A Reinforcement Learning Method for Environments with Stochastic Variables: Post-Decision Proximal Policy Optimization with Dual Critic Networks
作者: Leonardo Kanashiro Felizardo, Edoardo Fadda, Paolo Brandimarte, Emilio Del-Moral-Hernandez, Mariá Cristina Vasconcelos Nascimento
分类: cs.LG, cs.AI
发布日期: 2025-04-07 (更新: 2025-04-11)
备注: 12 pages, 4 figures. Accepted for presentation at IJCNN 2025
DOI: 10.1109/IJCNN64981.2025.11227565
💡 一句话要点
提出基于后决策状态和双重Critic网络的PDPPO算法,提升随机环境下强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 近端策略优化 后决策状态 双重Critic网络 随机环境 批量规模问题
📋 核心要点
- 传统强化学习方法在处理具有随机变量的环境时,面临维度灾难和价值函数估计不准确的挑战。
- PDPPO的核心思想是引入后决策状态,将状态转移过程分解为确定性和随机性两部分,降低问题维度。
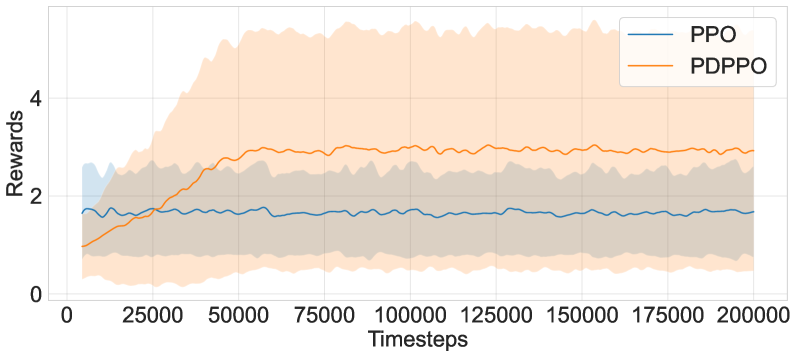
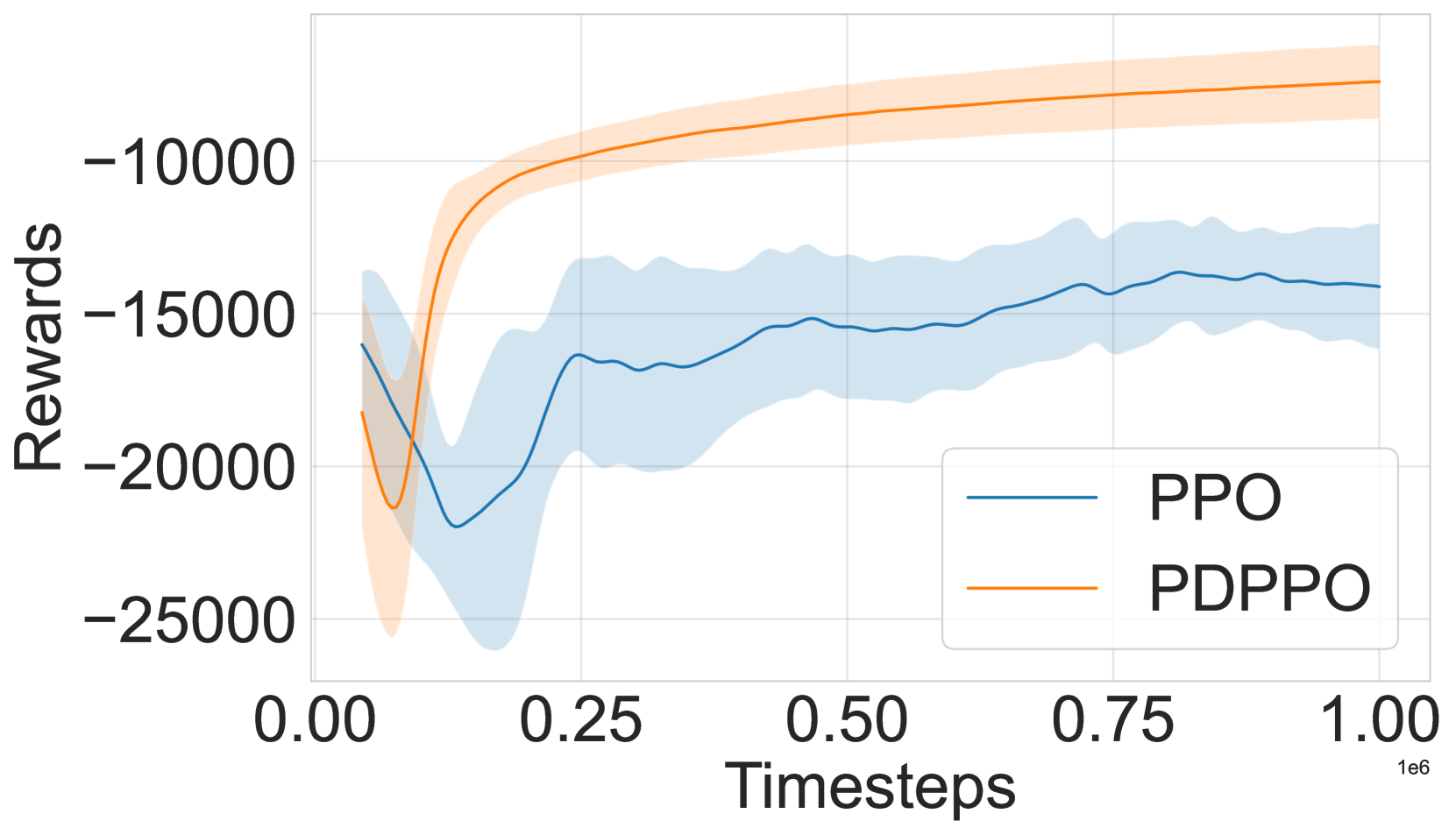
- 实验结果表明,PDPPO在随机环境中显著优于PPO,在特定场景中最大奖励接近PPO的两倍,且学习速度更快。
📝 摘要(中文)
本文提出了一种新的深度强化学习方法,即后决策近端策略优化(PDPPO),它是近端策略优化(PPO)的变体。PDPPO将状态转移过程分为两个步骤:确定性步骤产生后决策状态,随机步骤导致下一个状态。该方法结合了后决策状态和双重Critic网络,以降低问题的维度并提高价值函数估计的准确性。以批量规模问题为例,展示了这种动态性。批量规模问题的目标是在不确定的需求和成本参数下优化生产、交付履行和库存水平。本文评估了PDPPO在各种环境和配置中的性能。值得注意的是,在特定场景中,具有双重Critic架构的PDPPO实现了接近两倍于原始PPO的最大奖励,并且需要的episode迭代次数更少,在不同的初始化中表现出更快、更一致的学习。平均而言,PDPPO在状态转移中具有随机成分的环境中优于PPO。这些结果支持了使用后决策状态的优势。将这种后决策状态集成到价值函数近似中,可以在高维和随机环境中实现更明智、更有效的学习。
🔬 方法详解
问题定义:论文旨在解决强化学习在具有随机变量的环境中应用时,由于状态空间维度过高和价值函数估计不准确导致学习效率低下的问题。现有的PPO等方法难以有效处理这种随机性,导致策略学习不稳定,收敛速度慢。特别是在像批量规模问题这样的实际应用中,需求和成本的不确定性使得状态空间更加复杂,传统方法难以找到最优策略。
核心思路:论文的核心思路是将状态转移过程分解为两个步骤:首先执行一个确定性的动作,到达一个“后决策状态”(post-decision state),然后再经历一个随机过程到达下一个状态。通过引入后决策状态,可以将随机性从策略学习中解耦出来,从而降低问题的维度,简化价值函数的估计。
技术框架:PDPPO的整体框架仍然基于PPO的actor-critic结构。主要包括以下几个模块:策略网络(Actor),用于生成动作;两个价值网络(Critics),分别用于估计当前状态和后决策状态的价值;环境模型,用于模拟状态转移过程。算法流程如下:1. Actor根据当前状态生成动作;2. 执行动作,到达后决策状态;3. 环境根据后决策状态和随机变量转移到下一个状态;4. 两个Critic网络分别评估当前状态和后决策状态的价值;5. 使用PPO的策略更新方法更新Actor网络;6. 使用时序差分误差更新Critic网络。
关键创新:PDPPO的关键创新在于引入了后决策状态和双重Critic网络。后决策状态将状态转移过程中的确定性部分与随机性部分分离,降低了问题的维度。双重Critic网络分别估计当前状态和后决策状态的价值,从而更准确地评估策略的性能。与传统的PPO相比,PDPPO能够更好地处理具有随机变量的环境,提高学习效率和策略的稳定性。
关键设计:PDPPO的关键设计包括:1. 后决策状态的定义:需要根据具体问题定义合适的后决策状态,使其能够有效地捕捉状态转移过程中的确定性信息。2. 双重Critic网络的结构:两个Critic网络可以使用相同的网络结构,也可以使用不同的网络结构,具体取决于问题的复杂程度。3. 损失函数:Actor网络的损失函数仍然使用PPO的clip目标函数。Critic网络的损失函数使用时序差分误差,并可以考虑使用不同的权重来平衡两个Critic网络的贡献。4. 超参数:需要仔细调整PPO的超参数,例如学习率、clip范围、折扣因子等,以获得最佳性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在批量规模问题等随机环境中,PDPPO算法显著优于传统的PPO算法。在特定场景中,具有双重Critic架构的PDPPO实现了接近两倍于原始PPO的最大奖励。此外,PDPPO需要的episode迭代次数更少,在不同的初始化中表现出更快、更一致的学习。这些结果验证了后决策状态和双重Critic网络在处理随机环境中的有效性。
🎯 应用场景
PDPPO算法适用于各种具有随机变量的强化学习应用场景,例如供应链管理、库存控制、金融交易、机器人控制等。在这些场景中,环境的状态转移过程通常受到随机因素的影响,例如需求波动、市场变化、传感器噪声等。PDPPO能够有效地处理这些随机性,提高策略的鲁棒性和适应性,从而实现更好的决策效果。该研究的潜在价值在于提高复杂随机环境下决策系统的智能化水平。
📄 摘要(原文)
This paper presents Post-Decision Proximal Policy Optimization (PDPPO), a novel variation of the leading deep reinforcement learning method, Proximal Policy Optimization (PPO). The PDPPO state transition process is divided into two steps: a deterministic step resulting in the post-decision state and a stochastic step leading to the next state. Our approach incorporates post-decision states and dual critics to reduce the problem's dimensionality and enhance the accuracy of value function estimation. Lot-sizing is a mixed integer programming problem for which we exemplify such dynamics. The objective of lot-sizing is to optimize production, delivery fulfillment, and inventory levels in uncertain demand and cost parameters. This paper evaluates the performance of PDPPO across various environments and configurations. Notably, PDPPO with a dual critic architecture achieves nearly double the maximum reward of vanilla PPO in specific scenarios, requiring fewer episode iterations and demonstrating faster and more consistent learning across different initializations. On average, PDPPO outperforms PPO in environments with a stochastic component in the state transition. These results support the benefits of using a post-decision state. Integrating this post-decision state in the value function approximation leads to more informed and efficient learning in high-dimensional and stochastic environments.