Playing Non-Embedded Card-Based Games with Reinforcement Learning
作者: Tianyang Wu, Lipeng Wan, Yuhang Wang, Qiang Wan, Xuguang Lan
分类: cs.LG
发布日期: 2025-04-07
备注: Match videos: https://www.bilibili.com/video/BV1xn4y1R7GQ, All code: https://github.com/wty-yy/katacr, Detection dataset: https://github.com/wty-yy/Clash-Royale-Detection-Dataset, Expert dataset: https://github.com/wty-yy/Clash-Royale-Replay-Dataset
期刊: Intelligent Robotics and Applications. ICIRA 2024. Lecture Notes in Computer Science, vol 15206. Springer, Singapore (2025)
DOI: 10.1007/978-981-96-0792-1_20
🔗 代码/项目: GITHUB
💡 一句话要点
提出非嵌入式强化学习策略,解决视觉输入下皇室战争实时对战问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 非嵌入式AI 强化学习 视觉输入 对象检测 皇室战争
📋 核心要点
- 现有游戏AI通常以嵌入式方式开发,直接访问游戏状态,与人类玩家依赖视觉输入存在差异,导致不公平竞争。
- 论文提出一种非嵌入式离线强化学习训练策略,利用视觉输入实现皇室战争的实时自主对战。
- 通过生成式对象检测数据集训练,结合对象检测和OCR模型提取特征,成功在移动设备上击败内置AI对手。
📝 摘要(中文)
本文针对游戏AI领域,特别是卡牌RTS游戏,提出了一个非嵌入式的强化学习训练策略,旨在解决现有AI通常直接访问游戏状态信息,与依赖视觉数据的人类玩家竞争不公平的问题。该方法使用视觉输入,实现了皇室战争的实时自主游戏。由于缺乏该游戏的对象检测数据集,作者设计了一个高效的生成式对象检测数据集用于训练。通过使用最先进的对象检测和光学字符识别模型提取特征,该方法能够在移动设备上实现实时的图像采集、感知特征融合、决策和控制,并成功击败了内置的AI对手。所有代码已开源。
🔬 方法详解
问题定义:现有游戏AI通常以嵌入式方式运行,直接访问游戏内部状态,这与人类玩家通过视觉信息进行决策的方式不同。这种直接访问导致AI在信息获取上具有优势,造成不公平竞争。因此,需要开发一种非嵌入式的AI,仅通过视觉输入进行游戏,但卡牌RTS游戏具有复杂特征和庞大的状态空间,使得开发此类AI极具挑战。
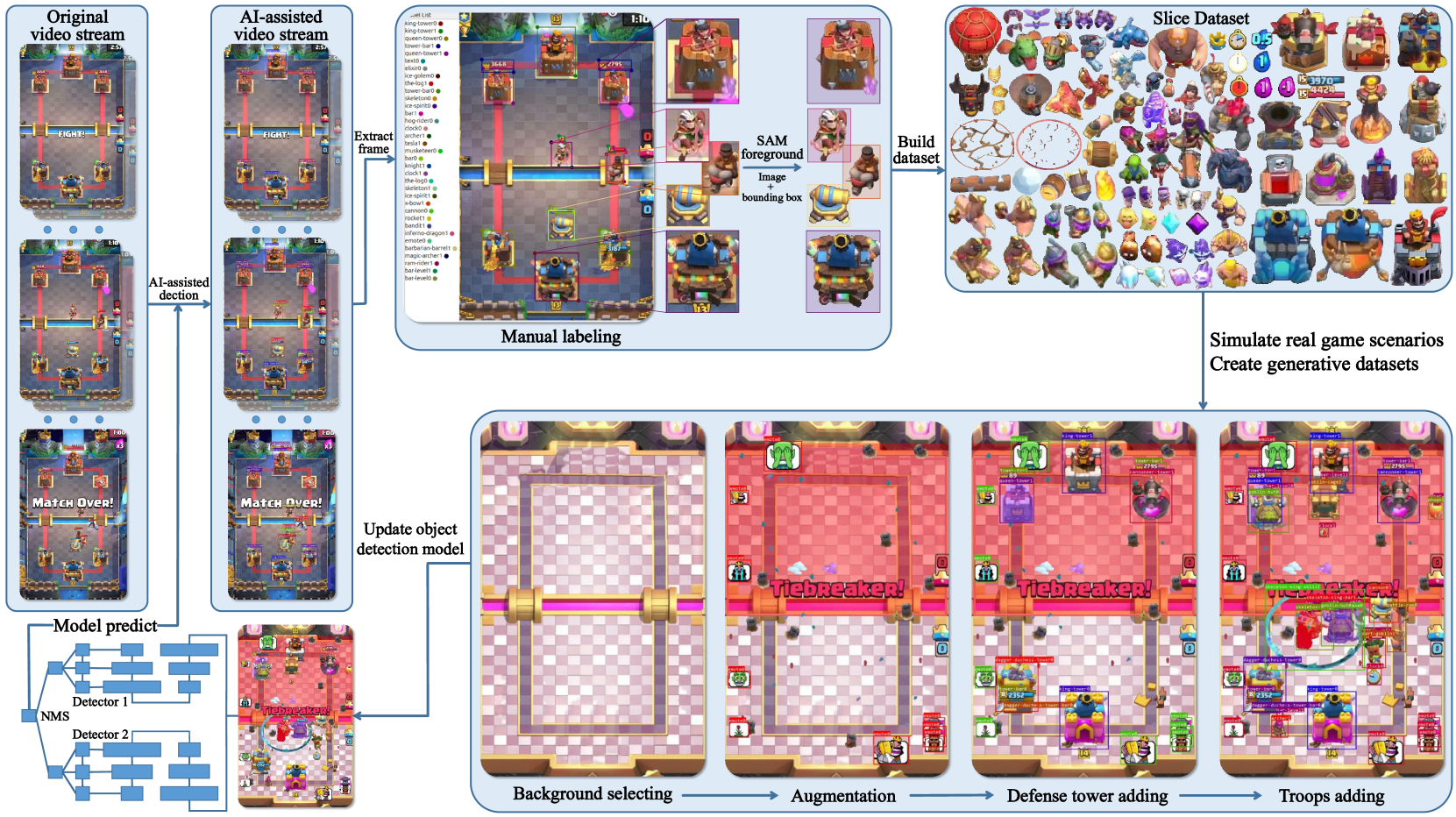
核心思路:论文的核心思路是利用离线强化学习,从视觉输入中学习游戏策略。通过模仿人类玩家的视觉感知方式,AI能够更好地理解游戏状态,并做出相应的决策。为了解决缺乏训练数据的问题,论文提出了一种生成式对象检测数据集的构建方法。
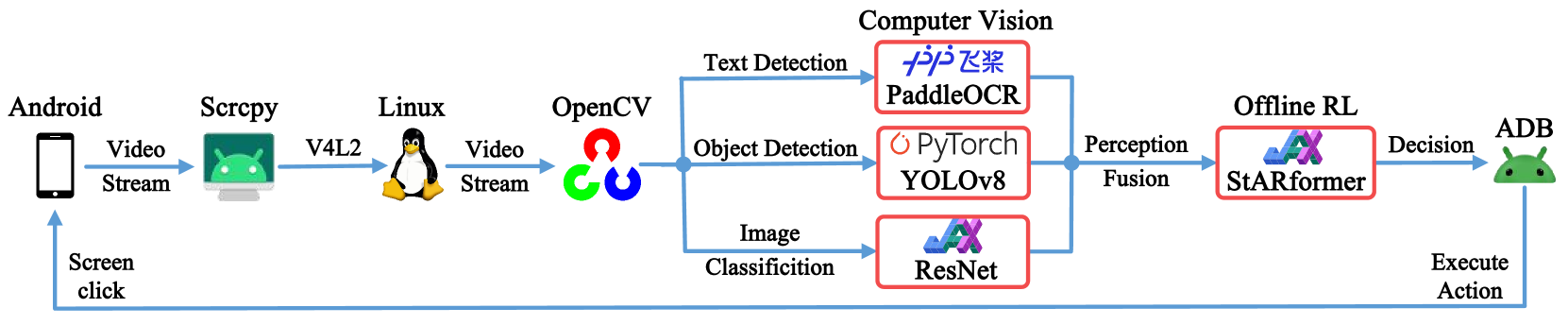
技术框架:整体框架包括以下几个主要阶段:1) 图像采集:从移动设备实时获取游戏画面。2) 感知特征提取:利用对象检测模型识别游戏中的关键元素(如卡牌、单位等),并使用OCR模型识别文本信息(如费用、生命值等)。3) 特征融合:将提取的视觉特征进行融合,形成对当前游戏状态的完整表示。4) 决策:使用强化学习模型,根据当前状态选择最优的行动。5) 控制:将选择的行动转化为游戏操作,并发送到游戏客户端。
关键创新:论文的关键创新在于:1) 提出了一种非嵌入式的强化学习训练策略,使AI能够仅通过视觉输入进行游戏。2) 设计了一种高效的生成式对象检测数据集,解决了缺乏训练数据的问题。3) 实现了在移动设备上的实时图像采集、感知特征融合、决策和控制。
关键设计:论文的关键设计包括:1) 生成式对象检测数据集的构建方法,通过程序自动生成大量的游戏截图,并标注其中的对象。2) 对象检测模型的选择,使用了当前最先进的模型,以提高检测精度。3) 强化学习模型的选择和训练,使用了离线强化学习算法,以提高训练效率和稳定性。4) 特征融合方法,将对象检测和OCR提取的特征进行有效融合,以提高状态表示的准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够在皇室战争中成功击败内置的AI对手,证明了非嵌入式强化学习策略的有效性。通过生成式对象检测数据集的训练,AI能够准确识别游戏中的关键元素,并做出合理的决策。该方法在移动设备上的实时性能也得到了验证,为实际应用奠定了基础。
🎯 应用场景
该研究成果可应用于开发更公平、更贴近人类玩家的游戏AI,提升游戏体验。此外,该方法在视觉输入下的决策能力,可以扩展到其他需要视觉感知的机器人控制任务中,例如自动驾驶、智能监控等。未来,该研究可以进一步探索如何利用更先进的深度学习技术,提高AI的感知和决策能力,使其在更复杂的游戏环境中表现出色。
📄 摘要(原文)
Significant progress has been made in AI for games, including board games, MOBA, and RTS games. However, complex agents are typically developed in an embedded manner, directly accessing game state information, unlike human players who rely on noisy visual data, leading to unfair competition. Developing complex non-embedded agents remains challenging, especially in card-based RTS games with complex features and large state spaces. We propose a non-embedded offline reinforcement learning training strategy using visual inputs to achieve real-time autonomous gameplay in the RTS game Clash Royale. Due to the lack of a object detection dataset for this game, we designed an efficient generative object detection dataset for training. We extract features using state-of-the-art object detection and optical character recognition models. Our method enables real-time image acquisition, perception feature fusion, decision-making, and control on mobile devices, successfully defeating built-in AI opponents. All code is open-sourced at https://github.com/wty-yy/katacr.