How Relevance Emerges: Interpreting LoRA Fine-Tuning in Reranking LLMs
作者: Atharva Nijasure, Tanya Chowdhury, James Allan
分类: cs.IR, cs.LG
发布日期: 2025-04-05 (更新: 2025-08-10)
备注: Extended Abstract
💡 一句话要点
探索LoRA微调在LLM重排序中的作用机制,揭示相关性信号的学习与应用方式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LoRA微调 大型语言模型 段落重排序 信息检索 相关性建模
📋 核心要点
- 现有方法在利用LLM进行段落重排序时,缺乏对LoRA微调机制的深入理解,难以解释相关性信号的学习过程。
- 通过行为探索和消融实验,研究不同LoRA配置对LLM重排序性能的影响,揭示关键层和投影的重要性。
- 实验结果表明,特定层和投影在LoRA微调中对相关性建模至关重要,为进一步研究LoRA的适应机制提供了依据。
📝 摘要(中文)
本文针对Passage Reranking任务,对LoRA微调的LLM进行行为探索,旨在理解大型语言模型如何学习和部署相关性信号。通过在MS MARCO数据集上,使用不同的LoRA配置对Mistral-7B、LLaMA3.1-8B和Pythia-6.9B进行微调,研究了相关性建模在不同checkpoint上的演变、LoRA秩(1、2、8、32)的影响,以及更新的MHA与MLP组件的相对重要性。消融实验揭示了LoRA变换中哪些层和投影对于重排序精度至关重要。这些发现为LoRA的适应机制提供了新的解释,为信息检索中更深入的机制研究奠定了基础。本文使用的所有模型均已共享。
🔬 方法详解
问题定义:论文旨在理解LoRA微调如何影响大型语言模型(LLM)在段落重排序任务中的表现。现有方法缺乏对LLM如何学习和应用相关性信号的深入理解,无法解释LoRA微调的具体作用机制。这阻碍了对LLM在信息检索领域应用的进一步优化。
核心思路:论文的核心思路是通过行为探索和消融实验,分析不同LoRA配置(如LoRA秩、更新的MHA与MLP组件)对LLM重排序性能的影响。通过观察相关性建模在不同训练阶段的演变,以及关键层和投影的重要性,揭示LoRA微调在LLM中学习和部署相关性信号的方式。
技术框架:论文的技术框架主要包括以下几个阶段:1) 选择预训练的LLM(Mistral-7B、LLaMA3.1-8B、Pythia-6.9B);2) 在MS MARCO数据集上,使用不同的LoRA配置对LLM进行微调;3) 在不同的checkpoint上评估重排序性能;4) 进行消融实验,分析不同层和投影对重排序精度的影响;5) 分析实验结果,揭示LoRA微调的作用机制。
关键创新:论文的关键创新在于:1) 对LoRA微调在LLM重排序中的作用机制进行了深入的行为探索,揭示了相关性信号的学习和应用方式;2) 通过消融实验,确定了LoRA变换中对重排序精度至关重要的层和投影;3) 提供了关于LoRA适应机制的新解释,为信息检索领域更深入的机制研究奠定了基础。
关键设计:论文的关键设计包括:1) 选择了不同规模和架构的LLM(Mistral-7B、LLaMA3.1-8B、Pythia-6.9B),以验证结论的泛化性;2) 使用了不同的LoRA秩(1、2、8、32),以研究LoRA秩对重排序性能的影响;3) 对MHA和MLP组件进行了消融实验,以确定它们在LoRA微调中的相对重要性;4) 在MS MARCO数据集上进行了实验,该数据集是段落重排序任务的常用基准。
🖼️ 关键图片
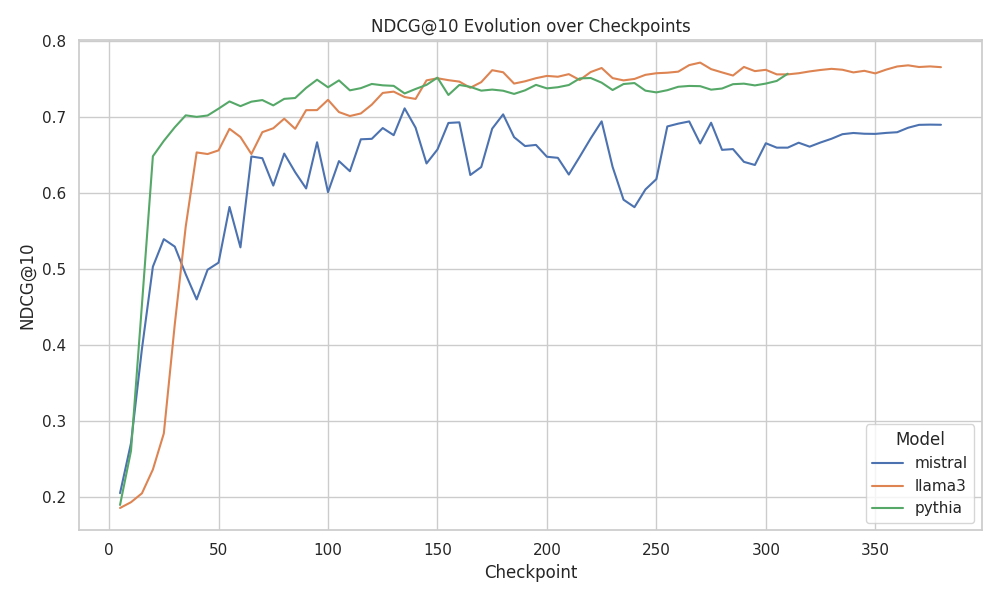
📊 实验亮点
论文通过在MS MARCO数据集上微调Mistral-7B、LLaMA3.1-8B和Pythia-6.9B等LLM,并进行消融实验,揭示了LoRA变换中对重排序精度至关重要的层和投影。实验结果表明,特定层和投影在LoRA微调中对相关性建模起着关键作用,为进一步优化LLM在信息检索领域的应用提供了重要依据。
🎯 应用场景
该研究成果可应用于提升搜索引擎、问答系统等信息检索系统的性能。通过深入理解LoRA微调机制,可以更有效地利用LLM进行段落重排序,提高检索结果的相关性和准确性。此外,该研究也为开发更高效的LLM微调方法提供了理论基础,具有重要的实际价值和未来影响。
📄 摘要(原文)
We conduct a behavioral exploration of LoRA fine-tuned LLMs for Passage Reranking to understand how relevance signals are learned and deployed by Large Language Models. By fine-tuning Mistral-7B, LLaMA3.1-8B, and Pythia-6.9B on MS MARCO under diverse LoRA configurations, we investigate how relevance modeling evolves across checkpoints, the impact of LoRA rank (1, 2, 8, 32), and the relative importance of updated MHA vs. MLP components. Our ablations reveal which layers and projections within LoRA transformations are most critical for reranking accuracy. These findings offer fresh explanations into LoRA's adaptation mechanisms, setting the stage for deeper mechanistic studies in Information Retrieval. All models used in this study have been shared.