TransMamba: A Sequence-Level Hybrid Transformer-Mamba Language Model
作者: Yixing Li, Ruobing Xie, Zhen Yang, Xingwu Sun, Shuaipeng Li, Weidong Han, Zhanhui Kang, Yu Cheng, Chengzhong Xu, Di Wang, Jie Jiang
分类: cs.LG
发布日期: 2025-03-31 (更新: 2026-01-07)
备注: Accepted by AAAI 2026. Code: https://github.com/Yixing-Li/TransMamba
🔗 代码/项目: GITHUB
💡 一句话要点
提出TransMamba,一种序列级混合Transformer-Mamba语言模型,提升长序列建模效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer Mamba 状态空间模型 长序列建模 混合架构 语言模型 注意力机制
📋 核心要点
- Transformer在长序列处理中面临二次复杂度挑战,限制了效率。
- TransMamba通过共享参数矩阵在序列级别统一Transformer和Mamba,动态切换机制。
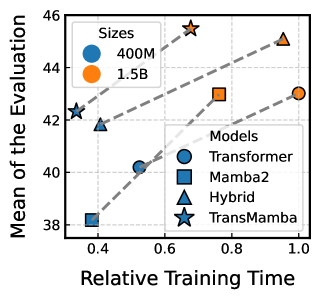
- 实验表明TransMamba在训练效率和性能上优于现有模型,验证了两种范式的一致性。
📝 摘要(中文)
Transformer是现代大型语言模型的基石,但其二次计算复杂度限制了长序列处理的效率。Mamba作为一种具有线性复杂度的状态空间模型(SSM),在效率方面提供了有希望的提升,但存在不稳定的上下文学习和多任务泛化问题。一些工作采用层级混合结构,结合Transformer和Mamba层,旨在充分利用两者的优势。本文提出TransMamba,一种新颖的序列级混合框架,通过共享参数矩阵(QKV和CBx)统一Transformer和Mamba,从而可以在不同token长度和层动态切换注意力机制和SSM机制。我们设计了Memory Converter,通过将注意力输出转换为SSM兼容的状态来桥接Transformer和Mamba,确保在TransPoint发生转换时的无缝信息流。还深入研究了TransPoint调度,以平衡有效性和效率。大量的实验表明,与单一和混合基线相比,TransMamba实现了卓越的训练效率和性能,并验证了Transformer和Mamba范式在序列级别上更深层次的一致性,为下一代语言建模提供了可扩展的解决方案。
🔬 方法详解
问题定义:现有的大型语言模型主要依赖Transformer架构,但在处理长序列时,Transformer的计算复杂度呈二次方增长,导致计算成本高昂和效率低下。Mamba等状态空间模型虽然具有线性复杂度,但在上下文学习和多任务泛化方面存在不足。因此,如何有效地结合Transformer和Mamba的优势,构建高效且性能优越的语言模型是一个关键问题。
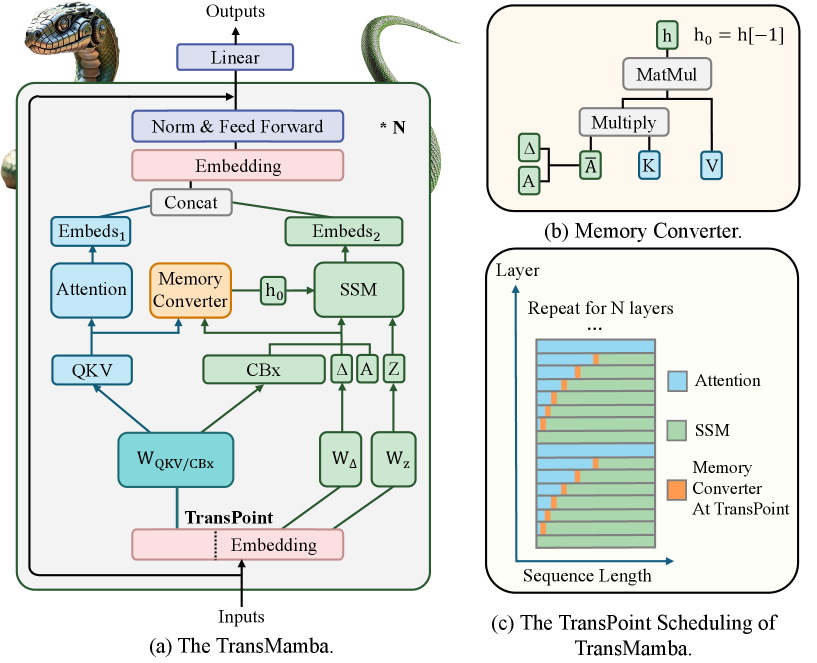
核心思路:TransMamba的核心思路是在序列级别上混合Transformer和Mamba,通过共享参数矩阵(QKV和CBx)将两者统一起来。这种设计允许模型在不同的token长度和层动态地切换注意力机制和SSM机制,从而兼顾了Transformer的强大表示能力和Mamba的高效计算特性。通过Memory Converter模块,实现Transformer和Mamba之间的无缝信息传递。
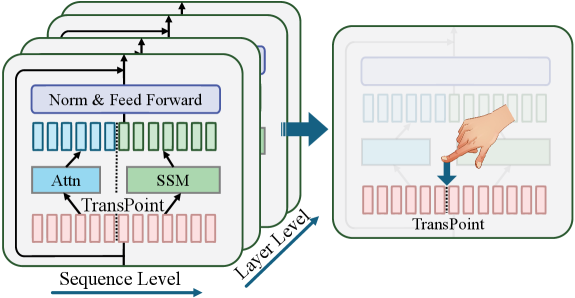
技术框架:TransMamba的整体架构包含Transformer层、Mamba层以及TransPoint。在TransPoint处,Memory Converter模块将Transformer的注意力输出转换为Mamba可以接受的状态表示,反之亦然。TransPoint的调度策略决定了在哪些层和哪些token位置进行Transformer和Mamba之间的切换。整个流程旨在实现两种模型的优势互补,提高长序列建模的效率和性能。
关键创新:TransMamba的关键创新在于序列级别的混合架构以及Memory Converter的设计。与以往的层级混合方法不同,TransMamba允许在更细粒度的序列级别上进行Transformer和Mamba的切换,从而更加灵活地适应不同的输入序列和任务需求。Memory Converter保证了两种模型之间信息的无损传递,避免了信息瓶颈。
关键设计:TransMamba的关键设计包括:1) 共享参数矩阵(QKV和CBx),减少模型参数量,提高训练效率;2) Memory Converter,采用线性变换将Transformer的注意力输出映射到Mamba的状态空间,反之亦然;3) TransPoint调度策略,通过实验确定最佳的Transformer和Mamba切换位置,平衡效率和性能。具体的损失函数和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
TransMamba在多个长序列建模任务上取得了显著的性能提升。实验结果表明,TransMamba在训练效率上优于传统的Transformer模型和现有的混合模型,同时在困惑度等指标上也有明显改善。具体的数据和对比结果可以在论文的实验部分找到。
🎯 应用场景
TransMamba在长文本生成、语音识别、视频理解等需要处理长序列数据的领域具有广泛的应用前景。其高效的计算特性使其能够处理更长的上下文信息,从而提高模型在这些任务上的性能。此外,TransMamba还可以应用于低资源场景,通过更少的计算资源实现更好的效果,具有重要的实际价值和未来影响。
📄 摘要(原文)
Transformers are the cornerstone of modern large language models, but their quadratic computational complexity limits efficiency in long-sequence processing. Recent advancements in Mamba, a state space model (SSM) with linear complexity, offer promising efficiency gains but suffer from unstable contextual learning and multitask generalization. Some works conduct layer-level hybrid structures that combine Transformer and Mamba layers, aiming to make full use of both advantages. This paper proposes TransMamba, a novel sequence-level hybrid framework that unifies Transformer and Mamba through shared parameter matrices (QKV and CBx), and thus could dynamically switch between attention and SSM mechanisms at different token lengths and layers. We design the Memory Converter to bridge Transformer and Mamba by converting attention outputs into SSM-compatible states, ensuring seamless information flow at TransPoints where the transformation happens. The TransPoint scheduling is also thoroughly explored for balancing effectiveness and efficiency. We conducted extensive experiments demonstrating that TransMamba achieves superior training efficiency and performance compared to single and hybrid baselines, and validated the deeper consistency between Transformer and Mamba paradigms at sequence level, offering a scalable solution for next-generation language modeling. Code and data are available at https://github.com/Yixing-Li/TransMamba