Reinforcement Fine-Tuning for Materials Design
作者: Zhendong Cao, Lei Wang
分类: cond-mat.mtrl-sci, cs.LG, physics.comp-ph
发布日期: 2025-04-03 (更新: 2026-01-16)
备注: 10 pages, 7 figures
期刊: Phys. Rev. B 113, 024106 (2026)
DOI: 10.1103/45zh-44bg
💡 一句话要点
提出CrystalFormer-RL,利用强化微调提升材料生成模型的设计能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 材料设计 强化学习 生成模型 晶体结构 Transformer 材料属性优化 凸包能量 介电常数
📋 核心要点
- 现有材料生成模型难以有效平衡多种相互冲突的材料属性,限制了其设计能力。
- 利用强化微调,将判别模型的知识融入生成模型,通过奖励信号引导生成过程。
- CrystalFormer-RL在晶体稳定性及发现兼具高介电常数和带隙的晶体方面表现更优。
📝 摘要(中文)
强化微调在提升大型语言模型的指令跟随和推理能力方面发挥了重要作用。本研究将强化微调应用于材料设计,其中判别式机器学习模型用于为基于自回归Transformer的材料生成模型CrystalFormer提供奖励。通过优化奖励信号(如高于凸包的能量和材料性能指标),强化微调将判别式模型的知识注入到生成模型中。由此产生的模型CrystalFormer-RL在生成的晶体中表现出更高的稳定性,并成功发现了具有理想但相互冲突的材料性能(如高介电常数和带隙)的晶体。值得注意的是,我们观察到强化微调不仅实现了基于属性的材料设计,还解锁了预训练生成模型基于属性的材料检索行为。该框架为机器学习生态系统在材料设计中的协同作用开辟了一条令人兴奋的途径。
🔬 方法详解
问题定义:论文旨在解决材料设计中,生成模型难以同时优化多个相互冲突的材料属性的问题。现有的材料生成模型通常难以在保证晶体结构稳定性的同时,实现特定性能指标(如高介电常数和合适的带隙)。这种多目标优化的挑战限制了材料设计的效率和效果。
核心思路:论文的核心思路是利用强化学习(RL)微调预训练的材料生成模型CrystalFormer。通过判别式模型提供的奖励信号,引导生成模型生成具有期望属性的晶体结构。这种方法将判别模型的知识迁移到生成模型中,使其能够更好地平衡多个目标属性。
技术框架:整体框架包含以下几个主要模块:1) 预训练的晶体生成模型CrystalFormer;2) 判别式模型,用于预测生成晶体的各种属性(如能量高于凸包的值、介电常数、带隙等),并提供奖励信号;3) 强化学习算法,用于优化CrystalFormer的生成策略,使其能够最大化累积奖励。具体流程是:CrystalFormer生成晶体结构,判别式模型预测其属性并计算奖励,强化学习算法根据奖励更新CrystalFormer的参数,重复此过程直到模型收敛。
关键创新:最重要的技术创新点在于将强化学习微调应用于材料生成模型,从而实现了属性导向的材料设计。与传统的生成模型相比,CrystalFormer-RL能够更好地利用判别模型的知识,生成具有特定属性组合的晶体结构。此外,该方法还解锁了预训练生成模型基于属性的材料检索能力。
关键设计:奖励函数的设计至关重要,它直接影响了生成模型的优化方向。论文中,奖励函数综合考虑了多个材料属性,如能量高于凸包的值(用于衡量晶体稳定性)、介电常数和带隙。具体形式可能涉及对这些属性进行加权求和或使用更复杂的函数关系。强化学习算法的选择也需要仔细考虑,常见的选择包括策略梯度方法(如REINFORCE、PPO)和值函数方法(如DQN)。此外,还需要调整合适的学习率、折扣因子等超参数。
🖼️ 关键图片
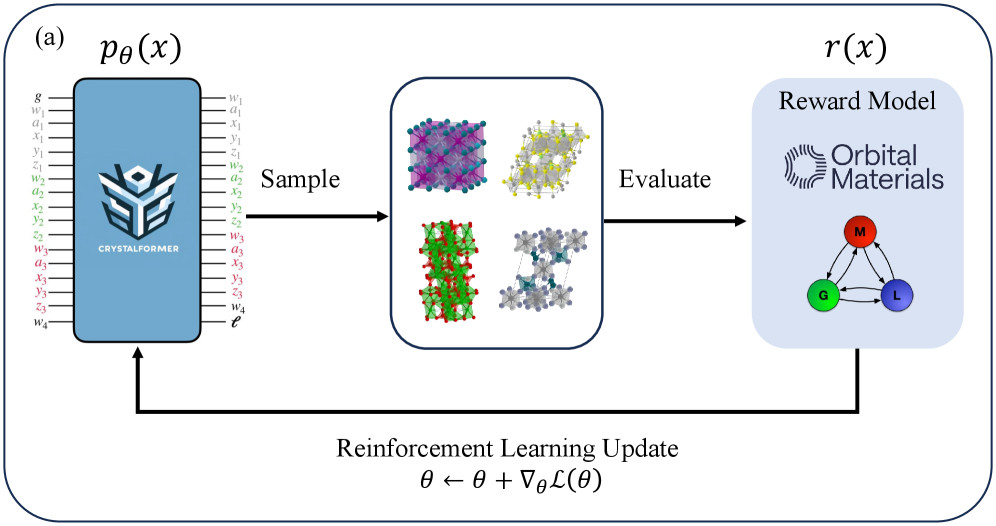
📊 实验亮点
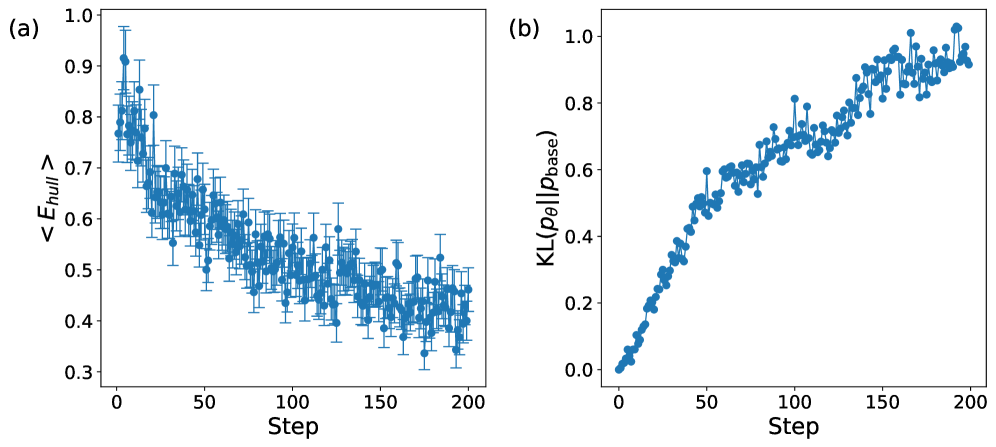
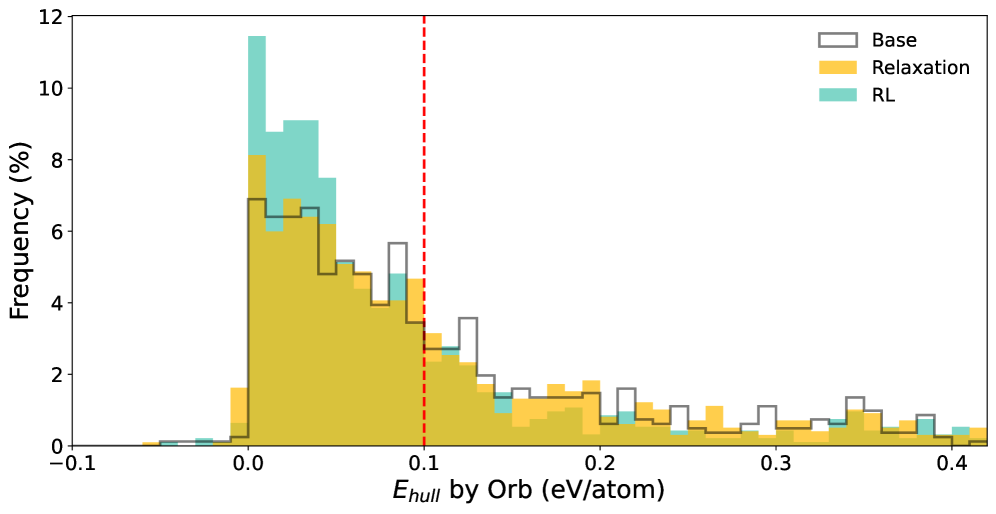
实验结果表明,CrystalFormer-RL在生成晶体结构时表现出更高的稳定性。更重要的是,该模型成功发现了同时具有高介电常数和带隙的晶体,这两种属性通常难以兼得。与未经过强化微调的CrystalFormer相比,CrystalFormer-RL在目标属性的优化方面取得了显著提升,证明了强化微调的有效性。
🎯 应用场景
该研究成果可广泛应用于新材料发现与设计,尤其是在需要同时优化多个相互冲突属性的场景下,例如高性能电子器件、光电器件等。通过该方法,研究人员可以更高效地筛选出具有特定性能组合的候选材料,加速新材料的研发进程,并降低实验成本。未来,该框架有望与高通量计算、自动化合成等技术相结合,实现材料设计的自动化和智能化。
📄 摘要(原文)
Reinforcement fine-tuning played an instrumental role in enhancing the instruction-following and reasoning abilities of large language models. In this work, we employ reinforcement fine-tuning for materials design, in which discriminative machine learning models are used to provide rewards to the autoregressive transformer-based materials generative model CrystalFormer. By optimizing the reward signals-such as energy above the convex hull and material properties figures of merit-reinforcement fine-tuning infuses knowledge from discriminative models into generative models. The resulting model, CrystalFormer-RL, shows enhanced stability in generated crystals and successfully discovers crystals with desirable yet conflicting material properties, such as substantial dielectric constant and band gap simultaneously. Notably, we observe that reinforcement fine-tuning not only enables the property-guided material design but also unlocks property-based material retrieval behavior of pretrained generative model. The present framework opens an exciting gateway to the synergies of the machine learning ecosystem for materials design.