OrbitZoo: Real Orbital Systems Challenges for Reinforcement Learning
作者: Alexandre Oliveira, Katarina Dyreby, Francisco Caldas, Cláudia Soares
分类: cs.LG, cs.MA
发布日期: 2025-04-05 (更新: 2025-10-14)
备注: Accepted at the 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
💡 一句话要点
OrbitZoo:基于高保真轨道环境的强化学习挑战平台,解决空间资源优化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 轨道动力学 多智能体系统 卫星自主运行 空间交通管理
📋 核心要点
- 现有强化学习框架在空间资源优化问题上,依赖于简化模型和耗时验证的定制环境,难以捕捉真实世界的复杂性。
- OrbitZoo构建于高保真行业标准库之上,提供真实数据生成,支持避碰和协同机动等场景,确保轨道动力学的鲁棒性和准确性。
- OrbitZoo环境通过与Starlink卫星星座的真实数据对比验证,实现了0.16%的平均绝对百分比误差,验证了其可靠性。
📝 摘要(中文)
日益增长的卫星和轨道碎片使得空间拥堵成为一个关键问题,威胁着卫星安全和可持续性。诸如避碰、保持轨道和轨道机动等挑战需要先进的技术来处理动态不确定性和多智能体交互。强化学习(RL)在该领域显示出潜力,能够为空间操作提供自适应、自主策略;然而,许多现有的RL框架依赖于从头开始构建的定制环境,这些环境通常使用简化的模型,并且需要大量时间来实现和验证轨道动力学,限制了它们充分捕捉真实世界复杂性的能力。为了解决这个问题,我们引入了OrbitZoo,这是一个通用的多智能体RL环境,它建立在高保真行业标准库之上,能够进行真实的数据生成,支持诸如避碰和协同机动等场景,并确保鲁棒和准确的轨道动力学。该环境针对真实的卫星星座Starlink进行了验证,与真实世界数据相比,实现了0.16%的平均绝对百分比误差(MAPE)。这种验证确保了生成高保真模拟和实现自主独立卫星操作的可靠性。
🔬 方法详解
问题定义:论文旨在解决空间资源日益拥堵带来的卫星安全和可持续性问题,具体挑战包括卫星避碰、轨道保持和轨道机动等。现有强化学习方法依赖于简化的环境模型,难以模拟真实空间环境的复杂性,并且环境构建和验证耗时,限制了算法的实际应用效果。
核心思路:论文的核心思路是构建一个高保真的多智能体强化学习环境,该环境基于行业标准库,能够准确模拟卫星轨道动力学和多智能体交互。通过高保真环境,可以训练出更鲁棒、更适应真实空间环境的强化学习策略。
技术框架:OrbitZoo环境的整体架构包含以下几个主要模块:1) 轨道动力学模拟模块,基于高保真行业标准库,模拟卫星的运动轨迹;2) 多智能体交互模块,模拟卫星之间的通信和协同;3) 奖励函数设计模块,根据任务目标(如避碰、轨道保持)设计合适的奖励函数;4) 强化学习算法集成模块,支持各种强化学习算法的训练和评估。
关键创新:OrbitZoo的关键创新在于其高保真度。与以往的简化环境相比,OrbitZoo能够更准确地模拟真实空间环境,从而训练出更有效的强化学习策略。此外,OrbitZoo还提供了一个通用的多智能体强化学习平台,方便研究人员进行算法开发和评估。
关键设计:OrbitZoo的关键设计包括:1) 轨道动力学模型的选择,采用高精度的轨道传播模型,考虑各种摄动因素的影响;2) 奖励函数的设计,需要仔细权衡各种因素,以引导智能体学习到期望的行为;3) 强化学习算法的选择,需要根据任务的特点选择合适的算法,例如,对于多智能体协作任务,可以选择多智能体强化学习算法。
🖼️ 关键图片

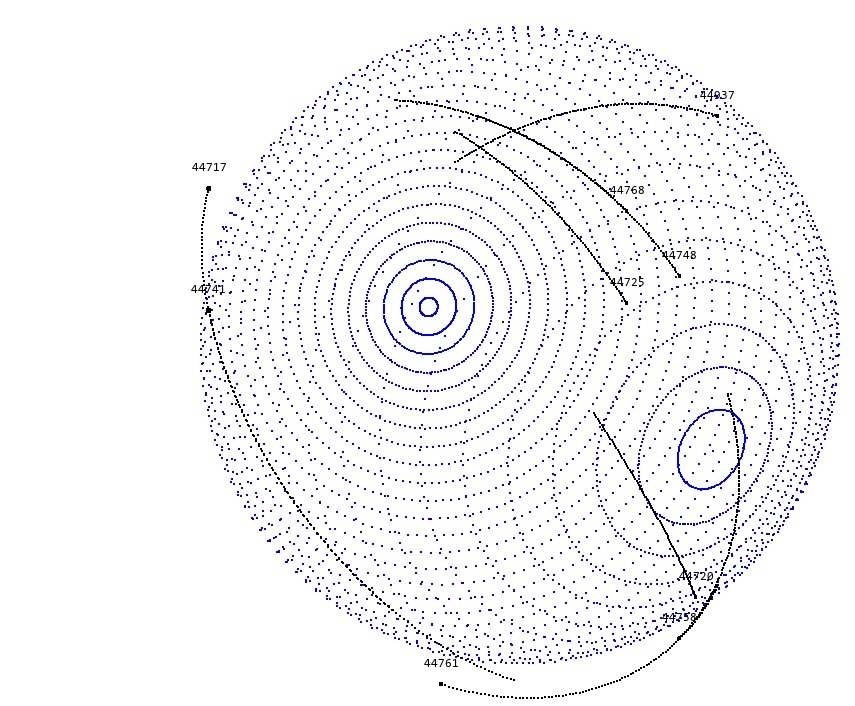
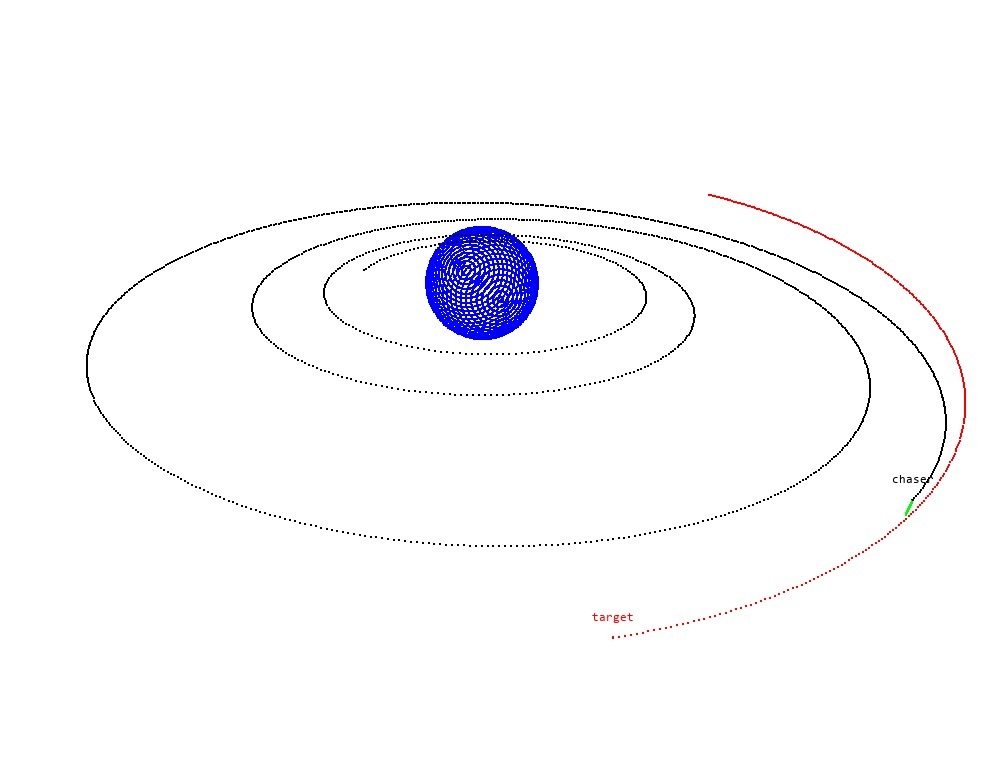
📊 实验亮点
OrbitZoo环境通过与Starlink卫星星座的真实数据进行对比验证,实现了0.16%的平均绝对百分比误差(MAPE)。这一结果表明,OrbitZoo能够准确模拟真实空间环境,为强化学习算法的训练和评估提供了可靠的基础。该验证结果显著,证明了OrbitZoo环境的高保真性。
🎯 应用场景
OrbitZoo具有广泛的应用前景,可用于卫星自主运行、空间交通管理、轨道碎片清除等领域。通过强化学习训练,卫星可以自主完成避碰、轨道保持等任务,提高运行效率和安全性。该环境还可以用于评估不同空间交通管理策略的效果,为决策者提供支持。此外,OrbitZoo还可以用于研究轨道碎片清除技术,为解决空间环境问题提供新的思路。
📄 摘要(原文)
The increasing number of satellites and orbital debris has made space congestion a critical issue, threatening satellite safety and sustainability. Challenges such as collision avoidance, station-keeping, and orbital maneuvering require advanced techniques to handle dynamic uncertainties and multi-agent interactions. Reinforcement learning (RL) has shown promise in this domain, enabling adaptive, autonomous policies for space operations; however, many existing RL frameworks rely on custom-built environments developed from scratch, which often use simplified models and require significant time to implement and validate the orbital dynamics, limiting their ability to fully capture real-world complexities. To address this, we introduce OrbitZoo, a versatile multi-agent RL environment built on a high-fidelity industry standard library, that enables realistic data generation, supports scenarios like collision avoidance and cooperative maneuvers, and ensures robust and accurate orbital dynamics. The environment is validated against a real satellite constellation, Starlink, achieving a Mean Absolute Percentage Error (MAPE) of 0.16% compared to real-world data. This validation ensures reliability for generating high-fidelity simulations and enabling autonomous and independent satellite operations.