Reinforcement Learning for Solving the Pricing Problem in Column Generation: Applications to Vehicle Routing
作者: Abdo Abouelrous, Laurens Bliek, Adriana F. Gabor, Yaoxin Wu, Yingqian Zhang
分类: cs.LG
发布日期: 2025-04-03 (更新: 2025-08-19)
备注: 24 pages, 7 figures, 5 tables, Journal Submission
💡 一句话要点
提出基于强化学习的列生成定价问题求解方法,应用于车辆路径问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 列生成 定价问题 车辆路径问题 注意力机制
📋 核心要点
- 列生成定价问题求解是组合优化中的难题,传统方法依赖启发式算法,效率较低且难以保证解的质量。
- 论文提出基于注意力机制的强化学习模型,直接求解定价问题,无需人工设计的启发式规则,实现端到端优化。
- 实验表明,该方法在车辆路径问题上,能够以更短的运行时间达到与动态规划启发式算法相当的线性松弛目标差距。
📝 摘要(中文)
本文提出了一种使用强化学习(RL)解决列生成(CG)问题的方案。具体而言,我们使用基于注意力机制架构的RL模型来寻找定价问题(PP)中具有最负约简成本的列。与以往CG的机器学习(ML)应用不同,我们的模型部署了一种端到端机制,因为它独立地解决了定价问题,而无需任何启发式的帮助。我们以车辆路径问题(VRP)的一个变体作为我们方法的案例研究。通过一系列实验,将我们的方法与基于动态规划(DP)的启发式算法进行比较,结果表明,我们的方法在显著更短的运行时间内,将线性松弛求解到合理的客观差距。
🔬 方法详解
问题定义:论文旨在解决列生成算法中的定价问题(Pricing Problem),即在每次迭代中找到具有最小约简成本的列。传统方法通常依赖于动态规划等启发式算法,这些算法计算复杂度高,在大规模问题中效率低下,且需要人工设计启发式规则,缺乏通用性。
核心思路:论文的核心思路是利用强化学习(RL)直接学习定价问题的求解策略。通过将定价问题建模为马尔可夫决策过程(MDP),训练一个RL智能体来选择列,目标是最大化约简成本的负值。这种方法避免了人工设计启发式规则的需要,并且可以通过学习来适应不同的问题实例。
技术框架:整体框架包括以下几个主要步骤:1)将车辆路径问题(VRP)的实例转化为定价问题的状态表示;2)使用基于注意力机制的神经网络作为RL智能体的策略网络,该网络接收状态表示作为输入,输出每个列被选择的概率;3)使用策略梯度算法训练RL智能体,目标是最大化奖励函数,奖励函数与约简成本相关;4)将RL智能体选择的列加入到列生成的主问题中,并重复迭代直到满足收敛条件。
关键创新:最重要的技术创新点在于使用端到端的强化学习方法直接求解列生成中的定价问题,而无需任何启发式算法的辅助。以往的机器学习方法通常只是作为启发式算法的补充,而本文的方法则完全取代了启发式算法,实现了真正的端到端优化。此外,使用注意力机制的神经网络可以有效地处理不同规模和结构的定价问题。
关键设计:论文使用基于注意力机制的神经网络作为策略网络,该网络可以学习到不同列之间的相关性,从而更有效地选择列。奖励函数被设计为与约简成本直接相关,以鼓励智能体选择具有最小约简成本的列。使用策略梯度算法(例如REINFORCE或Actor-Critic)来训练RL智能体。具体的参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

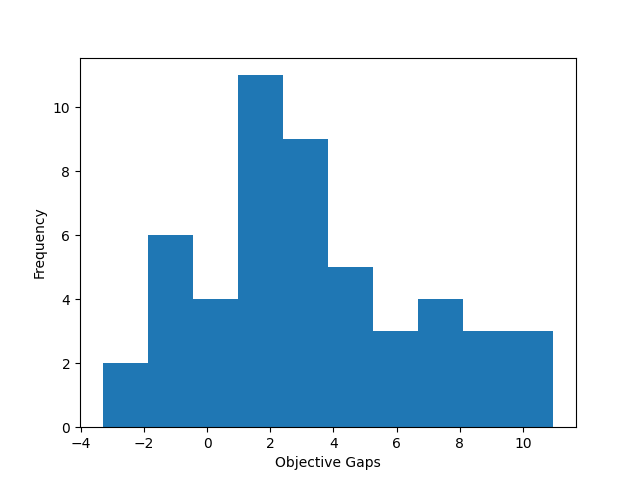

📊 实验亮点
实验结果表明,基于强化学习的列生成定价方法在车辆路径问题上取得了显著的性能提升。与基于动态规划的启发式算法相比,该方法在显著更短的运行时间内,将线性松弛求解到合理的客观差距。具体性能数据(例如运行时间缩短比例、目标差距大小)在论文中进行了详细描述(未知)。
🎯 应用场景
该研究成果可应用于各种组合优化问题,例如车辆路径问题、切割问题、调度问题等,这些问题都可以通过列生成算法进行求解。通过使用强化学习自动学习定价策略,可以显著提高求解效率,降低人工干预,并有望解决更大规模的实际问题。该方法在物流、供应链管理、生产制造等领域具有广泛的应用前景。
📄 摘要(原文)
In this paper, we address the problem of Column Generation (CG) using Reinforcement Learning (RL). Specifically, we use a RL model based on the attention-mechanism architecture to find the columns with most negative reduced cost in the Pricing Problem (PP). Unlike previous Machine Learning (ML) applications for CG, our model deploys an end-to-end mechanism as it independently solves the pricing problem without the help of any heuristic. We consider a variant of Vehicle Routing Problem (VRP) as a case study for our method. Through a set of experiments where our method is compared against a Dynamic Programming (DP)-based heuristic for solving the PP, we show that our method solves the linear relaxation up to a reasonable objective gap in significantly shorter running times.