Large EEG-U-Transformer for Time-Step Level Detection Without Pre-Training
作者: Kerui Wu, Ziyue Zhao, Bülent Yener
分类: cs.LG, cs.AI
发布日期: 2025-04-01 (更新: 2025-10-04)
💡 一句话要点
提出Large EEG-U-Transformer,无需预训练即可实现脑电信号时间步级别检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑电信号分析 深度学习 Transformer U型网络 序列建模
📋 核心要点
- 现有脑电信号分析方法参数量小,性能有限,大型模型虽性能好,但依赖耗时预训练和复杂后处理。
- 提出一种U型Transformer模型,利用卷积和自注意力机制,同时捕获局部和全局特征,实现高效序列建模。
- 实验表明,该模型在时间和窗口级别分类任务中均表现出色,无需预训练即可超越现有大型预训练模型。
📝 摘要(中文)
脑电图(EEG)反映大脑的功能状态,是癫痫检测和睡眠分期等多种检测应用的关键工具。虽然基于深度学习的方法最近在自动检测方面显示出希望,但传统模型通常受到有限的可学习参数的约束,并且仅获得适度的性能。相比之下,大型基础模型通过扩大模型尺寸显示出改进的能力,但需要大量耗时的预训练。此外,这两种类型的现有方法都需要复杂且冗余的后处理流程,以将离散标签转换为连续注释。在这项工作中,基于脑电事件的多尺度性质,我们提出了一种简单的U型模型,通过使用卷积和自注意力模块捕获局部和全局特征来进行序列到序列建模,从而有效地学习表示。与其他窗口级别分类模型相比,我们的方法直接输出时间步级别的预测,消除了冗余的重叠推断。除了序列到序列建模之外,该架构通过结合注意力池化层自然地扩展到窗口级别分类。这种范式转变和模型设计在实验中证明了有希望的效率提升、跨主题泛化以及在各种时间步和窗口级别分类任务中的最先进性能。更令人印象深刻的是,我们的模型展示了扩展到与现有大型基础模型相同水平的能力,这些模型已经在各种数据集上进行了广泛的预训练,并且仅使用下游微调数据集就优于它们。我们的模型在人工智能癫痫和其他神经系统疾病国际会议上组织的2025年“癫痫检测挑战赛”中获得第一名。
🔬 方法详解
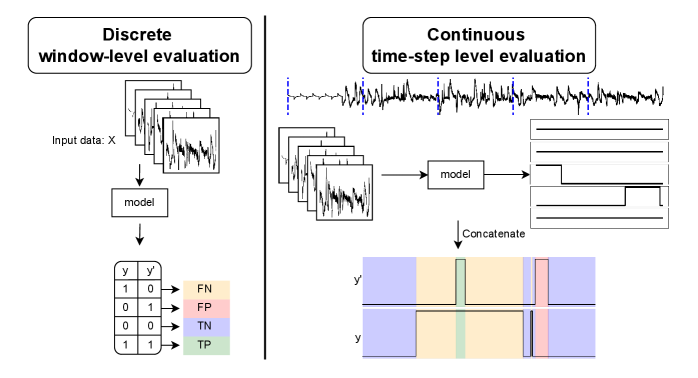
问题定义:现有基于深度学习的脑电信号分析方法,要么是模型参数量小,性能受限;要么是依赖大型预训练模型,需要耗时的预训练过程,并且后处理流程复杂冗余。这些方法难以直接输出时间步级别的预测,需要窗口级别的分类后再进行转换。
核心思路:论文的核心思路是设计一个U型的Transformer模型,该模型能够同时捕获脑电信号的局部和全局特征,从而实现高效的序列到序列建模。U型结构能够有效地提取多尺度特征,而Transformer的自注意力机制则能够捕捉长程依赖关系。
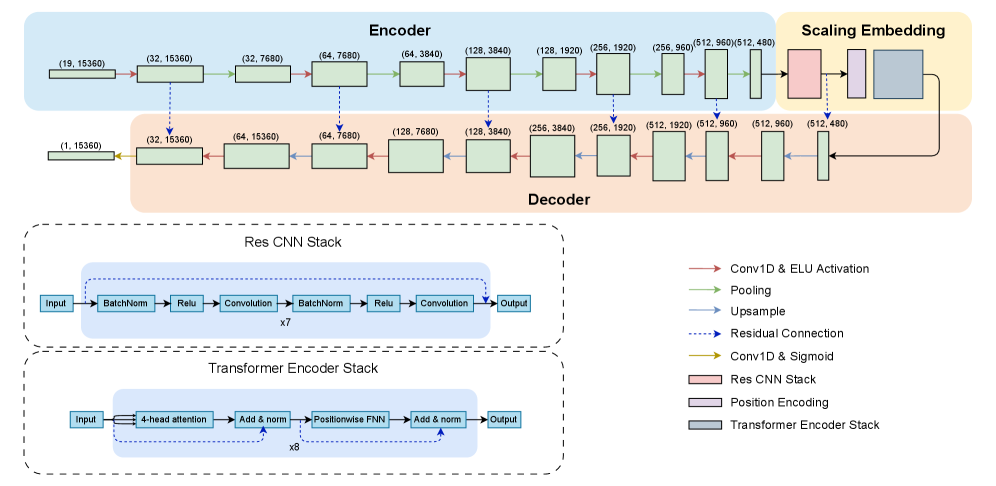
技术框架:整体架构是一个U型的编码器-解码器结构。编码器部分使用卷积层提取局部特征,并逐渐减小特征图尺寸。解码器部分使用自注意力机制进行序列建模,并逐渐恢复特征图尺寸。在编码器和解码器之间存在一个瓶颈层,用于连接上下文信息。对于窗口级别的分类任务,在解码器输出后添加一个注意力池化层,将序列信息聚合为一个向量,然后进行分类。
关键创新:最重要的技术创新点在于U型Transformer结构的设计,它能够有效地结合卷积和自注意力机制的优点,同时捕获局部和全局特征。此外,该模型无需预训练,可以直接在下游任务上进行微调,大大降低了训练成本。直接输出时间步级别的预测,避免了复杂的后处理流程。
关键设计:U型结构的具体层数和每层的卷积核大小、通道数等参数需要根据具体任务进行调整。自注意力机制中,注意力头的数量和维度也需要进行优化。损失函数通常采用交叉熵损失函数,并可以根据具体任务添加正则化项。注意力池化层的设计也至关重要,需要选择合适的池化方式和注意力机制。
🖼️ 关键图片

📊 实验亮点
该模型在癫痫检测挑战赛中获得第一名,证明了其优越的性能。实验结果表明,该模型在时间和窗口级别分类任务中均取得了state-of-the-art的性能,并且无需预训练即可超越现有大型预训练模型。这表明该模型具有很强的泛化能力和效率。
🎯 应用场景
该研究成果可广泛应用于脑电信号分析领域,例如癫痫检测、睡眠分期、脑机接口等。该模型无需预训练的特性,降低了应用门槛,使其更容易部署到资源受限的设备上。时间步级别的预测能力,使其能够更精确地分析脑电信号,为临床诊断提供更可靠的依据。未来可进一步探索其在其他生物信号分析领域的应用。
📄 摘要(原文)
Electroencephalography (EEG) reflects the brain's functional state, making it a crucial tool for diverse detection applications like seizure detection and sleep stage classification. While deep learning-based approaches have recently shown promise for automated detection, traditional models are often constrained by limited learnable parameters and only achieve modest performance. In contrast, large foundation models showed improved capabilities by scaling up the model size, but required extensive time-consuming pre-training. Moreover, both types of existing methods require complex and redundant post-processing pipelines to convert discrete labels to continuous annotations. In this work, based on the multi-scale nature of EEG events, we propose a simple U-shaped model to efficiently learn representations by capturing both local and global features using convolution and self-attentive modules for sequence-to-sequence modeling. Compared to other window-level classification models, our method directly outputs predictions at the time-step level, eliminating redundant overlapping inferences. Beyond sequence-to-sequence modeling, the architecture naturally extends to window-level classification by incorporating an attention-pooling layer. Such a paradigm shift and model design demonstrated promising efficiency improvement, cross-subject generalization, and state-of-the-art performance in various time-step and window-level classification tasks in the experiment. More impressively, our model showed the capability to be scaled up to the same level as existing large foundation models that have been extensively pre-trained over diverse datasets and outperforms them by solely using the downstream fine-tuning dataset. Our model won 1st place in the 2025 "seizure detection challenge" organized in the International Conference on Artificial Intelligence in Epilepsy and Other Neurological Disorders.