SpecPipe: Accelerating Pipeline Parallelism-based LLM Inference with Speculative Decoding
作者: Haofei Yin, Mengbai Xiao, Tinghong Li, Xiao Zhang, Dongxiao Yu, Guanghui Zhang
分类: cs.LG
发布日期: 2025-04-05 (更新: 2025-08-29)
💡 一句话要点
SpecPipe:利用推测解码加速基于流水线并行的LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 流水线并行 推测解码 分布式推理 硬件加速
📋 核心要点
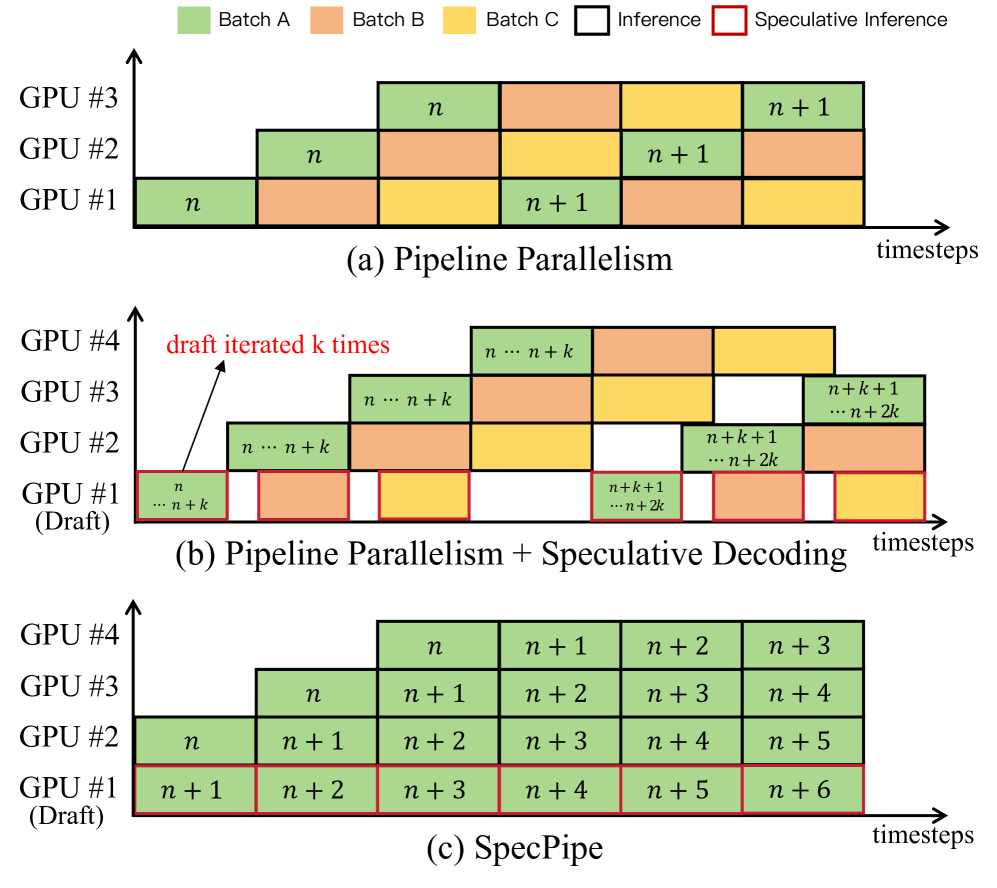
- 流水线并行是LLM分布式推理的有效方法,但高延迟限制了其应用,推测解码虽能提速,但硬件利用率和推测窗口仍有提升空间。
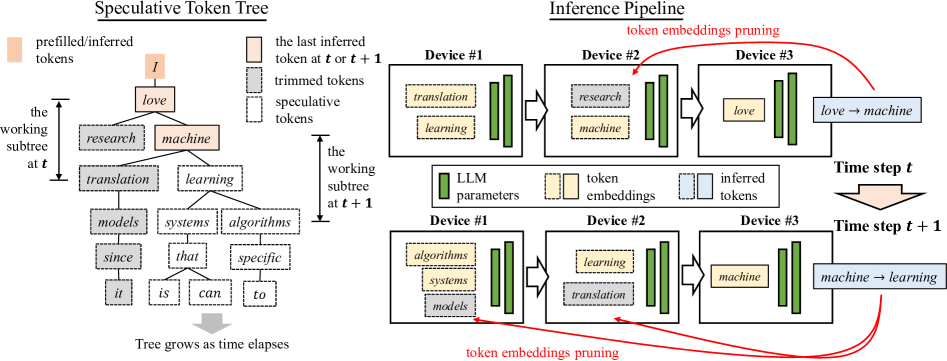
- SpecPipe借鉴指令流水线思想,通过动态推测token树逐步填充流水线,最大化硬件利用率,实现每个流水线步骤解码一个token。
- 实验结果表明,SpecPipe在单请求和多请求场景下均显著优于现有方法,有效降低了token间时间,提高了吞吐量。
📝 摘要(中文)
大型语言模型推理的需求正在快速增长。流水线并行为分布式推理提供了一种经济高效的部署策略,但存在服务延迟高的问题。将推测解码融入流水线并行可以提高性能,但仍面临硬件利用率低和推测窗口窄的挑战。受指令流水线中分支预测的启发,我们引入了SpecPipe,它逐步用请求的推测token填充流水线。通过最大化硬件利用率,理想情况下SpecPipe可以在每个流水线步骤解码一个token。具体来说,SpecPipe包含一个动态推测token树和一个流水线推理框架。该树动态地接受来自推测token源的token,并将token输出到推理流水线。由于我们的框架中放宽了推测窗口,因此集成了高精度草稿模型而无需微调。流水线推理框架遵循节点式计算、剪枝传播和节点间通信阶段。我们分别针对单请求和多请求推理实现了SpecPipe和带有动态批处理的变体SpecPipe-DB。在8级流水线上,SpecPipe在不同的单请求工作负载下,相比标准流水线并行,token间时间提高了4.19倍-5.53倍,相比之前的基于树的推测解码方法,提高了2.08倍-2.38倍。对于多请求工作负载,SpecPipe-DB实现了比vLLM高1.64倍-2.08倍的吞吐量和低1.61倍-2.06倍的token间时间。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理中,基于流水线并行策略部署时,服务延迟过高的问题。现有的流水线并行方法虽然能有效利用分布式资源,但由于硬件利用率不足和推测解码窗口较窄,导致推理速度受限。
核心思路:论文的核心思路是借鉴指令流水线中的分支预测技术,设计一种名为SpecPipe的框架,该框架通过动态地用推测token填充流水线,从而最大化硬件利用率,并实现每个流水线步骤解码一个token。这种方法旨在提高LLM推理的吞吐量并降低延迟。
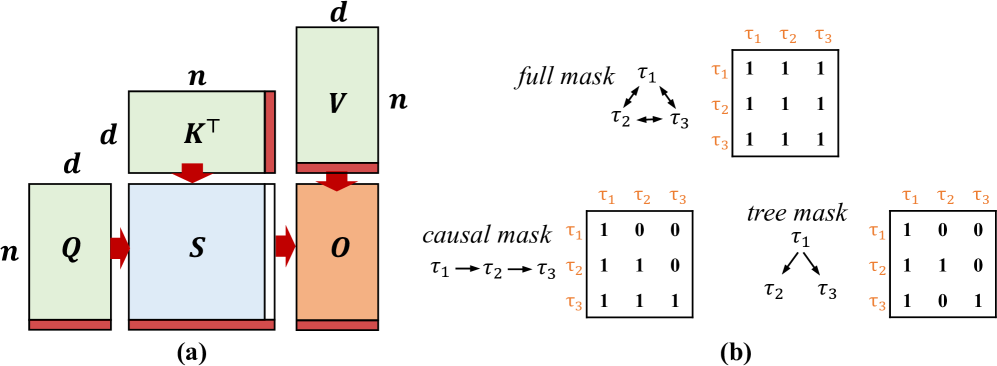
技术框架:SpecPipe框架主要包含两个核心组件:动态推测token树和流水线推理框架。动态推测token树负责从推测token源接收token,并将其输出到推理流水线。流水线推理框架则遵循节点式计算、剪枝传播和节点间通信等阶段,以实现高效的并行推理。SpecPipe还提出了SpecPipe-DB,一个带有动态批处理的变体,用于处理多请求推理场景。
关键创新:SpecPipe的关键创新在于其动态推测token树的设计,它允许框架在更大的推测窗口内工作,从而提高了推测解码的效率。此外,SpecPipe还集成了高精度的草稿模型,而无需进行额外的微调,这简化了部署过程并提高了性能。与现有方法相比,SpecPipe能够更有效地利用硬件资源,并实现更高的推理速度。
关键设计:SpecPipe的关键设计包括动态推测token树的结构和算法,以及流水线推理框架中的节点式计算、剪枝传播和节点间通信机制。论文中可能涉及一些关键参数的设置,例如推测token树的深度和宽度,以及剪枝策略的阈值等。此外,草稿模型的选择和集成方式也是影响SpecPipe性能的重要因素。具体的损失函数和网络结构细节可能取决于所使用的LLM和草稿模型。
🖼️ 关键图片
📊 实验亮点
SpecPipe在8级流水线上,相比标准流水线并行,在不同的单请求工作负载下,token间时间降低了4.19倍-5.53倍。与之前的基于树的推测解码方法相比,token间时间降低了2.08倍-2.38倍。对于多请求工作负载,SpecPipe-DB实现了比vLLM高1.64倍-2.08倍的吞吐量和低1.61倍-2.06倍的token间时间。这些数据表明SpecPipe在加速LLM推理方面具有显著优势。
🎯 应用场景
SpecPipe可应用于各种需要高性能LLM推理的场景,例如在线对话系统、智能客服、内容生成和机器翻译等。通过提高推理速度和降低延迟,SpecPipe能够提升用户体验,并降低部署成本。该研究对于推动LLM在实际应用中的普及具有重要意义。
📄 摘要(原文)
The demand for large language model inference is rapidly increasing. Pipeline parallelism offers a cost-effective deployment strategy for distributed inference but suffers from high service latency. While incorporating speculative decoding to pipeline parallelism improves performance, it still faces challenges of low hardware utilization and narrow speculative window. Inspired by branch prediction in instruction pipelining, we introduce SpecPipe, which fills the pipeline with speculative tokens of a request step-by-step. By maximizing the hardware utilization, SpecPipe decodes one token per pipeline step ideally. Specifically, SpecPipe comprises a dynamic speculative token tree and a pipelined inference framework. The tree dynamically accepts tokens from a speculative token source and outputs the tokens to the inference pipeline. Since the speculative window relaxed in our framework, a high-accuracy draft model is integrated without fine-tuning. The pipeline inference framework follows node-wise computation, pruning propagation, and inter-node communication stages. We implement SpecPipe and a variant SpecPipe-DB with dynamic batching for single- and multi-request inference, respectively. On an 8-stage pipeline, SpecPipe improves time between tokens on diverse single-request workloads by $4.19\times$-$5.53\times$ over standard pipeline parallelism and by $2.08\times$-$2.38\times$ over prior tree-based speculative decoding methods. For multi-request workloads, SpecPipe-DB achieves $1.64\times$-$2.08\times$ higher throughput and $1.61\times$-$2.06\times$ lower time between tokens than vLLM.