Human-Level Competitive Pokémon via Scalable Offline Reinforcement Learning with Transformers
作者: Jake Grigsby, Yuqi Xie, Justin Sasek, Steven Zheng, Yuke Zhu
分类: cs.LG
发布日期: 2025-04-06 (更新: 2025-07-30)
备注: Reinforcement Learning Conference 2025
💡 一句话要点
利用Transformer和可扩展离线强化学习,实现人类水平的宝可梦对战AI
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 宝可梦对战 离线强化学习 Transformer 序列建模 策略学习
📋 核心要点
- 现有宝可梦对战AI主要依赖启发式树搜索和在线自博弈,但计算成本高昂,且难以充分利用历史数据。
- 论文提出利用Transformer模型和大规模离线强化学习,直接从海量人类对战数据中学习策略,无需显式搜索。
- 实验表明,该方法训练的智能体在在线对战中达到人类玩家前10%的水平,超越了现有启发式搜索和LLM方法。
📝 摘要(中文)
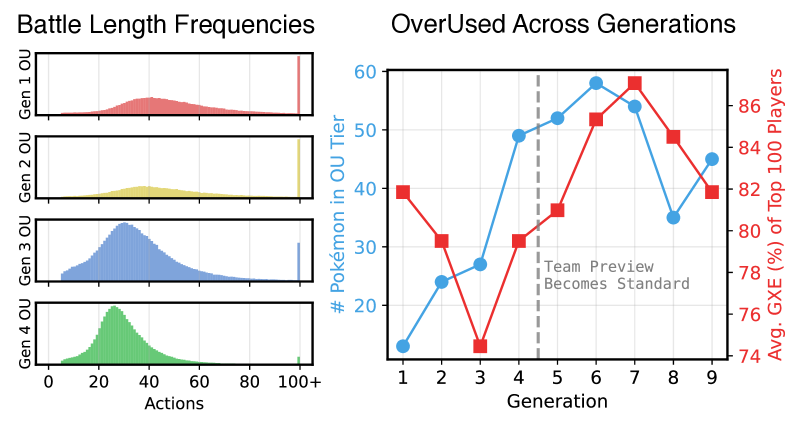
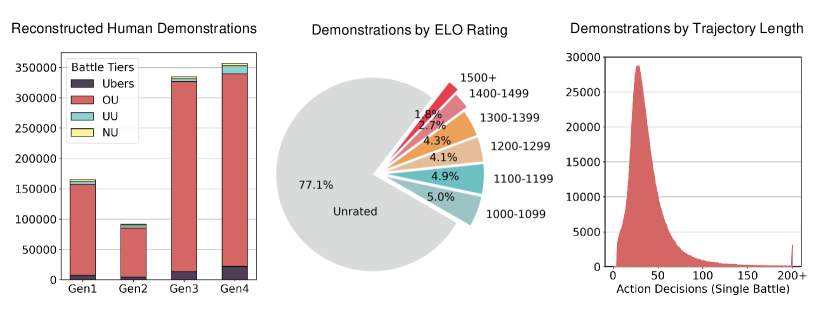
本文提出了一种利用大规模离线强化学习训练宝可梦对战AI的方法。通过构建一个从第三方视角对战日志中重构第一人称视角的流水线,解锁了一个包含十余年真实人类对战数据的数据集。该数据集支持黑盒方法,即训练大型序列模型,使其仅基于输入轨迹适应对手,并在不进行显式搜索的情况下选择动作。研究了从模仿学习到离线强化学习,再到在自博弈数据上进行离线微调的演进过程,应用于宝可梦四个最古老(且部分可观察)的游戏世代的硬核竞技环境。最终的智能体优于最近的大语言模型方法和强大的启发式搜索引擎,并在匿名在线对战中达到活跃玩家的前10%排名。所有智能体检查点、训练细节、数据集和基线均可在https://metamon.tech获取。
🔬 方法详解
问题定义:论文旨在解决宝可梦对战(Competitive Pokémon Singles, CPS)中,如何训练出能够达到甚至超越人类玩家水平的AI智能体的问题。现有方法,如启发式树搜索和在线自博弈,存在计算资源消耗大、难以充分利用历史数据等痛点。此外,宝可梦对战是一个信息不完全、回合数较多的复杂策略游戏,对AI的决策能力和适应性提出了很高的要求。
核心思路:论文的核心思路是利用大规模离线强化学习,直接从海量的人类对战数据中学习策略。通过将宝可梦对战视为一个序列决策问题,利用Transformer模型强大的序列建模能力,学习一个能够根据对手的行动轨迹进行自适应决策的策略。这种方法避免了显式的搜索过程,降低了计算成本,并能够充分利用历史数据。
技术框架:整体框架包括以下几个主要模块:1) 数据集构建:从第三方视角对战日志中重构第一人称视角数据,构建大规模离线数据集。2) 模型训练:首先使用模仿学习(Imitation Learning)初始化模型,然后使用离线强化学习(Offline RL)进一步提升策略,最后在自博弈数据上进行离线微调(Offline Fine-tuning)。3) 模型评估:在在线对战平台上进行匿名对战,评估智能体的性能。
关键创新:最重要的技术创新点在于利用Transformer模型和大规模离线强化学习,实现了一个端到端的宝可梦对战AI。与现有方法相比,该方法无需显式的搜索过程,降低了计算成本,并能够充分利用历史数据。此外,通过模仿学习、离线强化学习和离线微调的结合,有效地提升了智能体的性能。
关键设计:论文中关键的设计包括:1) 数据集构建:设计了一个从第三方视角日志中重构第一人称视角数据的流水线,保证了数据的质量和规模。2) 模型结构:使用Transformer模型作为策略网络,利用其强大的序列建模能力。3) 训练策略:采用模仿学习、离线强化学习和离线微调相结合的训练策略,有效地提升了智能体的性能。具体的离线强化学习算法未知,但推测使用了常见的算法如Behavior Cloning, CQL等。损失函数和网络结构细节未在摘要中详细说明,需要查阅原文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法训练的智能体在宝可梦四个最古老的游戏世代中均取得了优异的成绩。在在线对战中,该智能体能够达到活跃玩家的前10%排名,超越了现有启发式搜索和LLM方法。这些结果表明,该方法在宝可梦对战中具有很强的竞争力,并能够达到人类水平。
🎯 应用场景
该研究成果可应用于其他复杂策略游戏中,例如星际争霸、Dota等。此外,该方法在离线数据利用和序列决策方面具有一定的借鉴意义,可以推广到其他需要从历史数据中学习策略的场景,例如金融交易、推荐系统等。该研究也为AI在游戏领域的应用提供了新的思路,并推动了AI技术的发展。
📄 摘要(原文)
Competitive Pokémon Singles (CPS) is a popular strategy game where players learn to exploit their opponent based on imperfect information in battles that can last more than one hundred stochastic turns. AI research in CPS has been led by heuristic tree search and online self-play, but the game may also create a platform to study adaptive policies trained offline on large datasets. We develop a pipeline to reconstruct the first-person perspective of an agent from logs saved from the third-person perspective of a spectator, thereby unlocking a dataset of real human battles spanning more than a decade that grows larger every day. This dataset enables a black-box approach where we train large sequence models to adapt to their opponent based solely on their input trajectory while selecting moves without explicit search of any kind. We study a progression from imitation learning to offline RL and offline fine-tuning on self-play data in the hardcore competitive setting of Pokémon's four oldest (and most partially observed) game generations. The resulting agents outperform a recent LLM Agent approach and a strong heuristic search engine. While playing anonymously in online battles against humans, our best agents climb to rankings inside the top 10% of active players. All agent checkpoints, training details, datasets, and baselines are available at https://metamon.tech.