Evaluating and Designing Sparse Autoencoders by Approximating Quasi-Orthogonality
作者: Sewoong Lee, Adam Davies, Marc E. Canby, Julia Hockenmaier
分类: cs.LG, cs.AI
发布日期: 2025-03-31 (更新: 2025-08-08)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于近似准正交性的稀疏自编码器评估与设计方法,解决超参数k选择难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏自编码器 可解释性 近似准正交性 特征激活 超参数优化 top-AFA 语言模型 GPT2
📋 核心要点
- 现有k-稀疏自编码器在选择超参数k时缺乏理论依据,需要手动调整,过程繁琐且缺乏指导。
- 论文提出一种基于近似特征激活(AFA)的理论框架,通过近似准正交性,避免手动选择超参数k。
- 实验表明,提出的top-AFA激活函数在重建GPT2隐藏嵌入时,性能与现有k-稀疏自编码器相当,且无需手动调参。
📝 摘要(中文)
稀疏自编码器(SAE)广泛应用于大型语言模型的可解释性研究。然而,目前最先进的k-稀疏自编码器方法在选择超参数k(代表非零激活的数量,通常表示为ℓ₀)时缺乏理论基础。本文揭示了一个理论联系,即稀疏特征向量的ℓ₂范数可以用稠密向量的ℓ₂范数以闭式误差近似,这使得稀疏自编码器可以在不需要手动确定ℓ₀的情况下进行训练。具体来说,我们验证了理论发现的两个应用。首先,我们引入了一种新的方法,可以通过计算来自输入嵌入的理论期望值来评估预训练SAE的特征激活,这被现有的SAE评估方法和损失函数所忽略。其次,我们引入了一种新的激活函数top-AFA,它建立在我们对近似特征激活(AFA)的公式化之上。该函数实现了top-k风格的激活,而不需要调整常数超参数k,从而动态地确定每个输入的激活特征数量。通过在三个中间层上训练SAE来重建来自OpenWebText数据集的超过8000万个token的GPT2隐藏嵌入,我们证明了该方法的经验优势,并将其与当前最先进的k-稀疏自编码器进行了比较。我们的代码可在https://github.com/SewoongLee/top-afa-sae获得。
🔬 方法详解
问题定义:现有稀疏自编码器(SAE)依赖于手动调整超参数k(代表稀疏度),以控制激活特征的数量。然而,选择合适的k值缺乏理论指导,导致调参过程耗时且效果不佳。这限制了SAE在大型语言模型可解释性研究中的应用。
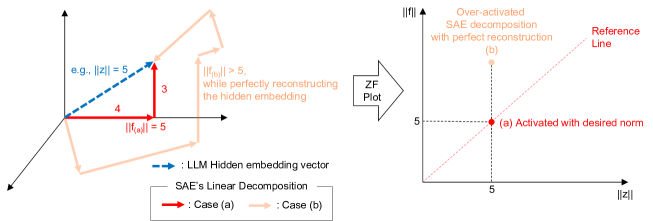
核心思路:论文的核心思路是利用近似准正交性,建立稀疏特征向量的ℓ₂范数与稠密向量的ℓ₂范数之间的理论联系。通过这种联系,可以推导出特征激活的理论期望值,从而在训练SAE时无需手动指定超参数k。
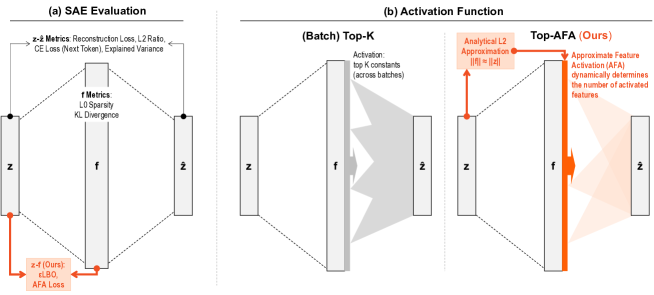
技术框架:论文的技术框架主要包含两个部分:1) 基于近似准正交性的理论推导,用于评估预训练SAE的特征激活;2) 基于近似特征激活(AFA)的新型激活函数top-AFA。整体流程是:首先利用理论推导评估现有SAE,然后基于AFA设计top-AFA激活函数,最后训练SAE并进行实验验证。
关键创新:论文的关键创新在于提出了top-AFA激活函数,它能够动态地确定每个输入的激活特征数量,而无需手动调整超参数k。与传统的top-k激活函数相比,top-AFA基于理论推导,具有更强的自适应性和理论支撑。
关键设计:top-AFA激活函数的设计基于对近似特征激活(AFA)的公式化。具体来说,该函数利用输入嵌入的统计信息来估计每个神经元的激活概率,并根据这些概率动态地选择激活的特征。损失函数采用标准的自编码器重建损失,并可能包含额外的正则化项以促进稀疏性。
🖼️ 关键图片
📊 实验亮点
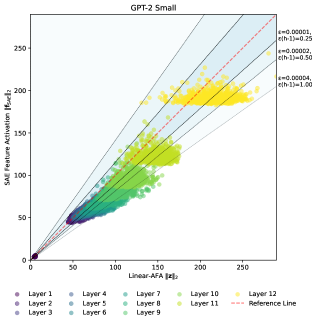
实验结果表明,提出的top-AFA激活函数在重建GPT2隐藏嵌入时,性能与当前最先进的k-稀疏自编码器相当。更重要的是,top-AFA无需手动调整超参数k,显著简化了训练流程。在超过8000万个token的数据集上进行了验证,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于大型语言模型的可解释性分析,帮助研究人员理解模型内部的特征表示。通过自动确定稀疏自编码器的稀疏度,可以简化训练流程,提高效率。此外,该方法还可以推广到其他需要稀疏表示的机器学习任务中,例如特征选择和降维。
📄 摘要(原文)
Sparse autoencoders (SAEs) are widely used in mechanistic interpretability research for large language models; however, the state-of-the-art method of using $k$-sparse autoencoders lacks a theoretical grounding for selecting the hyperparameter $k$ that represents the number of nonzero activations, often denoted by $\ell_0$. In this paper, we reveal a theoretical link that the $\ell_2$-norm of the sparse feature vector can be approximated with the $\ell_2$-norm of the dense vector with a closed-form error, which allows sparse autoencoders to be trained without the need to manually determine $\ell_0$. Specifically, we validate two applications of our theoretical findings. First, we introduce a new methodology that can assess the feature activations of pre-trained SAEs by computing the theoretically expected value from the input embedding, which has been overlooked by existing SAE evaluation methods and loss functions. Second, we introduce a novel activation function, top-AFA, which builds upon our formulation of approximate feature activation (AFA). This function enables top-$k$ style activation without requiring a constant hyperparameter $k$ to be tuned, dynamically determining the number of activated features for each input. By training SAEs on three intermediate layers to reconstruct GPT2 hidden embeddings for over 80 million tokens from the OpenWebText dataset, we demonstrate the empirical merits of this approach and compare it with current state-of-the-art $k$-sparse autoencoders. Our code is available at: https://github.com/SewoongLee/top-afa-sae.