Optimizing Specific and Shared Parameters for Efficient Parameter Tuning
作者: Van-Anh Nguyen, Thanh-Toan Do, Mehrtash Harandi, Dinh Phung, Trung Le
分类: cs.LG
发布日期: 2025-04-04
💡 一句话要点
提出SaS,通过优化特定和共享参数实现高效参数调优的PETL方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效迁移学习 PETL 超网络 低秩分解 领域泛化
📋 核心要点
- 现有大模型微调方法计算开销大,参数效率低,难以高效适应下游任务。
- SaS方法通过共享模块捕获跨层通用统计特征,层特定模块生成定制参数,平衡性能与效率。
- 实验表明,SaS在多种任务上显著提升性能,参数效率优于现有方法,额外参数小于0.05%。
📝 摘要(中文)
本文提出了一种新的参数高效迁移学习(PETL)方法SaS,旨在有效缓解微调过程中的分布偏移。SaS集成了两个模块:(1)一个共享模块,利用低秩投影捕获跨层的通用统计特征;(2)一个层特定模块,使用超网络为每一层生成定制的参数。这种双重设计确保了性能和参数效率之间的最佳平衡,同时引入的额外参数小于0.05%,远小于现有方法。在各种下游任务、少样本设置和领域泛化上的大量实验表明,SaS显著提高了性能,同时保持了优于现有方法的参数效率,突出了在迁移学习中捕获共享和层特定信息的重要性。代码和数据可在https://anonymous.4open.science/r/SaS-PETL-3565获取。
🔬 方法详解
问题定义:论文旨在解决大型预训练模型在迁移到下游任务时,如何以最小的计算开销和参数量,高效地进行参数调优的问题。现有的参数高效迁移学习(PETL)方法虽然减少了需要微调的参数量,但在捕捉跨层共享信息和层特定信息方面存在不足,导致性能提升有限。
核心思路:论文的核心思路是将模型的参数更新分解为两部分:一部分是跨层共享的参数更新,用于捕捉模型中不同层之间共享的统计特性;另一部分是层特定的参数更新,用于适应不同层对特定任务的需求。通过这种方式,既能利用预训练模型的通用知识,又能针对特定任务进行精细化调整。
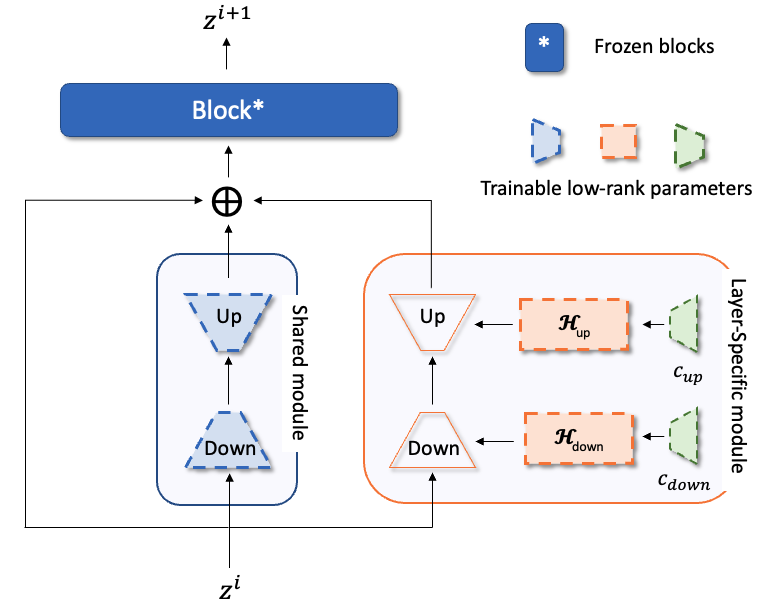
技术框架:SaS方法包含两个主要模块:共享模块和层特定模块。共享模块使用低秩投影来捕获跨层的通用统计特征,降低参数量。层特定模块使用超网络(Hypernetwork)为每一层生成定制的参数,以适应不同层的需求。这两个模块共同作用,实现高效的参数调优。整体流程是:输入数据经过预训练模型,然后通过SaS模块进行参数调整,最后输出预测结果。
关键创新:SaS的关键创新在于同时考虑了跨层共享的信息和层特定的信息,并设计了相应的模块来捕捉这些信息。与现有方法相比,SaS能够更好地平衡性能和参数效率,在引入极少量额外参数的情况下,显著提升下游任务的性能。
关键设计:共享模块使用低秩分解来降低参数量,具体实现方式是使用两个线性层将原始参数投影到低维空间,然后再投影回原始维度。层特定模块使用超网络来生成每一层的参数,超网络的输入是层的索引,输出是该层的参数。损失函数通常是下游任务的标准损失函数,例如交叉熵损失函数。论文中具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
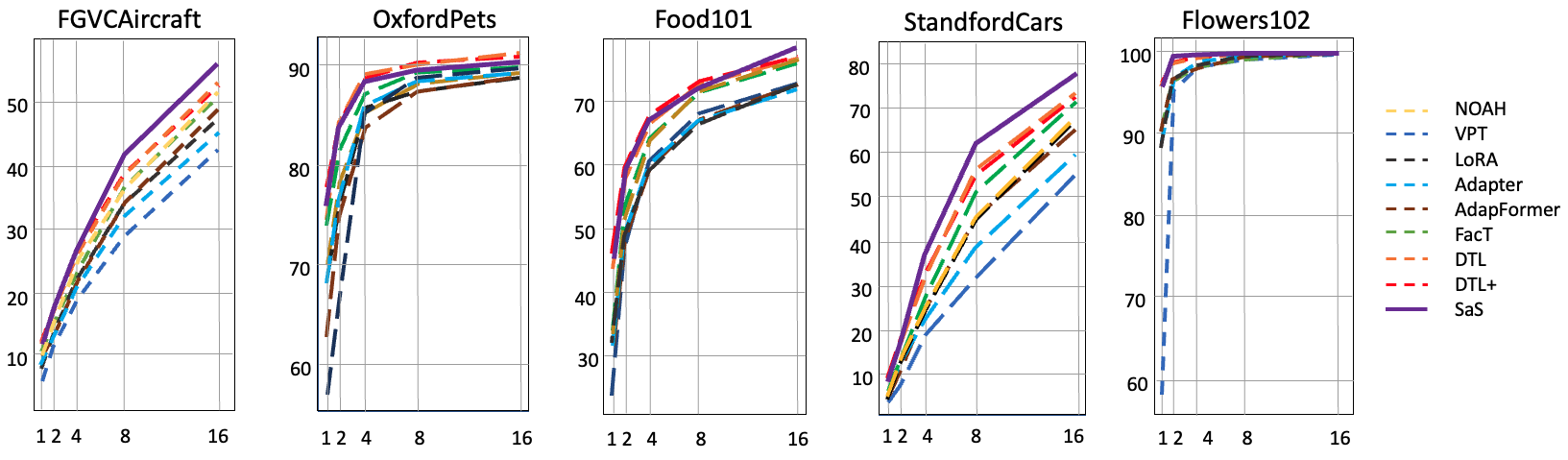
SaS方法在多种下游任务、少样本设置和领域泛化上进行了实验,结果表明SaS显著提高了性能,同时保持了优于现有方法的参数效率。SaS引入的额外参数小于0.05%,远小于现有方法,例如Adapter等。具体的性能提升数据未知,但论文强调了SaS在参数效率上的优势。
🎯 应用场景
SaS方法可广泛应用于各种需要迁移学习的场景,例如自然语言处理、计算机视觉等。特别是在资源受限的环境下,SaS能够以极低的计算成本和参数量,将大型预训练模型快速部署到各种下游任务中,具有重要的实际应用价值。未来,SaS可以进一步扩展到多模态学习、联邦学习等领域。
📄 摘要(原文)
Foundation models, with a vast number of parameters and pretraining on massive datasets, achieve state-of-the-art performance across various applications. However, efficiently adapting them to downstream tasks with minimal computational overhead remains a challenge. Parameter-Efficient Transfer Learning (PETL) addresses this by fine-tuning only a small subset of parameters while preserving pre-trained knowledge. In this paper, we propose SaS, a novel PETL method that effectively mitigates distributional shifts during fine-tuning. SaS integrates (1) a shared module that captures common statistical characteristics across layers using low-rank projections and (2) a layer-specific module that employs hypernetworks to generate tailored parameters for each layer. This dual design ensures an optimal balance between performance and parameter efficiency while introducing less than 0.05% additional parameters, making it significantly more compact than existing methods. Extensive experiments on diverse downstream tasks, few-shot settings and domain generalization demonstrate that SaS significantly enhances performance while maintaining superior parameter efficiency compared to existing methods, highlighting the importance of capturing both shared and layer-specific information in transfer learning. Code and data are available at https://anonymous.4open.science/r/SaS-PETL-3565.