密矩阵运算。此外,引入了秩分数参数和误差反馈机制,可以在保证更新质量的前提下,进一步降低计算成本。这种低秩更新策略是Dion能够在大规模模型上高效运行的关键。
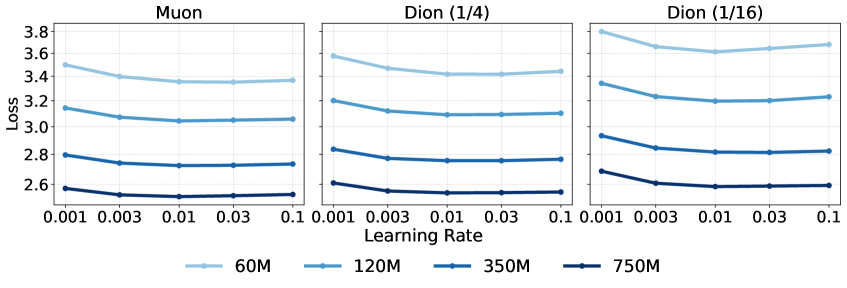
关键设计:Dion的关键设计包括:1. 动量缓冲的大小:需要根据具体模型和数据集进行调整,以平衡计算成本和更新质量;2. 摊销幂迭代的迭代次数:迭代次数越多,正交化更新的精度越高,但计算成本也越高;3. 秩分数参数:控制低秩更新的秩,需要在质量和成本之间进行权衡;4. 误差反馈机制:用于补偿低秩更新带来的误差,提高更新质量。
🖼️ 关键图片
📊 实验亮点
Dion在参数量从1.6亿到30亿的语言模型上进行了实验,结果表明,Dion能够显著减少大规模训练的实际耗时,同时保留了正交化更新的优势。与现有方法相比,Dion在保证模型性能的同时,降低了计算和通信成本,提高了训练效率。具体性能数据可在论文中查阅。
🎯 应用场景
Dion适用于大规模语言模型的训练,尤其是在分布式训练环境中。它可以加速模型收敛,提高训练稳定性,并降低训练成本。此外,Dion还可以应用于其他需要正交化更新的机器学习任务,例如图像识别、语音识别等。Dion的出现为下一代基础模型的训练提供了更高效的优化器选择。
📄 摘要(原文)
Orthonormalized updates accelerate training, improve stability, and enable robust hyperparameter transfer, but existing methods like Muon rely on dense matrix operations that clash with sharded weights in large-scale LLM training, causing high compute and communication cost. We introduce Dion (Distributed Orthonormalization), a scalable and efficient update rule that replaces Newton-Schulz iteration with amortized power iteration on a momentum buffer, avoiding full-matrix reconstruction and integrating cleanly with weight sharding. The rank-fraction parameter with error feedback enables low-rank updates that balance quality with significant cost savings. On language models from 160M to 3B parameters, Dion retains the benefits of orthonormalized updates, while markedly reducing wall-clock time at scale, making it a practical optimizer for next-generation foundation models. Code is available at: https://github.com/microsoft/dion/