GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
作者: Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, Yong Wang
分类: cs.LG, cs.AI
发布日期: 2025-04-03 (更新: 2025-05-01)
🔗 代码/项目: GITHUB
💡 一句话要点
提出GPG:一种用于模型推理的简单而强大的强化学习基线方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 策略梯度 语言模型 模型推理 多模态学习
📋 核心要点
- 现有强化学习方法在增强大型语言模型推理能力时,通常依赖复杂的替代损失函数和约束,增加了训练难度。
- GPG方法通过直接优化原始强化学习目标,避免了使用替代损失函数,简化了训练流程,降低了计算成本。
- 实验结果表明,GPG在多种单模态和多模态任务中,性能优于GRPO,验证了其有效性和优越性。
📝 摘要(中文)
本文提出了一种极简的强化学习方法,称为分组策略梯度(GPG),旨在直接增强大型语言模型的推理能力,而无需过度依赖监督微调(SFT)。GPG直接优化原始强化学习目标,避免了使用替代损失函数。通过消除评论家网络和参考模型,避免KL散度约束,并解决优势函数和梯度估计偏差,与分组相对策略优化(GRPO)相比,GPG显著简化了训练过程。实验结果表明,该方法无需辅助技术或调整即可实现卓越的性能,并在各种单模态和多模态任务中始终优于GRPO,同时降低了计算成本。
🔬 方法详解
问题定义:现有强化学习方法在提升大型语言模型(LLM)的推理能力时,通常依赖于监督微调(SFT)或复杂的强化学习算法。这些方法存在一些痛点,例如SFT需要大量标注数据,而现有强化学习算法如GRPO则依赖于替代损失函数、评论家网络、参考模型以及KL散度约束,导致训练过程复杂且计算成本高昂。此外,优势函数和梯度估计偏差也会影响训练效果。
核心思路:GPG的核心思路是回归到传统的策略梯度(PG)机制,并对其进行简化和优化。通过直接优化原始强化学习目标,避免使用替代损失函数,从而简化训练过程。同时,通过消除评论家网络和参考模型,进一步降低计算成本。此外,GPG还致力于解决优势函数和梯度估计偏差,以提高训练效果。
技术框架:GPG的整体框架非常简洁。它直接利用策略梯度算法更新语言模型的策略。具体流程包括:首先,使用语言模型生成一系列动作(例如,答案或推理步骤);然后,根据环境反馈(例如,奖励信号)评估这些动作的质量;最后,使用策略梯度算法,根据动作的质量调整语言模型的参数,使其更倾向于生成高质量的动作。整个过程无需额外的评论家网络或参考模型。
关键创新:GPG最重要的技术创新点在于其极简的设计理念。与现有方法相比,GPG避免了使用替代损失函数、评论家网络、参考模型以及KL散度约束,从而显著简化了训练过程。这种极简的设计不仅降低了计算成本,还提高了训练的稳定性和效率。此外,GPG直接优化原始强化学习目标,避免了因使用替代损失函数而引入的偏差。
关键设计:GPG的关键设计在于其对策略梯度算法的直接应用和优化。具体而言,GPG使用分组策略梯度来估计策略梯度,并通过适当的基线函数来减少方差。此外,GPG还采用了一些技巧来解决梯度估计偏差问题。损失函数就是标准的策略梯度损失函数,没有引入额外的正则化项或约束。网络结构就是待训练的语言模型本身,无需额外的网络结构。
🖼️ 关键图片
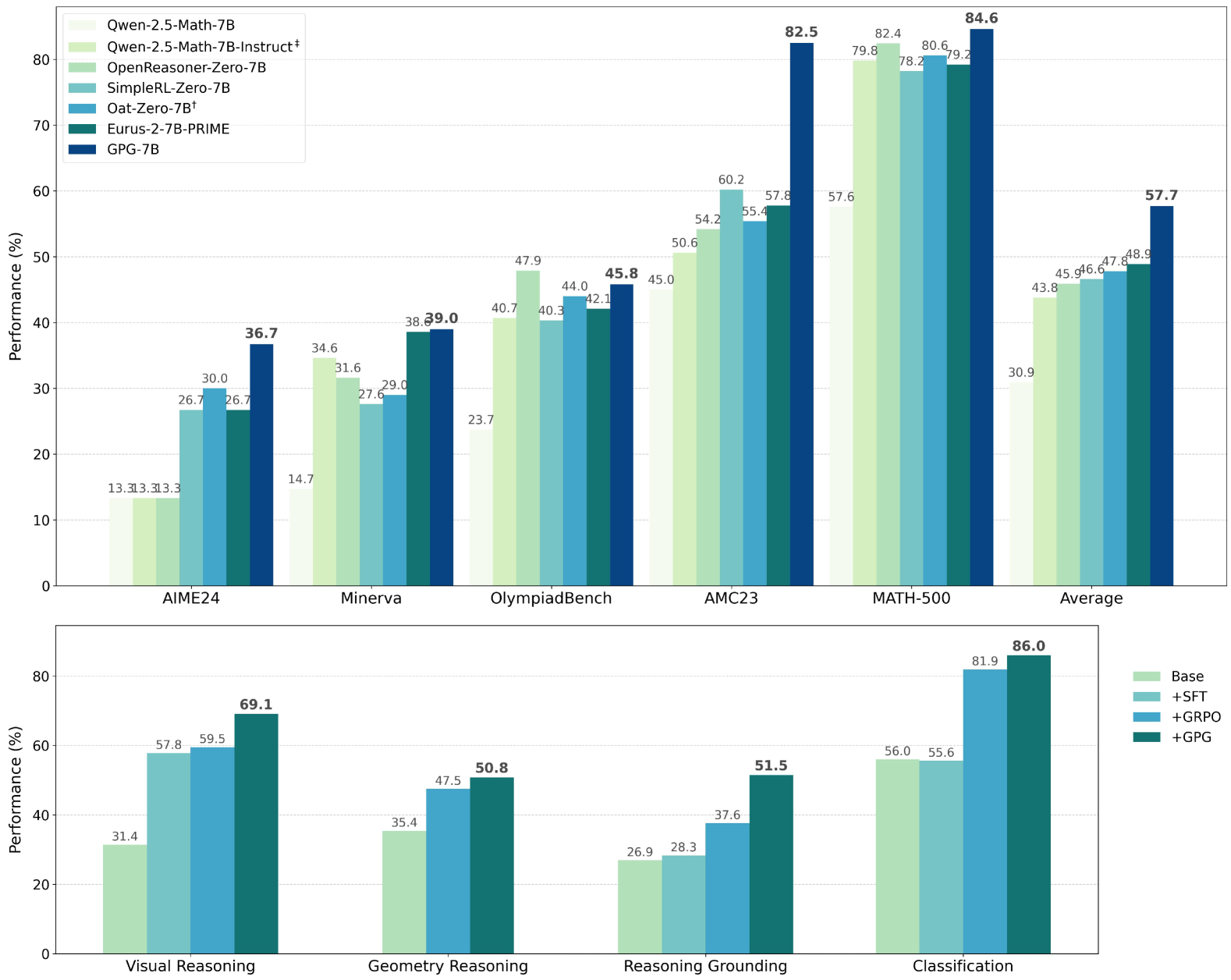


📊 实验亮点
实验结果表明,GPG在各种单模态和多模态任务中均优于GRPO。例如,在某些推理任务中,GPG的性能提升超过5%。更重要的是,GPG在实现性能提升的同时,显著降低了计算成本,使其成为一种更具吸引力的强化学习基线方法。代码已开源。
🎯 应用场景
GPG方法具有广泛的应用前景,可用于提升各种大型语言模型在问答、推理、对话等任务中的性能。该方法尤其适用于资源受限的场景,例如移动设备或边缘计算环境,因为其计算成本较低。此外,GPG还可以应用于多模态任务,例如图像描述生成和视觉问答,从而提升模型在这些任务中的表现。
📄 摘要(原文)
Reinforcement Learning (RL) can directly enhance the reasoning capabilities of large language models without extensive reliance on Supervised Fine-Tuning (SFT). In this work, we revisit the traditional Policy Gradient (PG) mechanism and propose a minimalist RL approach termed Group Policy Gradient (GPG). Unlike conventional methods, GPG directly optimize the original RL objective, thus obviating the need for surrogate loss functions. By eliminating the critic and reference models, avoiding KL divergence constraints, and addressing the advantage and gradient estimation bias, our approach significantly simplifies the training process compared to Group Relative Policy Optimization (GRPO). Our approach achieves superior performance without relying on auxiliary techniques or adjustments. As illustrated in Figure 1, extensive experiments demonstrate that our method not only reduces computational costs but also consistently outperforms GRPO across various unimodal and multimodal tasks. Our code is available at https://github.com/AMAP-ML/GPG.