Mixture-of-Personas Language Models for Population Simulation
作者: Ngoc Bui, Hieu Trung Nguyen, Shantanu Kumar, Julian Theodore, Weikang Qiu, Viet Anh Nguyen, Rex Ying
分类: cs.LG, cs.CL
发布日期: 2025-04-07
💡 一句话要点
提出混合角色语言模型(MoP)用于人口行为模拟,无需微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 行为模拟 人口建模 概率提示 混合模型
📋 核心要点
- 预训练LLM难以捕捉目标人群的行为多样性,限制了其在行为模拟中的应用。
- MoP通过概率提示方法,将LLM响应与目标人群对齐,实现行为多样性模拟。
- 实验表明,MoP在合成数据生成任务中,对齐性和多样性指标均优于其他方法。
📝 摘要(中文)
大型语言模型(LLM)的进步推动了其在各个领域的应用,例如人类行为模拟。在这些应用中,LLM可以增强社会科学研究和机器学习模型训练中人类生成的数据。然而,由于个体和群体之间固有的差异,预训练的LLM通常无法捕捉目标人群的行为多样性。为了解决这个问题,我们提出了一种名为“混合角色”(MoP)的概率提示方法,该方法使LLM的响应与目标人群保持一致。MoP是一个上下文混合模型,其中每个组件都是一个LM代理,其特征在于角色和代表亚群行为的范例。根据学习到的混合权重随机选择角色和范例,以在模拟过程中引发不同的LLM响应。MoP具有灵活性,无需模型微调,并且可以在基础模型之间转移。合成数据生成的实验表明,MoP在对齐和多样性指标方面优于竞争方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在人口行为模拟中,无法有效捕捉目标人群行为多样性的问题。现有的预训练语言模型通常缺乏对特定人群行为模式的理解,导致模拟结果与真实情况存在偏差。这种偏差会影响社会科学研究和机器学习模型训练的准确性。
核心思路:论文的核心思路是利用“混合角色”(Mixture of Personas, MoP) 的概率提示方法,通过组合不同的角色和行为范例,引导LLM生成更具多样性和代表性的响应。MoP将目标人群分解为多个亚群,每个亚群由一个角色和一个行为范例代表。通过学习不同角色和范例的混合权重,MoP可以根据目标人群的分布,生成符合特定情境的行为模拟。
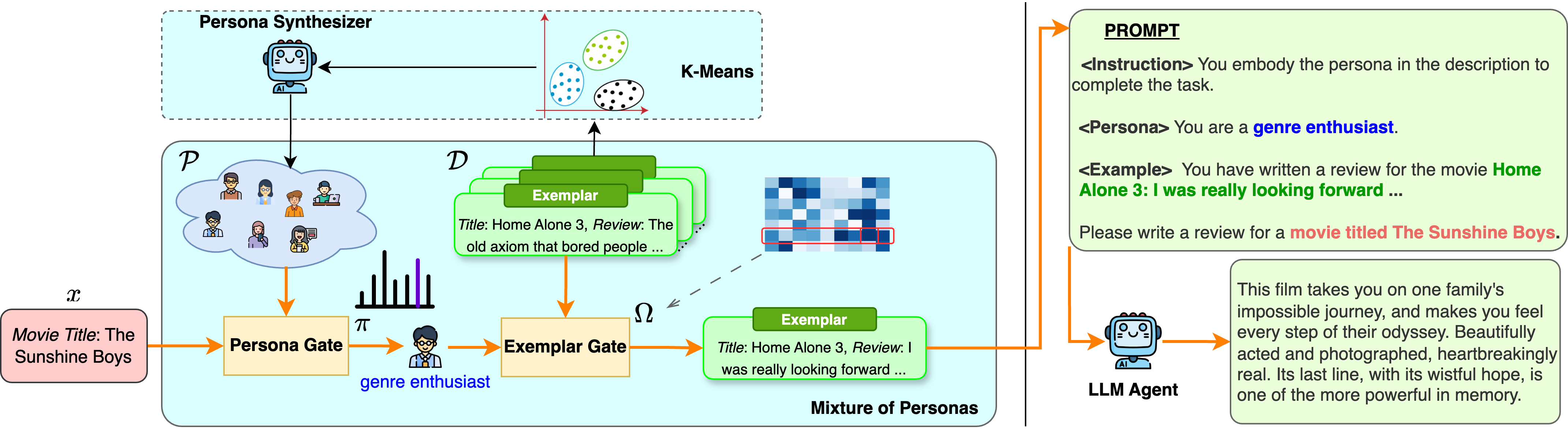
技术框架:MoP是一个上下文混合模型,其主要流程如下: 1. 角色定义:为目标人群定义多个角色,每个角色代表一个特定的亚群。 2. 范例选择:为每个角色选择一个或多个行为范例,这些范例可以是真实数据或人工生成的数据。 3. 混合权重学习:学习不同角色和范例的混合权重,以反映目标人群的分布。 4. 概率提示:在模拟过程中,根据学习到的混合权重,随机选择一个角色和一个范例,作为LLM的提示。 5. 响应生成:LLM根据提示生成响应,模拟该角色在该情境下的行为。
关键创新:MoP的关键创新在于其概率提示方法,它允许LLM在模拟过程中动态地选择不同的角色和范例,从而生成更具多样性和代表性的响应。与传统的提示方法相比,MoP不需要对LLM进行微调,并且可以灵活地应用于不同的基础模型。此外,MoP通过学习混合权重,可以更好地捕捉目标人群的分布,从而提高模拟的准确性。
关键设计:MoP的关键设计包括: 1. 角色和范例的选择:角色和范例的选择需要根据目标人群的特点进行 carefully 设计,以确保其能够代表不同的亚群。 2. 混合权重的学习:混合权重的学习可以使用多种方法,例如最大似然估计或贝叶斯推断。论文中使用的具体方法未知。 3. 提示的构建:提示的构建需要将角色和范例的信息有效地传递给LLM,以引导其生成符合特定情境的响应。具体提示方式未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MoP在合成数据生成任务中,对齐性和多样性指标均优于其他基线方法。具体性能数据未知,但论文强调MoP能够更好地捕捉目标人群的行为多样性,并生成更具代表性的模拟数据。MoP无需模型微调,使其更易于部署和应用。
🎯 应用场景
MoP可应用于社会科学研究、市场营销、公共政策制定等领域。例如,可以模拟不同人群对特定政策的反应,预测市场趋势,或评估广告效果。通过更准确地模拟人类行为,MoP有助于更好地理解社会现象,并为决策提供更可靠的依据。未来,MoP可以与其他技术结合,例如强化学习,以实现更复杂的行为模拟。
📄 摘要(原文)
Advances in Large Language Models (LLMs) paved the way for their emerging applications in various domains, such as human behavior simulations, where LLMs could augment human-generated data in social science research and machine learning model training. However, pretrained LLMs often fail to capture the behavioral diversity of target populations due to the inherent variability across individuals and groups. To address this, we propose \textit{Mixture of Personas} (MoP), a \textit{probabilistic} prompting method that aligns the LLM responses with the target population. MoP is a contextual mixture model, where each component is an LM agent characterized by a persona and an exemplar representing subpopulation behaviors. The persona and exemplar are randomly chosen according to the learned mixing weights to elicit diverse LLM responses during simulation. MoP is flexible, requires no model finetuning, and is transferable across base models. Experiments for synthetic data generation show that MoP outperforms competing methods in alignment and diversity metrics.