Inference-Time Scaling for Complex Tasks: Where We Stand and What Lies Ahead
作者: Vidhisha Balachandran, Jingya Chen, Lingjiao Chen, Shivam Garg, Neel Joshi, Yash Lara, John Langford, Besmira Nushi, Vibhav Vineet, Yue Wu, Safoora Yousefi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-03-31
💡 一句话要点
研究推理时扩展对复杂任务的影响,揭示其局限性与未来潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理时扩展 大型语言模型 复杂任务 反馈机制 数学推理 STEM推理 NP-hard问题 模型评估
📋 核心要点
- 现有大型语言模型在复杂任务中推理能力不足,尤其是在需要逐步解决的问题上,简单增加token数量不一定提高准确性。
- 该研究通过推理时扩展,即重复调用模型并结合反馈,探索提升模型在数学、STEM、规划等复杂任务上的性能。
- 实验结果表明,推理时扩展的优势因任务而异,且存在性能上限,但结合完美验证器或强反馈能显著提升性能。
📝 摘要(中文)
推理时扩展能够增强大型语言模型(LLM)在复杂问题上的推理能力,尤其是在那些受益于逐步问题解决的任务中。虽然延长生成的草稿已被证明对数学任务有效,但这种方法对其他任务的更广泛影响仍不清楚。本文研究了推理时扩展方法在九个最先进的模型和八个具有挑战性的任务中的优势和局限性,包括数学和 STEM 推理、日历规划、NP-hard 问题、导航和空间推理。我们比较了传统模型(例如 GPT-4o)与针对推理时扩展进行微调的模型(例如 o1),通过涉及重复模型调用的评估协议,这些调用可以是独立的,也可以是带有反馈的顺序调用。这些评估近似于每个模型的性能下限和上限,以及未来性能改进的潜力,无论是通过增强训练还是多模型推理系统。我们广泛的实证分析表明,推理时扩展的优势因任务而异,并随着问题复杂性的增加而减弱。此外,简单地使用更多 tokens 并不一定转化为这些具有挑战性的领域中更高的准确性。使用完美验证器的传统模型的多次独立运行结果表明,对于某些任务,这些模型可以达到接近当今最先进的推理模型的平均性能。然而,对于其他任务,即使在非常高的扩展范围内,仍然存在显着的性能差距。令人鼓舞的是,当使用完美验证器或强反馈进一步扩展推理时,所有模型都表现出显着的增益,这表明未来有充足的改进潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂推理任务中,通过简单增加token数量进行推理时扩展所面临的局限性问题。现有方法,如直接增加生成token数量,在复杂问题上收益递减,且缺乏有效的反馈机制来指导推理过程。
核心思路:论文的核心思路是通过更精细的推理时扩展策略,结合重复模型调用和反馈机制,来提升模型在复杂任务上的性能。通过模拟人类逐步推理和验证的过程,使模型能够从错误中学习并改进推理路径。
技术框架:整体框架包括以下几个主要阶段:1) 任务定义:选择具有挑战性的复杂任务,如数学推理、日历规划、NP-hard问题等。2) 模型选择:选取一系列先进的LLM模型,包括通用模型和针对推理时扩展微调的模型。3) 推理时扩展:设计不同的推理时扩展策略,包括独立调用和顺序调用,并引入反馈机制。4) 评估:使用特定的评估指标来衡量模型在不同任务和扩展策略下的性能。
关键创新:论文的关键创新在于系统性地研究了推理时扩展在多种复杂任务上的效果,并揭示了其局限性。此外,论文还探讨了结合完美验证器和强反馈机制来进一步提升模型性能的潜力,为未来的研究方向提供了指导。
关键设计:论文的关键设计包括:1) 任务选择:选择了涵盖不同领域的复杂任务,以评估推理时扩展的泛化能力。2) 模型选择:选择了不同架构和训练方式的LLM模型,以研究模型特性对推理时扩展的影响。3) 反馈机制:设计了不同的反馈机制,包括完美验证器和基于模型生成的反馈,以评估反馈质量对模型性能的影响。4) 评估指标:针对不同任务设计了合适的评估指标,以全面衡量模型的推理能力。
🖼️ 关键图片
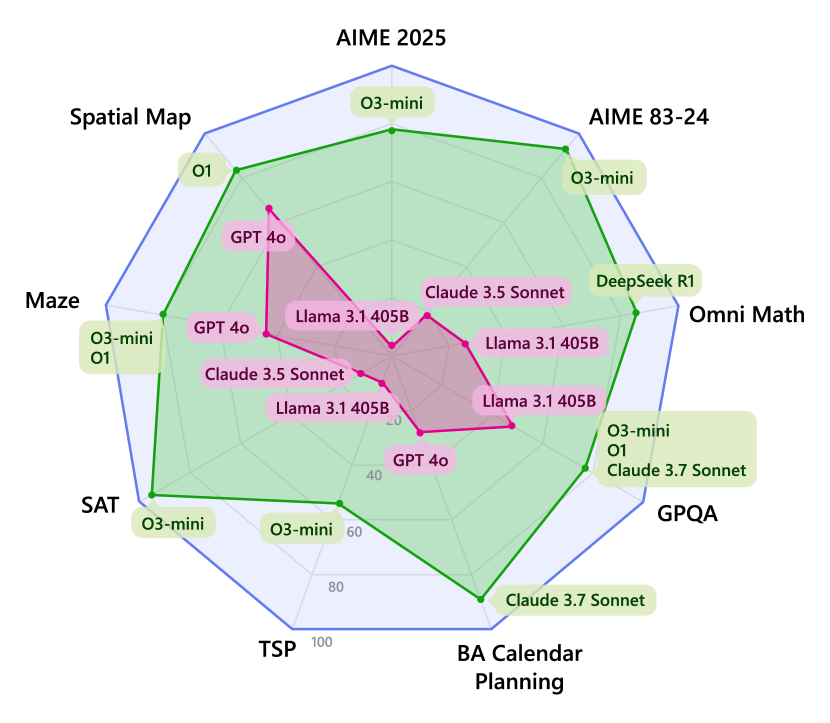
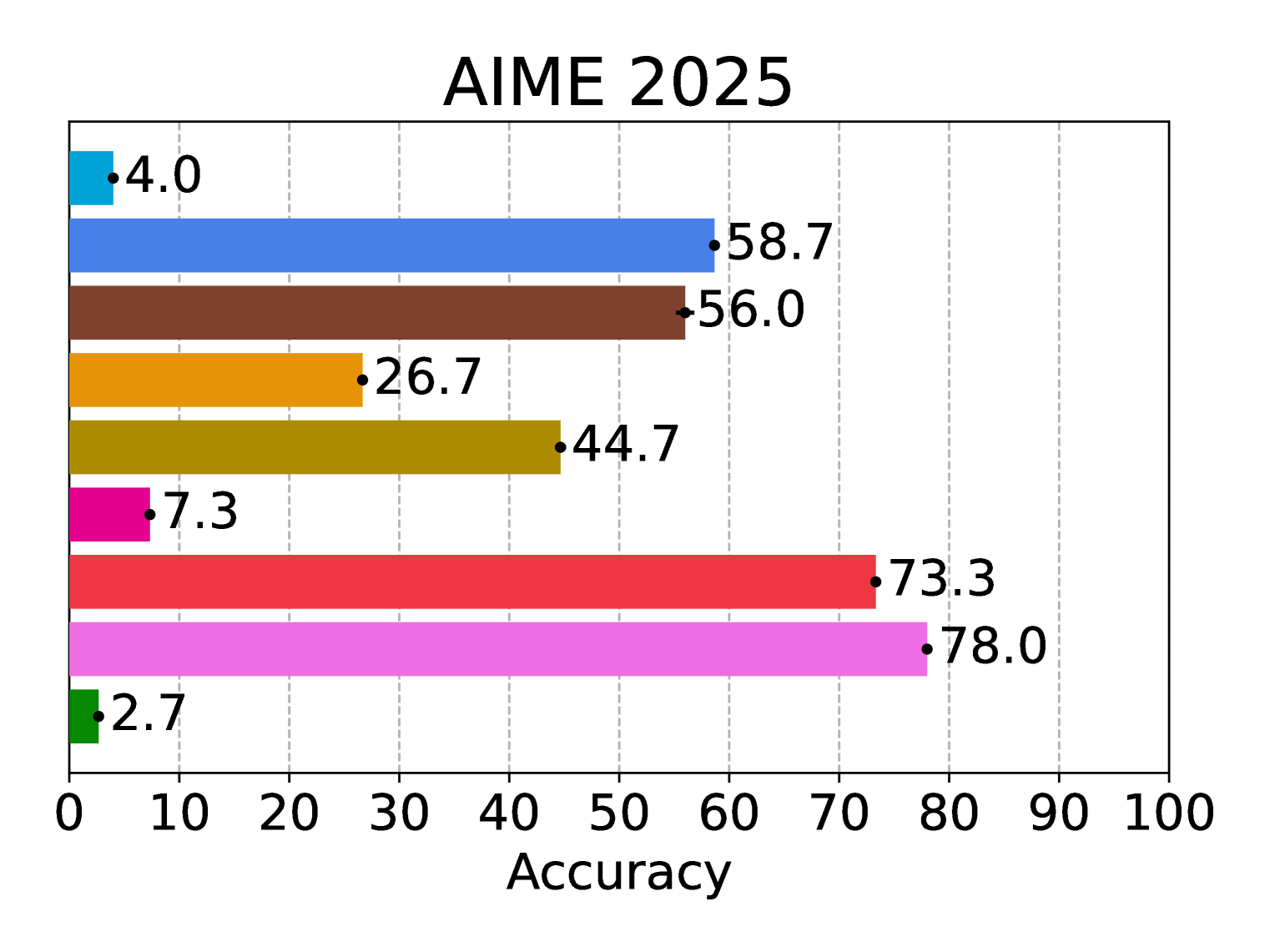
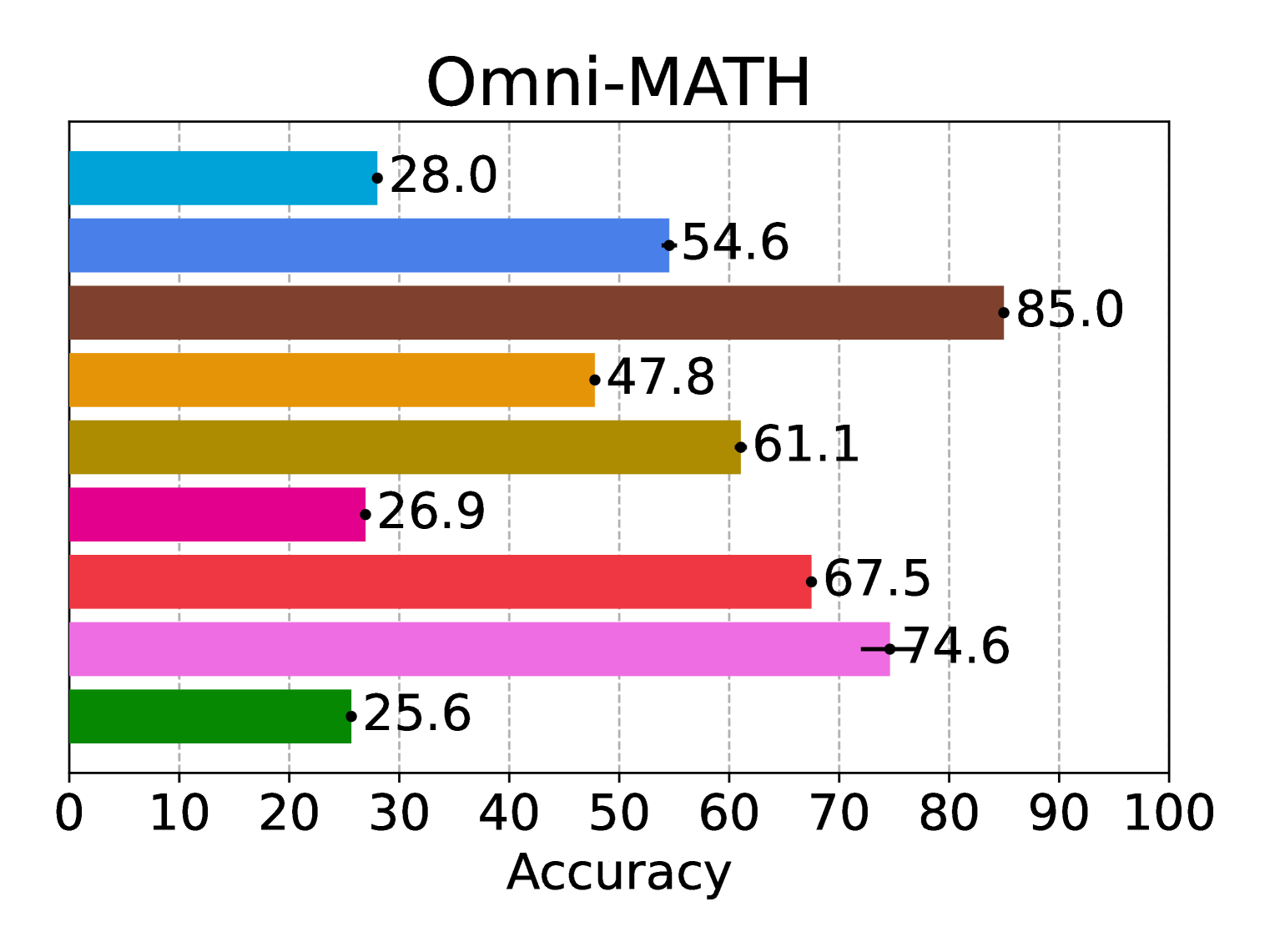
📊 实验亮点
实验结果表明,推理时扩展的优势因任务而异,且随着问题复杂性增加而减弱。对于某些任务,使用完美验证器的传统模型可以达到接近最先进推理模型的平均性能。然而,对于其他任务,即使在高扩展范围内,仍存在显著差距。所有模型在结合完美验证器或强反馈时均表现出显著增益,表明未来有很大的改进空间。
🎯 应用场景
该研究成果可应用于开发更强大的智能助手、自动化问题求解系统和决策支持工具。通过优化推理时扩展策略,可以提升模型在复杂任务中的表现,例如在科学研究、工程设计、金融分析等领域提供更准确、可靠的解决方案。未来的研究可以进一步探索如何设计更有效的反馈机制,以及如何将推理时扩展与其他技术(如知识图谱、符号推理)相结合,以实现更高级的智能。
📄 摘要(原文)
Inference-time scaling can enhance the reasoning capabilities of large language models (LLMs) on complex problems that benefit from step-by-step problem solving. Although lengthening generated scratchpads has proven effective for mathematical tasks, the broader impact of this approach on other tasks remains less clear. In this work, we investigate the benefits and limitations of scaling methods across nine state-of-the-art models and eight challenging tasks, including math and STEM reasoning, calendar planning, NP-hard problems, navigation, and spatial reasoning. We compare conventional models (e.g., GPT-4o) with models fine-tuned for inference-time scaling (e.g., o1) through evaluation protocols that involve repeated model calls, either independently or sequentially with feedback. These evaluations approximate lower and upper performance bounds and potential for future performance improvements for each model, whether through enhanced training or multi-model inference systems. Our extensive empirical analysis reveals that the advantages of inference-time scaling vary across tasks and diminish as problem complexity increases. In addition, simply using more tokens does not necessarily translate to higher accuracy in these challenging regimes. Results from multiple independent runs with conventional models using perfect verifiers show that, for some tasks, these models can achieve performance close to the average performance of today's most advanced reasoning models. However, for other tasks, a significant performance gap remains, even in very high scaling regimes. Encouragingly, all models demonstrate significant gains when inference is further scaled with perfect verifiers or strong feedback, suggesting ample potential for future improvements.