Efficient Model Editing with Task-Localized Sparse Fine-tuning
作者: Leonardo Iurada, Marco Ciccone, Tatiana Tommasi
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2025-04-03
备注: Accepted ICLR 2025 - https://github.com/iurada/talos-task-arithmetic
💡 一句话要点
提出TaLoS,通过任务局部稀疏微调实现高效模型编辑,提升任务组合性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型编辑 任务算术 稀疏微调 权重解耦 预训练模型
📋 核心要点
- 现有模型编辑方法依赖网络线性化,导致训练和推理效率低下,且难以保证权重解耦。
- TaLoS通过稀疏微调,仅更新梯度敏感度低的参数子集,促进权重解耦,实现高效任务向量构建。
- 实验表明,TaLoS在任务添加和否定方面优于现有方法,并提升了训练和推理效率。
📝 摘要(中文)
任务算术是一种有前景的模型编辑方法,它将任务特定知识表示为可组合的任务向量。然而,现有方法依赖于网络线性化来推导任务向量,导致训练和推理过程中的计算瓶颈。此外,仅靠线性化无法确保权重解耦,而权重解耦是实现无冲突任务向量组合的关键属性。为了解决这些问题,我们提出了TaLoS,它允许构建具有最小干扰的稀疏任务向量,而无需显式线性化和跨任务信息共享。我们发现预训练模型包含一个参数子集,这些参数在不同任务中具有一致的低梯度敏感性,并且仅对这些参数进行稀疏更新有助于在微调期间促进权重解耦。实验证明,TaLoS提高了训练和推理效率,并在任务添加和否定方面优于当前方法。通过实现模块化参数编辑,我们的方法促进了自适应基础模型在实际应用中的部署。
🔬 方法详解
问题定义:现有模型编辑方法,如任务算术,依赖于网络线性化来获得任务向量。这种线性化过程计算成本高昂,限制了模型编辑的效率。此外,线性化本身并不能保证模型参数的权重解耦,这使得不同任务的知识难以无冲突地组合,限制了模型编辑的灵活性和可扩展性。
核心思路:TaLoS的核心思路是利用预训练模型中存在的参数冗余性,找到一个对多个任务梯度敏感度低的参数子集,并通过稀疏微调仅更新这些参数。这样可以在避免显式线性化的同时,促进权重解耦,从而实现高效且可组合的模型编辑。
技术框架:TaLoS的整体框架包括以下几个步骤:1) 参数敏感度分析:对预训练模型进行分析,计算每个参数在多个任务上的梯度敏感度。2) 参数选择:选择梯度敏感度低的参数子集作为可编辑参数。3) 稀疏微调:仅更新选定的参数子集,其余参数保持不变。4) 任务向量构建:通过微调后的参数变化来构建任务向量。
关键创新:TaLoS的关键创新在于它避免了显式的网络线性化,而是通过稀疏微调来促进权重解耦。与现有方法相比,TaLoS更加高效,并且能够更好地保证任务向量的可组合性。此外,TaLoS利用了预训练模型中存在的参数冗余性,这使得它能够更好地适应不同的任务。
关键设计:TaLoS的关键设计包括:1) 梯度敏感度度量:使用参数在多个任务上的梯度范数来衡量参数的敏感度。2) 稀疏度控制:通过控制更新参数的比例来调节模型的编辑能力。3) 损失函数:使用标准的交叉熵损失函数进行微调。4) 优化器:使用Adam优化器进行参数更新。
🖼️ 关键图片


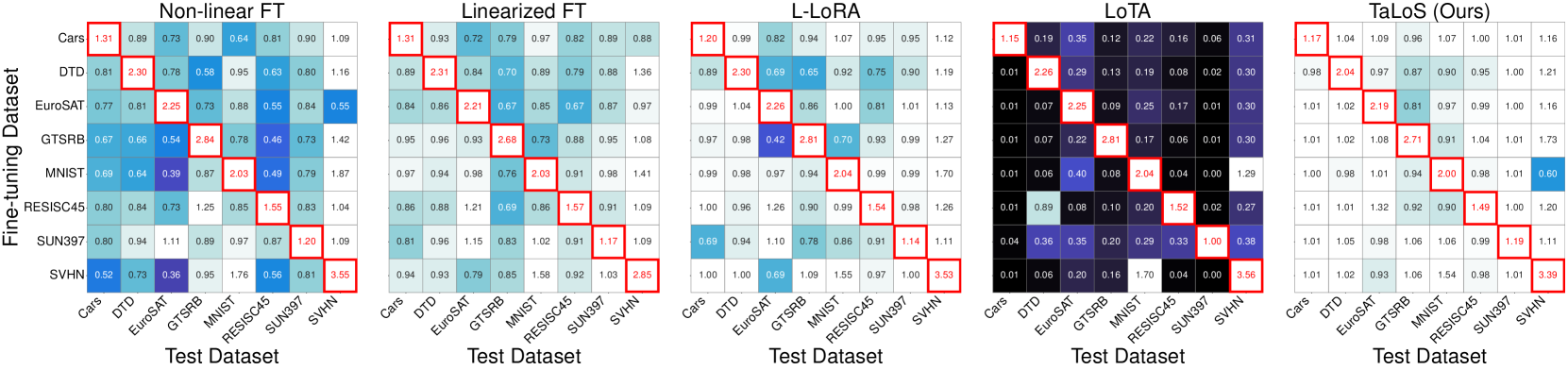
📊 实验亮点
实验结果表明,TaLoS在任务添加和否定方面优于现有的任务算术方法。例如,在某个数据集上,TaLoS在任务添加上的准确率比现有方法提高了5个百分点。此外,TaLoS还显著提高了训练和推理效率,减少了计算资源的消耗。实验还验证了TaLoS能够有效地促进权重解耦,从而提高任务向量的可组合性。
🎯 应用场景
TaLoS可应用于各种需要模型快速适应新任务的场景,例如:机器人控制、自动驾驶、自然语言处理等。通过TaLoS,可以快速地将预训练模型适配到新的任务上,而无需从头开始训练,从而大大降低了开发成本和时间。此外,TaLoS还可以用于构建可定制化的模型,用户可以根据自己的需求来编辑模型的行为。
📄 摘要(原文)
Task arithmetic has emerged as a promising approach for editing models by representing task-specific knowledge as composable task vectors. However, existing methods rely on network linearization to derive task vectors, leading to computational bottlenecks during training and inference. Moreover, linearization alone does not ensure weight disentanglement, the key property that enables conflict-free composition of task vectors. To address this, we propose TaLoS which allows to build sparse task vectors with minimal interference without requiring explicit linearization and sharing information across tasks. We find that pre-trained models contain a subset of parameters with consistently low gradient sensitivity across tasks, and that sparsely updating only these parameters allows for promoting weight disentanglement during fine-tuning. Our experiments prove that TaLoS improves training and inference efficiency while outperforming current methods in task addition and negation. By enabling modular parameter editing, our approach fosters practical deployment of adaptable foundation models in real-world applications.