Recursive Training Loops in LLMs: How training data properties modulate distribution shift in generated data?
作者: Grgur Kovač, Jérémy Perez, Rémy Portelas, Peter Ford Dominey, Pierre-Yves Oudeyer
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-04-04 (更新: 2025-12-26)
备注: Accepted to EMNLP 2025 (Oral), Source Code: https://github.com/flowersteam/ce_llms
💡 一句话要点
研究LLM递归训练中数据属性如何影响生成数据分布偏移
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 递归训练 分布偏移 数据属性 模型崩溃
📋 核心要点
- 现有研究对LLM递归训练中人类数据属性如何影响生成数据分布偏移缺乏深入理解。
- 通过操纵数据集属性并结合回归分析,识别出预测分布偏移幅度的关键属性。
- 实验表明词汇多样性放大偏移,语义多样性和数据质量减轻偏移,且影响具有模块化特性。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用于创建在线内容,这形成了一种反馈循环,因为后续的模型将使用这些合成数据进行训练。这种循环已被证明会导致分布偏移——模型错误地表示了人类数据的真实底层分布(也称为模型崩溃)。然而,人类数据属性如何影响这种偏移仍然知之甚少。本文首次实证研究了这些属性对递归训练结果的影响。我们首先证实,使用不同的人类数据集会导致不同程度的分布偏移。通过对数据集属性的详尽操作以及回归分析,我们随后识别出一组预测分布偏移幅度的属性。词汇多样性被发现会放大这些偏移,而语义多样性和数据质量会减轻它们。此外,我们发现这些影响是高度模块化的:从给定互联网域抓取的数据对为另一个域生成的内容几乎没有影响。最后,关于政治偏见的实验表明,人类数据属性会影响初始偏见是被放大还是被减少。总的来说,我们的结果描绘了一种新颖的观点,即互联网的不同部分可能会经历不同类型的分布偏移。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在递归训练过程中,人类训练数据的属性如何影响生成数据的分布偏移。现有的方法未能充分理解不同数据属性(如词汇多样性、语义多样性、数据质量等)对模型崩溃的影响,导致模型在生成内容时可能出现偏差或失真。
核心思路:论文的核心思路是通过系统性地操纵训练数据集的各种属性,并结合回归分析,来量化这些属性与生成数据分布偏移之间的关系。通过这种方式,可以识别出哪些属性会放大偏移,哪些属性会减轻偏移,从而为更好地控制LLM的生成行为提供指导。
技术框架:论文的技术框架主要包括以下几个阶段:1) 构建不同属性(如词汇多样性、语义多样性、数据质量等)的人类数据集;2) 使用这些数据集对LLM进行递归训练,即使用模型生成的数据再次训练模型;3) 测量每一轮训练后生成数据的分布偏移;4) 使用回归分析方法,分析数据集属性与分布偏移之间的关系,从而识别出关键的影响因素。
关键创新:论文的关键创新在于首次实证研究了人类数据属性对LLM递归训练中分布偏移的影响,并量化了不同属性的影响程度。此外,论文还发现这些影响是高度模块化的,即不同互联网域的数据对其他域的生成内容影响较小。
关键设计:论文的关键设计包括:1) 使用多种指标来衡量数据集的属性,如词汇多样性、语义多样性、数据质量等;2) 使用合适的距离度量来衡量生成数据的分布偏移;3) 使用回归分析方法来建模数据集属性与分布偏移之间的关系,并控制其他潜在的混淆因素。
🖼️ 关键图片

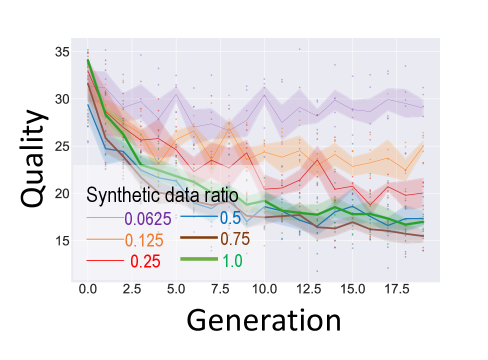

📊 实验亮点
实验结果表明,词汇多样性会放大LLM递归训练中的分布偏移,而语义多样性和数据质量则会减轻这种偏移。此外,研究发现数据影响具有模块化特性,即特定领域的数据对其他领域的影响较小。政治偏见实验表明,人类数据属性会影响初始偏见是被放大还是被减少。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可靠性和公平性,例如在内容生成、对话系统和信息检索等领域。通过控制训练数据的属性,可以减轻模型偏差,提高生成内容的多样性和质量,避免模型崩溃等问题。此外,该研究还可以指导数据集的构建和选择,从而更好地训练LLM。
📄 摘要(原文)
Large language models (LLMs) are increasingly used in the creation of online content, creating feedback loops as subsequent generations of models will be trained on this synthetic data. Such loops were shown to lead to distribution shifts - models misrepresenting the true underlying distributions of human data (also called model collapse). However, how human data properties affect such shifts remains poorly understood. In this paper, we provide the first empirical examination of the effect of such properties on the outcome of recursive training. We first confirm that using different human datasets leads to distribution shifts of different magnitudes. Through exhaustive manipulation of dataset properties combined with regression analyses, we then identify a set of properties predicting distribution shift magnitudes. Lexical diversity is found to amplify these shifts, while semantic diversity and data quality mitigate them. Furthermore, we find that these influences are highly modular: data scrapped from a given internet domain has little influence on the content generated for another domain. Finally, experiments on political bias reveal that human data properties affect whether the initial bias will be amplified or reduced. Overall, our results portray a novel view, where different parts of internet may undergo different types of distribution shift.