Foundation Models for Time Series: A Survey
作者: Siva Rama Krishna Kottapalli, Karthik Hubli, Sandeep Chandrashekhara, Garima Jain, Sunayana Hubli, Gayathri Botla, Ramesh Doddaiah
分类: cs.LG, cs.AI
发布日期: 2025-04-05
💡 一句话要点
综述Transformer时间序列基础模型,提出新颖分类法并分析未来研究方向。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列分析 Transformer模型 基础模型 预训练模型 深度学习 模型综述 时间序列预测
📋 核心要点
- 现有时间序列分析方法在处理复杂、高维数据时存在局限性,泛化能力不足。
- 论文对基于Transformer的时间序列基础模型进行全面综述,并提出新的分类体系。
- 该综述旨在为研究人员和从业者提供参考,促进时间序列建模领域未来的研究。
📝 摘要(中文)
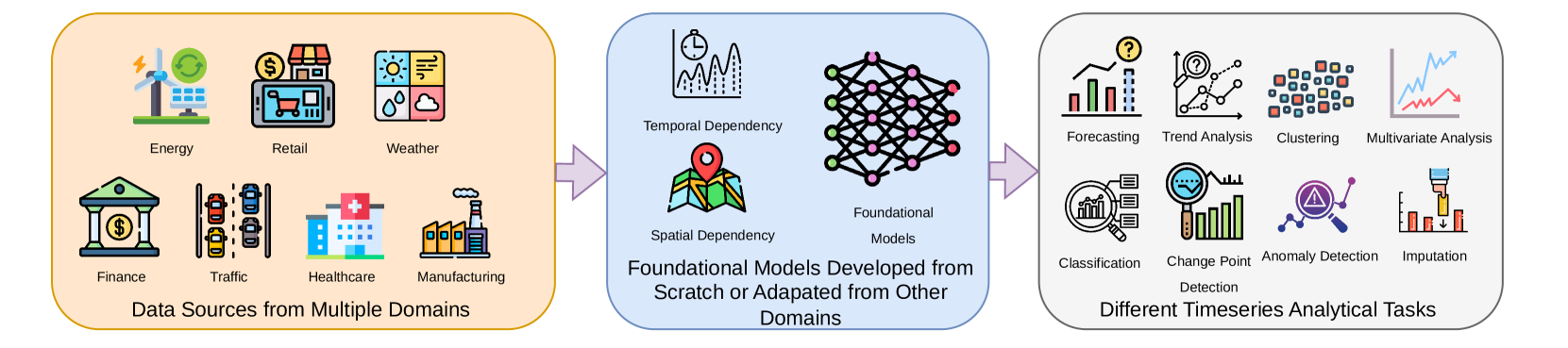
本综述全面概述了当前基于Transformer的时间序列基础模型,这些模型在时间序列分析任务中表现出前所未有的能力,例如预测、异常检测、分类和趋势分析等。我们提出了一种新颖的分类方法,从多个维度对这些模型进行分类。具体来说,我们根据架构设计对模型进行分类,区分了利用基于patch表示的模型和直接处理原始序列的模型。该分类法还包括模型提供概率预测还是确定性预测,以及模型是设计用于单变量时间序列还是可以开箱即用地处理多变量时间序列。此外,该分类法还包括模型规模和复杂性,突出了轻量级架构和大型基础模型之间的差异。本综述的一个独特之处在于,它按训练阶段采用的目标函数类型进行分类。通过综合这些观点,本综述为研究人员和从业人员提供了一个资源,深入了解了当前的趋势,并确定了基于Transformer的时间序列建模未来研究的有希望的方向。
🔬 方法详解
问题定义:现有时间序列分析方法,尤其是在处理复杂、高维时间序列数据时,面临着泛化能力不足、难以捕捉长期依赖关系等挑战。传统的统计模型和浅层机器学习方法难以充分利用大规模时间序列数据进行有效学习。
核心思路:本综述的核心思路是对基于Transformer的时间序列基础模型进行系统性的梳理和分类,从而帮助研究人员和从业者更好地理解这些模型的优势和局限性,并为未来的研究方向提供指导。通过对不同模型的架构设计、预测类型、数据处理方式和训练目标进行分类,揭示了不同模型之间的内在联系和差异。
技术框架:该综述没有提出新的模型或算法,而是对现有模型进行分类。分类框架主要包括以下几个维度:1) 架构设计(基于patch或原始序列);2) 预测类型(概率或确定性);3) 数据类型(单变量或多变量);4) 模型规模和复杂性;5) 训练目标函数类型。
关键创新:该综述的创新之处在于提出了一个新颖的、多维度的分类体系,能够更全面地描述和比较不同的时间序列基础模型。特别是,按照训练目标函数类型进行分类,有助于理解不同模型学习到的时间序列表示的本质差异。
关键设计:综述的关键设计在于其分类体系的构建,每个维度都经过精心选择,以反映模型的重要特征。例如,区分基于patch和原始序列的模型,反映了不同模型对时间序列局部和全局信息的处理方式。区分概率和确定性预测,反映了模型对不确定性的建模能力。对训练目标函数的分类,则揭示了模型学习到的时间序列表示的本质差异。
🖼️ 关键图片
📊 实验亮点
该综述通过对现有Transformer时间序列基础模型进行系统分类,揭示了不同模型之间的内在联系和差异,为研究人员和从业者提供了宝贵的参考。特别是,按照训练目标函数类型进行分类,有助于理解不同模型学习到的时间序列表示的本质差异,为未来的模型设计提供了新的思路。
🎯 应用场景
该研究成果可应用于金融、医疗、物联网等多个领域的时间序列数据分析任务。例如,在金融领域,可以用于股票价格预测、风险管理等;在医疗领域,可以用于疾病诊断、患者监测等;在物联网领域,可以用于设备故障预测、能耗优化等。该综述有助于推动时间序列分析技术在实际应用中的发展。
📄 摘要(原文)
Transformer-based foundation models have emerged as a dominant paradigm in time series analysis, offering unprecedented capabilities in tasks such as forecasting, anomaly detection, classification, trend analysis and many more time series analytical tasks. This survey provides a comprehensive overview of the current state of the art pre-trained foundation models, introducing a novel taxonomy to categorize them across several dimensions. Specifically, we classify models by their architecture design, distinguishing between those leveraging patch-based representations and those operating directly on raw sequences. The taxonomy further includes whether the models provide probabilistic or deterministic predictions, and whether they are designed to work with univariate time series or can handle multivariate time series out of the box. Additionally, the taxonomy encompasses model scale and complexity, highlighting differences between lightweight architectures and large-scale foundation models. A unique aspect of this survey is its categorization by the type of objective function employed during training phase. By synthesizing these perspectives, this survey serves as a resource for researchers and practitioners, providing insights into current trends and identifying promising directions for future research in transformer-based time series modeling.