Pr$εε$mpt: Sanitizing Sensitive Prompts for LLMs
作者: Amrita Roy Chowdhury, David Glukhov, Divyam Anshumaan, Prasad Chalasani, Nicolas Papernot, Somesh Jha, Mihir Bellare
分类: cs.CR, cs.LG
发布日期: 2025-04-07 (更新: 2025-08-15)
💡 一句话要点
Pr$εε$mpt:一种针对LLM的敏感提示词清洗系统,保护用户隐私。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 隐私保护 提示词清洗 格式保留加密 差分隐私 LLM安全 敏感信息处理
📋 核心要点
- 现有LLM推理服务存在隐私泄露风险,用户输入提示中的敏感信息可能被不当利用。
- Pr$εε$mpt通过提示词清洗器,对敏感token进行转换,从而保护用户隐私,同时尽量保持LLM的响应质量。
- 实验表明,Pr$εε$mpt在提供隐私保护的同时,相比于未清洗的提示词,仍能保持较高的实用性,并优于现有方法。
📝 摘要(中文)
大型语言模型(LLMs)的兴起带来了新的隐私挑战,尤其是在推理过程中,提示词中的敏感信息可能会暴露给专有的LLM API。本文旨在解决在保持响应质量的同时,正式保护提示词中包含的敏感信息的问题。为此,首先,我们引入了一种密码学启发的提示词清洗器的概念,该清洗器转换输入提示词以保护其敏感token。其次,我们提出了Pr$εε$mpt,这是一个实现提示词清洗器的新颖系统。Pr$εε$mpt将敏感token分为两种类型:(1)LLM的响应仅依赖于格式的token(例如,SSN、信用卡号),我们使用格式保留加密(FPE);(2)响应依赖于特定值的token(例如,年龄、工资),我们应用度量差分隐私(mDP)。我们的评估表明,与未清洗的提示词相比,Pr$εε$mpt是一种实现有意义的隐私保证的实用方法,同时保持了较高的效用,并且优于先前的方法。
🔬 方法详解
问题定义:论文旨在解决LLM推理过程中,用户输入的prompt中包含的敏感信息泄露问题。现有的方法要么无法提供有效的隐私保护,要么会严重影响LLM的输出质量,导致实用性降低。因此,需要一种既能保护隐私,又能保持LLM输出质量的prompt清洗方法。
核心思路:论文的核心思路是根据敏感信息的类型,采用不同的隐私保护机制。对于格式敏感的信息(如身份证号),采用格式保留加密(FPE),保证加密后的数据仍然符合原始格式,从而避免影响LLM的解析。对于数值敏感的信息(如年龄、工资),采用度量差分隐私(mDP),通过添加噪声来保护隐私,同时控制噪声的大小,以尽量减少对LLM输出质量的影响。
技术框架:Pr$εε$mpt系统主要包含以下几个模块:1) 敏感信息识别模块:识别prompt中的敏感token。2) 类型判断模块:判断敏感token的类型(格式敏感或数值敏感)。3) 清洗模块:根据敏感token的类型,采用FPE或mDP进行清洗。4) LLM推理模块:将清洗后的prompt输入LLM进行推理。5) 结果后处理模块:对LLM的输出进行后处理,例如解密FPE加密的数据。
关键创新:论文的关键创新在于提出了一个针对LLM prompt的隐私保护框架,并根据敏感信息的类型,采用了不同的隐私保护机制。这种方法既能提供有效的隐私保护,又能尽量保持LLM的输出质量。与现有方法相比,Pr$εε$mpt能够更好地平衡隐私保护和实用性。
关键设计:在FPE方面,论文采用了标准的FPE算法,并根据不同的敏感信息类型,选择了合适的加密参数。在mDP方面,论文采用了高斯机制,并根据隐私预算和敏感度,计算了合适的噪声大小。此外,论文还设计了一套评估指标,用于评估Pr$εε$mpt的隐私保护效果和实用性。
🖼️ 关键图片
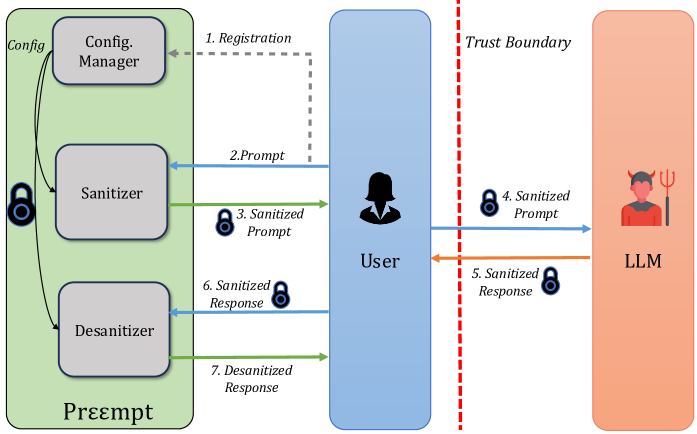
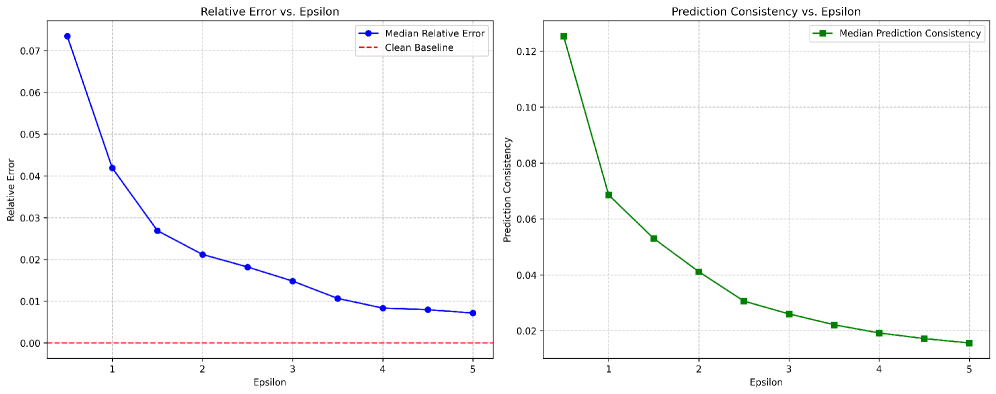
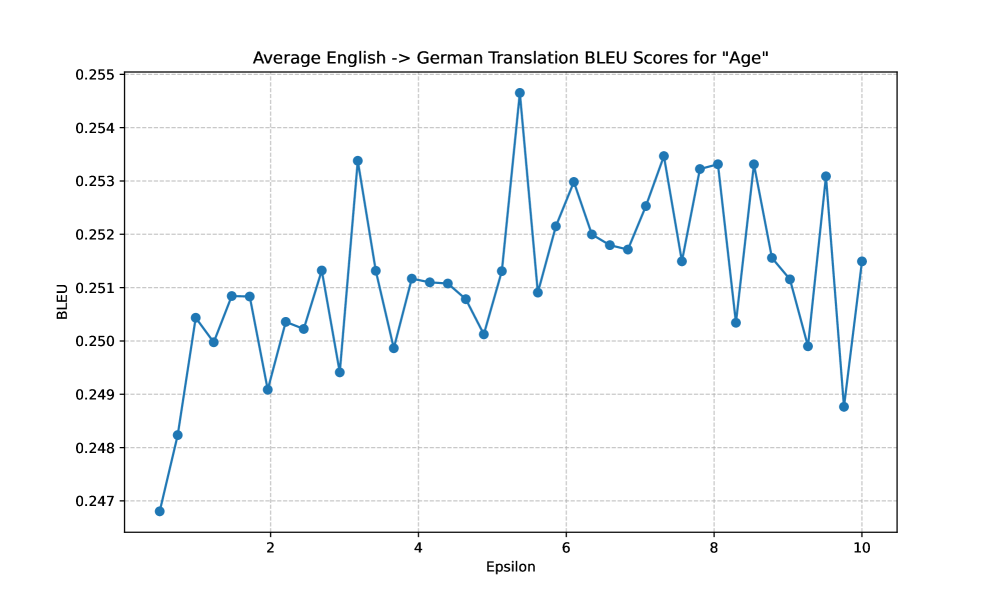
📊 实验亮点
实验结果表明,Pr$εε$mpt在提供有效隐私保护的同时,能够保持较高的实用性。与未清洗的prompt相比,Pr$εε$mpt的输出质量下降较小。此外,Pr$εε$mpt的性能优于现有的隐私保护方法,例如添加随机噪声或使用通用加密算法。具体的性能数据和提升幅度在论文中有详细的展示。
🎯 应用场景
Pr$εε$mpt可应用于各种需要使用LLM进行推理,但又涉及用户隐私的场景,例如医疗诊断、金融风控、法律咨询等。通过使用Pr$εε$mpt,可以在保护用户隐私的前提下,充分利用LLM的强大能力,为用户提供更好的服务。未来,该技术有望成为LLM应用的重要组成部分。
📄 摘要(原文)
The rise of large language models (LLMs) has introduced new privacy challenges, particularly during inference where sensitive information in prompts may be exposed to proprietary LLM APIs. In this paper, we address the problem of formally protecting the sensitive information contained in a prompt while maintaining response quality. To this end, first, we introduce a cryptographically inspired notion of a prompt sanitizer which transforms an input prompt to protect its sensitive tokens. Second, we propose Pr$εε$mpt, a novel system that implements a prompt sanitizer. Pr$εε$mpt categorizes sensitive tokens into two types: (1) those where the LLM's response depends solely on the format (such as SSNs, credit card numbers), for which we use format-preserving encryption (FPE); and (2) those where the response depends on specific values, (such as age, salary) for which we apply metric differential privacy (mDP). Our evaluation demonstrates that Pr$εε$mpt is a practical method to achieve meaningful privacy guarantees, while maintaining high utility compared to unsanitized prompts, and outperforming prior methods