Concept-based Rubrics Improve LLM Formative Assessment and Data Synthesis
作者: Yuchen Wei, Dennis Pearl, Matthew Beckman, Rebecca J. Passonneau
分类: cs.LG
发布日期: 2025-04-04
备注: 13 pages excluding references. 9 tables and 4 figures
💡 一句话要点
基于概念的评分标准提升LLM在形成性评估和数据合成中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 形成性评估 概念评分标准 数据合成 STEM教育
📋 核心要点
- 现有LLM在STEM形成性评估中表现不佳,不如有监督模型,限制了其应用。
- 提出基于概念的评分标准,引导LLM进行更细粒度的评估,提升性能。
- 实验表明,该方法显著提升LLM评估能力,并能生成高质量合成数据。
📝 摘要(中文)
本研究旨在提升大型语言模型(LLM)在STEM领域形成性评估中的表现。先前的研究表明,LLM在开放式问题作答评估方面的性能显著低于在高质量标注数据上训练的有监督分类器。然而,本文证明了基于概念的评分标准可以显著提高LLM的性能,缩小了LLM作为即用型评估工具与需要大量训练数据的较小规模有监督模型之间的差距。对于基于概念的评分标准使LLM能够获得良好性能的数据集,本文进一步展示了这些评分标准可以帮助LLM生成高质量的合成数据,用于训练轻量级、高性能的有监督模型。实验涵盖了具有不同质量标签的各种STEM学生回答数据集,包括一个新的真实世界数据集,其中包含一些AI辅助的回答,这引入了额外的考虑因素。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在STEM领域形成性评估中表现不佳的问题。现有方法依赖于直接评估学生的回答,但缺乏对回答中蕴含概念的细粒度理解,导致评估准确率较低。此外,训练高性能的有监督模型需要大量高质量的标注数据,获取成本高昂。
核心思路:论文的核心思路是引入基于概念的评分标准,将评估过程分解为对学生回答中各个概念掌握程度的评估。通过明确定义每个概念的评分标准,引导LLM进行更细粒度的分析,从而提高评估的准确性和可靠性。同时,利用LLM生成高质量的合成数据,降低有监督模型的训练成本。
技术框架:整体框架包含两个主要阶段:1) 使用基于概念的评分标准评估学生回答:首先,将学生回答输入LLM,并提供基于概念的评分标准。LLM根据评分标准对回答中各个概念的掌握程度进行评估,并给出相应的分数或等级。2) 使用LLM生成合成数据:利用LLM和基于概念的评分标准,生成大量的合成学生回答及其对应的概念掌握程度标签。这些合成数据用于训练轻量级的有监督模型。
关键创新:最重要的技术创新点在于将基于概念的评分标准引入LLM的形成性评估中。与传统的直接评估方法相比,该方法能够更准确地识别学生对各个概念的理解程度,从而提供更有效的反馈和指导。此外,利用LLM生成合成数据,降低了有监督模型的训练成本,使其更易于部署和应用。
关键设计:论文的关键设计包括:1) 精心设计的基于概念的评分标准,确保评分标准能够准确反映学生对各个概念的掌握程度。2) 使用合适的LLM,并进行适当的微调,以提高LLM在评估和数据生成方面的性能。3) 设计有效的合成数据生成策略,确保合成数据的质量和多样性。
🖼️ 关键图片

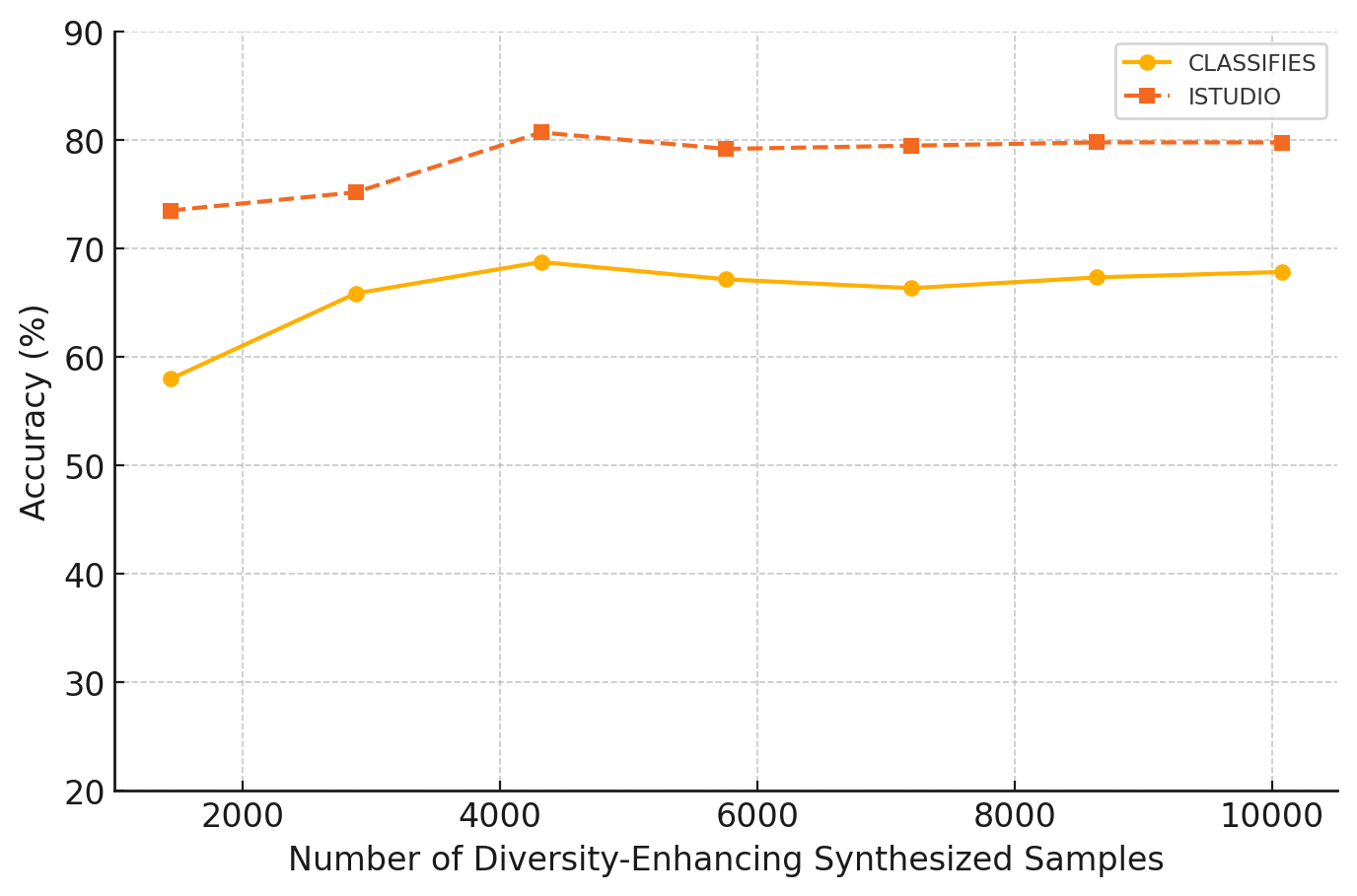
📊 实验亮点
实验结果表明,基于概念的评分标准可以显著提升LLM在STEM形成性评估中的表现,缩小了与有监督模型之间的差距。此外,利用LLM生成的合成数据可以有效地训练轻量级的有监督模型,使其达到与在真实数据上训练的模型相近的性能。具体性能提升数据未知。
🎯 应用场景
该研究成果可广泛应用于在线教育平台、智能辅导系统和自动化评估工具中。通过提升LLM在形成性评估中的表现,可以为学生提供更个性化、更有效的学习反馈和指导。此外,利用LLM生成合成数据,可以降低有监督模型的训练成本,促进其在教育领域的应用。
📄 摘要(原文)
Formative assessment in STEM topics aims to promote student learning by identifying students' current understanding, thus targeting how to promote further learning. Previous studies suggest that the assessment performance of current generative large language models (LLMs) on constructed responses to open-ended questions is significantly lower than that of supervised classifiers trained on high-quality labeled data. However, we demonstrate that concept-based rubrics can significantly enhance LLM performance, which narrows the gap between LLMs as off-the shelf assessment tools, and smaller supervised models, which need large amounts of training data. For datasets where concept-based rubrics allow LLMs to achieve strong performance, we show that the concept-based rubrics help the same LLMs generate high quality synthetic data for training lightweight, high-performance supervised models. Our experiments span diverse STEM student response datasets with labels of varying quality, including a new real-world dataset that contains some AI-assisted responses, which introduces additional considerations.