HeterMoE: Efficient Training of Mixture-of-Experts Models on Heterogeneous GPUs
作者: Yongji Wu, Xueshen Liu, Shuowei Jin, Ceyu Xu, Feng Qian, Z. Morley Mao, Matthew Lentz, Danyang Zhuo, Ion Stoica
分类: cs.DC, cs.LG
发布日期: 2025-04-04
💡 一句话要点
HeterMoE:异构GPU上高效训练混合专家模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 异构GPU 分布式训练 负载均衡 模型并行
📋 核心要点
- 现有异构GPU训练MoE模型的方法未充分考虑注意力机制和专家模块的性能差异,导致GPU利用率不高。
- HeterMoE的核心思想是根据GPU的性能特点,将注意力机制和专家模块分别分配给新旧GPU,实现异构计算。
- 实验结果表明,HeterMoE相比现有MoE训练系统加速高达2.3倍,即使替换一半GPU也能保持95%的训练吞吐量。
📝 摘要(中文)
混合专家(MoE)架构已成为扩展大型语言模型(LLM)的一种流行方法。为了节省成本,已经提出了异构感知训练解决方案,以利用由新一代和旧一代GPU组成的GPU集群。然而,现有的解决方案对不同MoE模型组件(即,注意力机制和专家)的性能特征不敏感,并且没有充分利用每个GPU的计算能力。本文介绍了一种名为HeterMoE的系统,用于在异构GPU上高效地训练MoE模型。我们的关键见解是,由于架构的进步,较新的GPU在注意力机制方面明显优于旧一代GPU,而旧的GPU对于专家模块仍然相对有效。HeterMoE分离了注意力机制和专家计算,其中旧的GPU仅被分配专家模块。通过提出的斑马并行性,HeterMoE重叠了不同GPU上的计算,此外还采用了非对称专家分配策略进行细粒度的负载平衡,以最大限度地减少GPU空闲时间。我们的评估表明,与现有的MoE训练系统相比,HeterMoE实现了高达2.3倍的加速,与优化平衡的异构感知解决方案相比,实现了1.4倍的加速。HeterMoE通过平均保持95%的训练吞吐量来有效地利用旧的GPU,即使在同构A40集群中有一半的GPU被V100替换。
🔬 方法详解
问题定义:现有在异构GPU集群上训练MoE模型的方法,没有充分考虑到不同GPU架构在处理不同MoE组件(如Attention和Expert)时的性能差异。简单地将所有计算任务分配给所有GPU,导致性能较弱的GPU成为瓶颈,无法充分利用异构集群的计算能力。
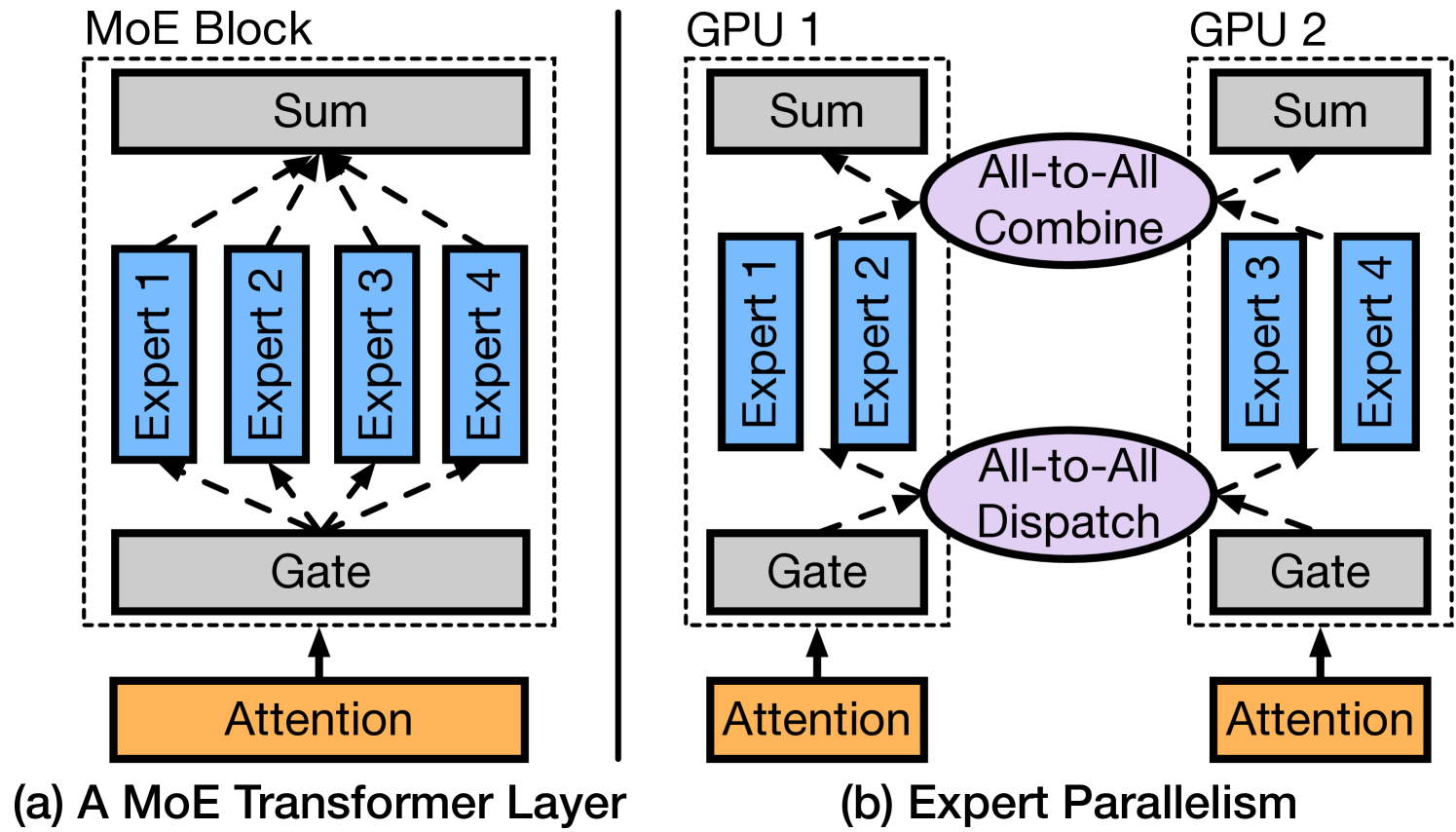
核心思路:HeterMoE的核心思路是根据不同GPU的性能特点,将MoE模型中的Attention计算和Expert计算解耦,并分别分配给适合的GPU。具体来说,较新的GPU在Attention计算上具有显著优势,而较旧的GPU在Expert计算上仍然具有较好的效率。因此,HeterMoE将Attention计算分配给较新的GPU,将Expert计算分配给较旧的GPU,从而实现异构计算的优化。
技术框架:HeterMoE的整体框架包括以下几个关键组件:1) Attention-Expert解耦:将MoE模型中的Attention和Expert计算分离。2) 异构任务分配:根据GPU的性能特点,将Attention计算分配给较新的GPU,将Expert计算分配给较旧的GPU。3) 斑马并行(Zebra Parallelism):一种并行计算策略,通过重叠不同GPU上的计算,提高整体训练效率。4) 非对称专家分配:一种细粒度的负载均衡策略,根据GPU的计算能力动态调整专家模块的分配,以最小化GPU的空闲时间。
关键创新:HeterMoE的关键创新在于其异构任务分配策略和斑马并行机制。传统的MoE训练方法通常将所有计算任务分配给所有GPU,而HeterMoE则根据GPU的性能特点进行差异化分配,从而提高了整体的计算效率。斑马并行机制通过重叠不同GPU上的计算,进一步减少了GPU的空闲时间,提高了训练吞吐量。
关键设计:HeterMoE的关键设计包括:1) 专家数量的动态调整:根据GPU的计算能力,动态调整分配给每个GPU的专家数量,以实现负载均衡。2) 通信优化:针对异构GPU集群的特点,优化Attention和Expert计算之间的通信,减少通信开销。3) 损失函数的设计:采用标准的MoE损失函数,并根据异构计算的特点进行微调,以保证模型的训练效果。
🖼️ 关键图片
📊 实验亮点
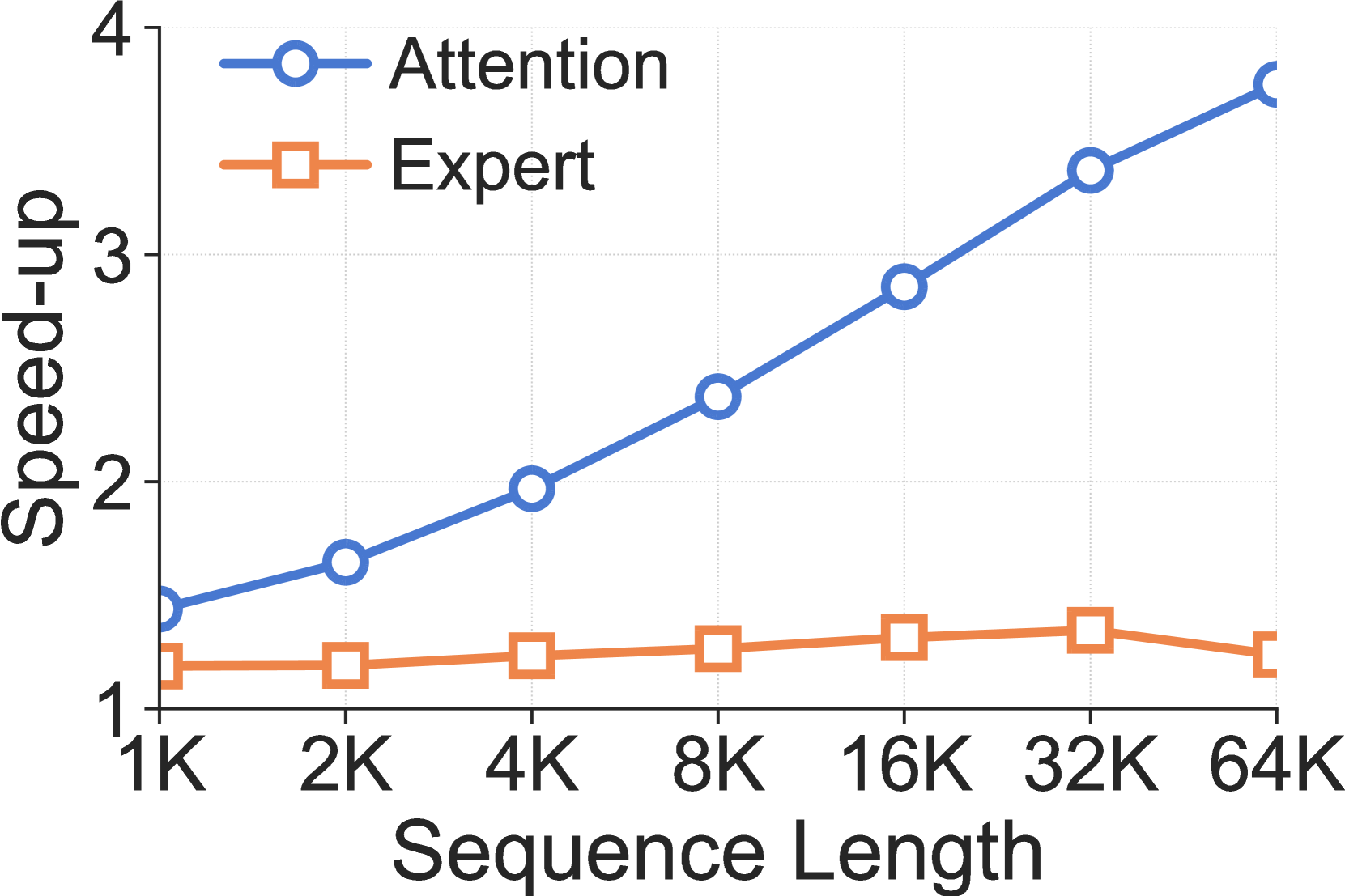
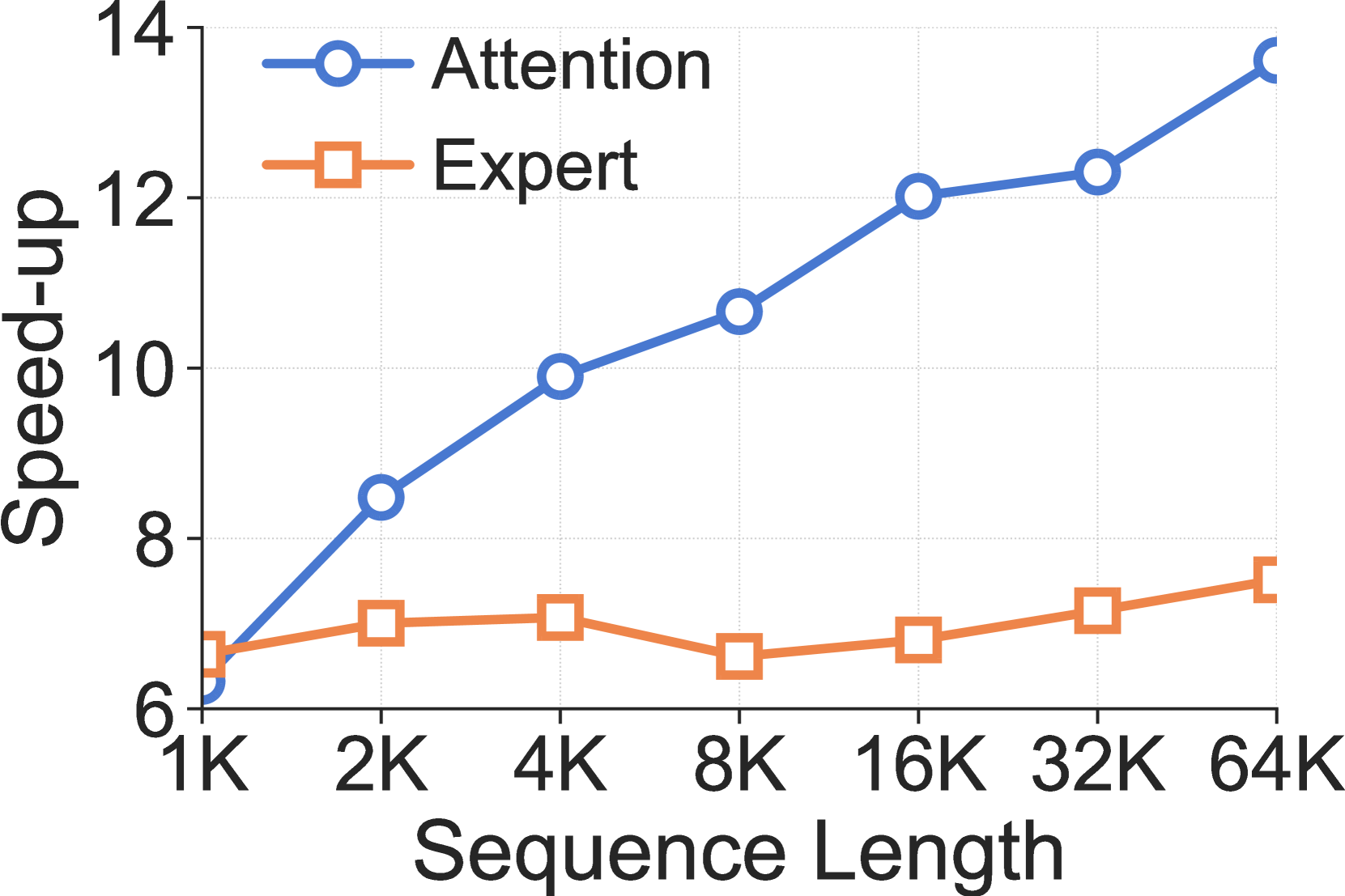
HeterMoE在异构GPU集群上实现了显著的性能提升。实验结果表明,与现有的MoE训练系统相比,HeterMoE实现了高达2.3倍的加速。与优化平衡的异构感知解决方案相比,实现了1.4倍的加速。即使在同构A40集群中有一半的GPU被V100替换,HeterMoE仍然能够保持95%的训练吞吐量,证明了其在异构环境下的高效性。
🎯 应用场景
HeterMoE可应用于大规模语言模型的训练,尤其是在拥有异构GPU集群的环境下。通过充分利用新旧GPU的计算能力,降低训练成本,加速模型迭代。该技术对于资源有限但又需要训练大型模型的科研机构和企业具有重要价值,并有望推动更大规模、更高性能的语言模型的发展。
📄 摘要(原文)
The Mixture-of-Experts (MoE) architecture has become increasingly popular as a method to scale up large language models (LLMs). To save costs, heterogeneity-aware training solutions have been proposed to utilize GPU clusters made up of both newer and older-generation GPUs. However, existing solutions are agnostic to the performance characteristics of different MoE model components (i.e., attention and expert) and do not fully utilize each GPU's compute capability. In this paper, we introduce HeterMoE, a system to efficiently train MoE models on heterogeneous GPUs. Our key insight is that newer GPUs significantly outperform older generations on attention due to architectural advancements, while older GPUs are still relatively efficient for experts. HeterMoE disaggregates attention and expert computation, where older GPUs are only assigned with expert modules. Through the proposed zebra parallelism, HeterMoE overlaps the computation on different GPUs, in addition to employing an asymmetric expert assignment strategy for fine-grained load balancing to minimize GPU idle time. Our evaluation shows that HeterMoE achieves up to 2.3x speed-up compared to existing MoE training systems, and 1.4x compared to an optimally balanced heterogeneity-aware solution. HeterMoE efficiently utilizes older GPUs by maintaining 95% training throughput on average, even with half of the GPUs in a homogeneous A40 cluster replaced with V100.