Rethinking Key-Value Cache Compression Techniques for Large Language Model Serving
作者: Wei Gao, Xinyu Zhou, Peng Sun, Tianwei Zhang, Yonggang Wen
分类: cs.LG, cs.AI
发布日期: 2025-03-31
备注: 21 pages, 18 figures, published to MLSys2025
🔗 代码/项目: GITHUB
💡 一句话要点
重新审视大语言模型服务的键值缓存压缩技术,提升实际部署性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 键值缓存压缩 大型语言模型 LLM服务 性能优化 实证研究
📋 核心要点
- 现有KV缓存压缩算法在生产环境中的应用受限,原因在于性能评估不完善,未能充分考虑实际部署中的计算效率。
- 论文通过实证评估主流KV缓存压缩方法,揭示了现有实现未针对生产级LLM服务优化,以及压缩可能导致输出变长的问题。
- 论文开源了相关工具,旨在促进KV缓存压缩技术的研究和实际部署,帮助解决现有方法在生产环境中的局限性。
📝 摘要(中文)
键值缓存(KV缓存)压缩已成为优化大型语言模型(LLM)服务的一种有前景的技术。它主要通过减少KV缓存的内存消耗来降低计算成本。尽管已经开发了许多压缩算法,但它们在生产环境中的应用仍然不普遍。本文从实践的角度重新审视了主流的KV缓存压缩解决方案。我们的贡献有三方面:首先,我们全面回顾了现有的KV缓存压缩算法设计和基准研究,并指出了其性能测量中缺失的部分,这可能会阻碍它们在实践中的应用。其次,我们实证评估了代表性的KV缓存压缩方法,揭示了影响计算效率的两个关键问题:(1)虽然压缩KV缓存可以减少内存消耗,但当前的实现(例如,FlashAttention,PagedAttention)没有针对生产级别的LLM服务进行优化,导致吞吐量性能欠佳;(2)压缩KV缓存可能导致更长的输出,从而增加端到端延迟。我们进一步研究了单个样本的准确性性能,而不是整体性能,揭示了KV缓存压缩在处理特定LLM任务时的内在局限性。第三,我们提供了工具来阐明未来的KV缓存压缩研究,并促进它们在生产中的实际部署。它们已在https://github.com/LLMkvsys/rethink-kv-compression上开源。
🔬 方法详解
问题定义:论文旨在解决现有KV缓存压缩技术在实际LLM服务部署中性能不佳的问题。现有方法虽然能减少内存消耗,但未充分优化计算效率,导致吞吐量下降和端到端延迟增加。此外,压缩还可能影响特定LLM任务的准确性。
核心思路:论文的核心思路是从实践角度重新审视KV缓存压缩技术,通过实证评估揭示现有方法的不足,并提供工具来促进更高效的压缩算法设计和部署。重点关注压缩对吞吐量、延迟和准确性的影响,特别是针对生产环境下的LLM服务。
技术框架:论文没有提出新的压缩算法,而是采用实证研究的方法。主要流程包括:1) 回顾现有KV缓存压缩算法和基准研究;2) 选择代表性算法进行性能评估;3) 分析压缩对吞吐量、延迟和准确性的影响;4) 开源相关工具,方便后续研究和部署。
关键创新:论文的关键创新在于其研究视角,即从实际部署的角度评估KV缓存压缩技术。不同于以往侧重理论性能的研究,本文关注压缩在生产环境下的真实表现,并揭示了现有方法在计算效率和准确性方面的局限性。
关键设计:论文没有涉及具体的算法设计细节,而是侧重于实验评估和分析。关键在于选择具有代表性的KV缓存压缩算法,并设计合理的实验来评估其在不同LLM任务下的性能表现。此外,开源工具的提供也方便了后续研究者进行类似的评估和优化。
🖼️ 关键图片

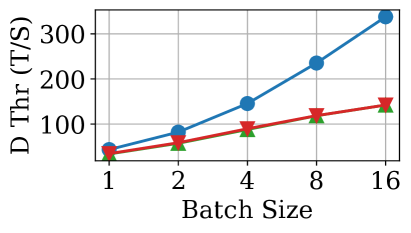
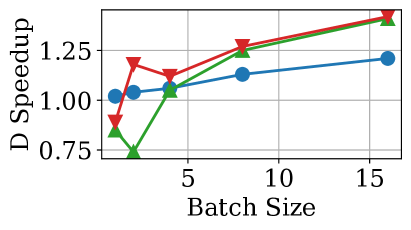
📊 实验亮点
论文通过实验发现,虽然KV缓存压缩可以减少内存消耗,但现有实现并未针对生产级LLM服务进行优化,导致吞吐量性能下降。此外,压缩还可能导致输出变长,增加端到端延迟。对单个样本准确性的分析揭示了压缩在处理特定LLM任务时的局限性。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型的场景,例如在线问答系统、文本生成服务、机器翻译等。通过优化KV缓存压缩技术,可以降低LLM服务的部署成本,提高服务质量,并加速LLM技术的普及和应用。
📄 摘要(原文)
Key-Value cache (\texttt{KV} \texttt{cache}) compression has emerged as a promising technique to optimize Large Language Model (LLM) serving. It primarily decreases the memory consumption of \texttt{KV} \texttt{cache} to reduce the computation cost. Despite the development of many compression algorithms, their applications in production environments are still not prevalent. In this paper, we revisit mainstream \texttt{KV} \texttt{cache} compression solutions from a practical perspective. Our contributions are three-fold. First, we comprehensively review existing algorithmic designs and benchmark studies for \texttt{KV} \texttt{cache} compression and identify missing pieces in their performance measurement, which could hinder their adoption in practice. Second, we empirically evaluate representative \texttt{KV} \texttt{cache} compression methods to uncover two key issues that affect the computational efficiency: (1) while compressing \texttt{KV} \texttt{cache} can reduce memory consumption, current implementations (e.g., FlashAttention, PagedAttention) do not optimize for production-level LLM serving, resulting in suboptimal throughput performance; (2) compressing \texttt{KV} \texttt{cache} may lead to longer outputs, resulting in increased end-to-end latency. We further investigate the accuracy performance of individual samples rather than the overall performance, revealing the intrinsic limitations in \texttt{KV} \texttt{cache} compression when handling specific LLM tasks. Third, we provide tools to shed light on future \texttt{KV} \texttt{cache} compression studies and facilitate their practical deployment in production. They are open-sourced in \href{https://github.com/LLMkvsys/rethink-kv-compression}{https://github.com/LLMkvsys/rethink-kv-compression}.