Handling Delay in Real-Time Reinforcement Learning
作者: Ivan Anokhin, Rishav Rishav, Matthew Riemer, Stephen Chung, Irina Rish, Samira Ebrahimi Kahou
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-03-30
备注: Accepted at ICLR 2025. Code available at https://github.com/avecplezir/realtime-agent
💡 一句话要点
提出时序跳跃连接与历史增强观测,解决实时强化学习中的延迟问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 实时强化学习 观测延迟 时序跳跃连接 历史增强观测 并行计算 机器人控制 动态环境
📋 核心要点
- 实时强化学习受硬件限制,存在动作频率约束和观测延迟问题,降低了策略的有效性。
- 论文提出时序跳跃连接和历史增强观测,旨在减少延迟的同时保持网络的表达能力。
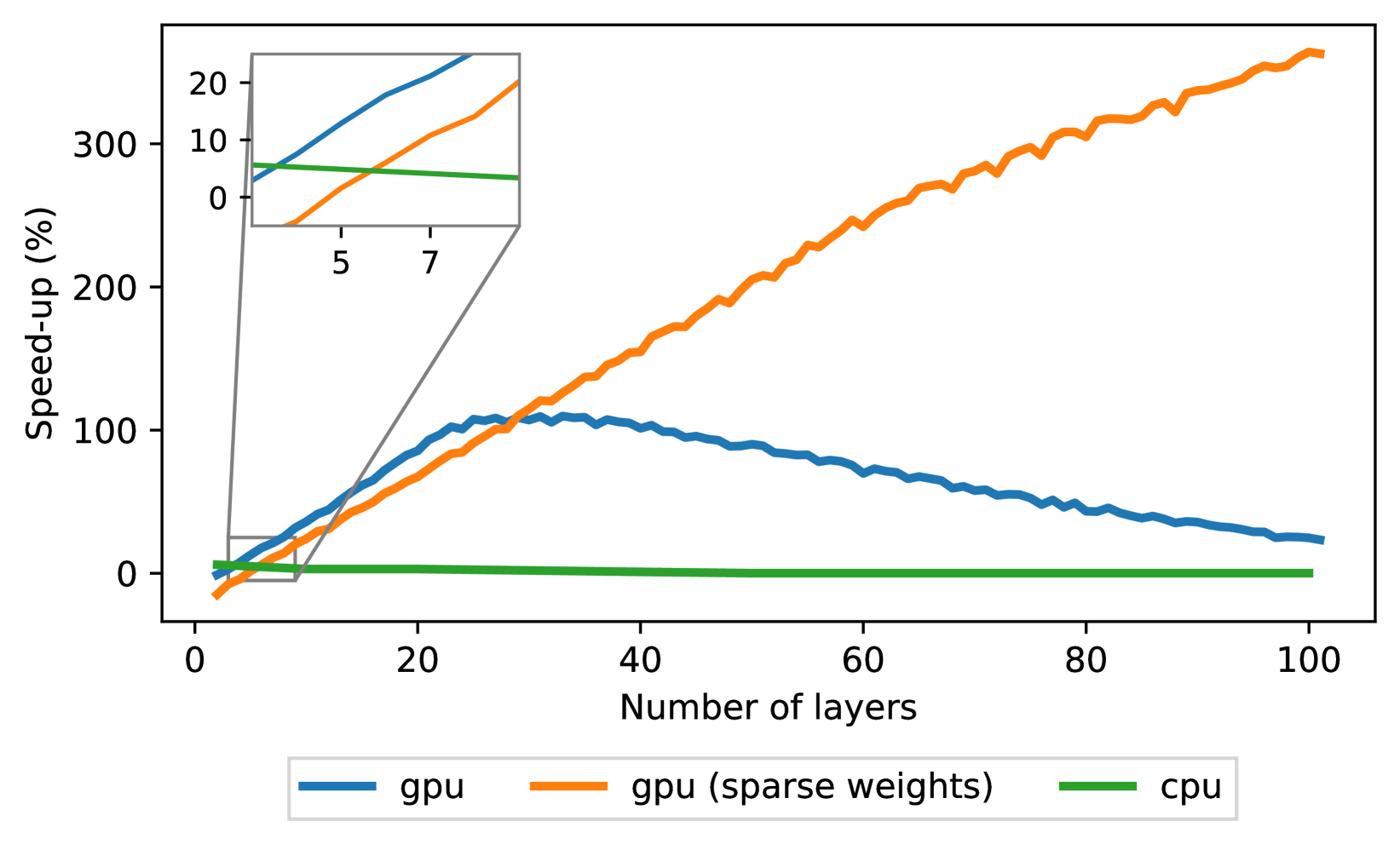
- 实验证明,该方法在多个环境和算法中表现优异,并能通过并行计算显著加速推理过程。
📝 摘要(中文)
实时强化学习面临诸多挑战,包括硬件限制导致的固定动作频率和观测延迟。观测延迟源于神经网络计算时间,尤其是在多层网络中。减少网络层数虽能降低延迟,但会牺牲表达能力。本文探讨了最小化延迟与网络表达能力之间的权衡,提出了一种理论驱动的解决方案,结合时序跳跃连接和历史增强观测。实验结果表明,包含时序跳跃连接的架构在不同神经元执行时间、强化学习算法和环境(包括四个Mujoco任务和所有MinAtar游戏)中均表现出色。此外,并行神经元计算在标准硬件上加速了6-350%的推理速度。这项研究为实时环境中更高效的强化学习智能体铺平了道路。
🔬 方法详解
问题定义:实时强化学习中,由于硬件限制,智能体每秒只能执行固定数量的动作。更关键的是,神经网络在计算动作时,环境可能已经发生变化,导致观测延迟。对于一个N层的前馈网络,如果每层神经元的执行时间为τ,则总的观测延迟为τN。减少网络层数可以降低延迟,但会牺牲网络的表达能力,影响学习效果。现有方法难以在延迟和表达能力之间取得平衡。
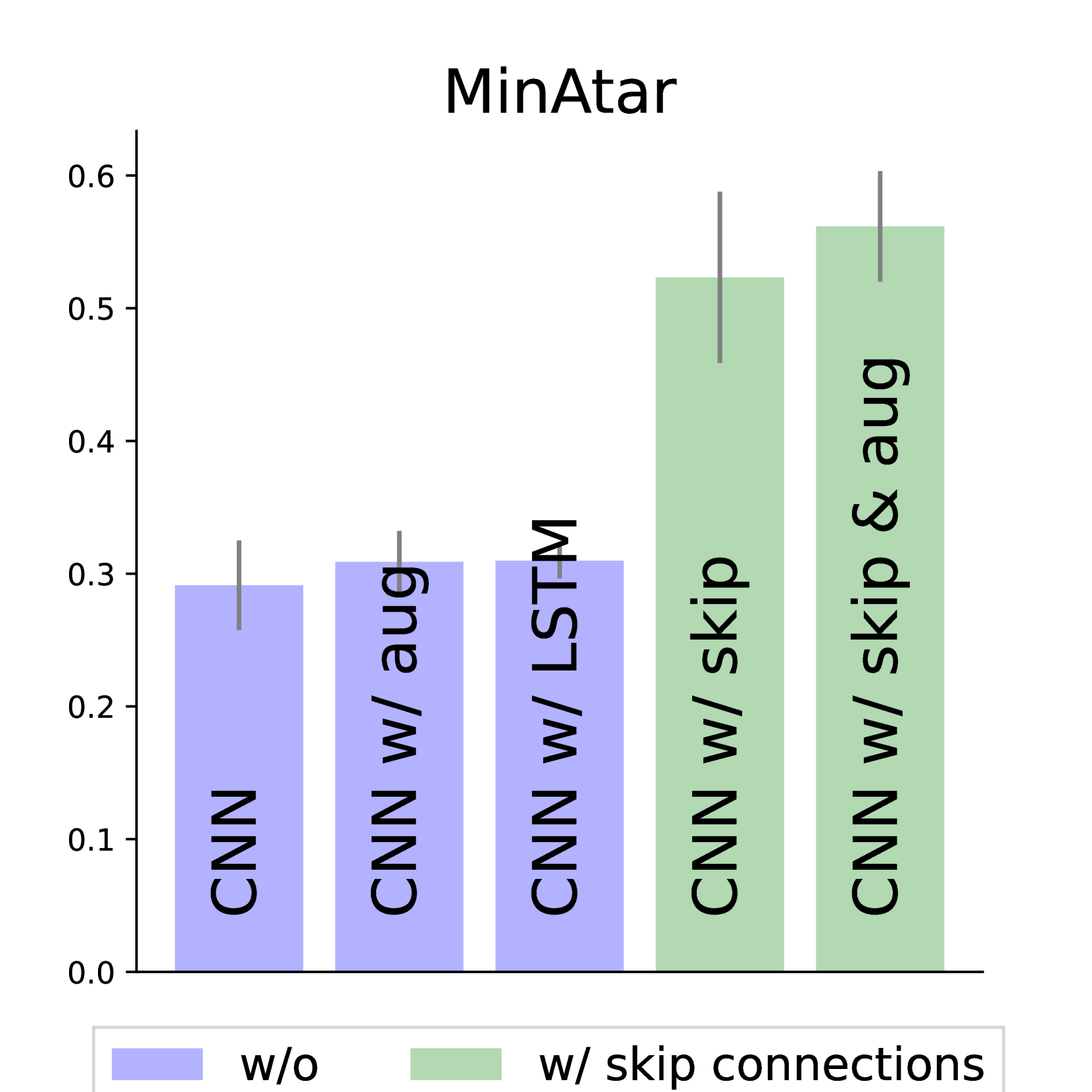
核心思路:论文的核心思路是利用时序跳跃连接(temporal skip connections)来减少有效网络深度,从而降低观测延迟。同时,为了弥补网络表达能力的损失,引入历史增强观测(history-augmented observations),即在当前观测中加入过去的状态信息,使智能体能够更好地理解环境的动态变化。
技术框架:整体框架包括一个强化学习智能体,该智能体接收环境的观测作为输入,并输出动作。智能体的核心是一个神经网络,该网络包含多个层,并具有时序跳跃连接。智能体使用历史增强观测作为输入,即当前观测与过去若干个时间步的观测的组合。智能体使用标准的强化学习算法(如DQN、PPO等)进行训练。
关键创新:最重要的技术创新点在于时序跳跃连接的使用。传统的神经网络是逐层计算的,而时序跳跃连接允许信息直接从较早的层传递到较晚的层,从而减少了有效网络深度,降低了观测延迟。此外,历史增强观测的使用也提高了智能体对环境动态变化的感知能力。
关键设计:时序跳跃连接的具体实现方式是将较早层的输出直接添加到较晚层的输入中。历史增强观测的具体实现方式是将过去若干个时间步的观测与当前观测拼接在一起。论文还探索了不同的网络结构和超参数设置,以优化性能。损失函数采用标准的强化学习损失函数,如DQN的TD误差或PPO的策略梯度损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,包含时序跳跃连接的架构在Mujoco和MinAtar等多个环境中均取得了显著的性能提升。例如,在某些Mujoco任务中,该方法能够达到与传统方法相当甚至更高的性能,同时显著降低了观测延迟。此外,通过并行神经元计算,推理速度提升了6-350%。
🎯 应用场景
该研究成果可应用于需要实时决策的机器人控制、自动驾驶、游戏AI等领域。通过降低观测延迟,可以提高智能体在动态环境中的反应速度和决策质量,使其能够更好地适应复杂和变化的环境。未来,该方法有望应用于更广泛的实时控制系统,提升系统的智能化水平。
📄 摘要(原文)
Real-time reinforcement learning (RL) introduces several challenges. First, policies are constrained to a fixed number of actions per second due to hardware limitations. Second, the environment may change while the network is still computing an action, leading to observational delay. The first issue can partly be addressed with pipelining, leading to higher throughput and potentially better policies. However, the second issue remains: if each neuron operates in parallel with an execution time of $τ$, an $N$-layer feed-forward network experiences observation delay of $τN$. Reducing the number of layers can decrease this delay, but at the cost of the network's expressivity. In this work, we explore the trade-off between minimizing delay and network's expressivity. We present a theoretically motivated solution that leverages temporal skip connections combined with history-augmented observations. We evaluate several architectures and show that those incorporating temporal skip connections achieve strong performance across various neuron execution times, reinforcement learning algorithms, and environments, including four Mujoco tasks and all MinAtar games. Moreover, we demonstrate parallel neuron computation can accelerate inference by 6-350% on standard hardware. Our investigation into temporal skip connections and parallel computations paves the way for more efficient RL agents in real-time setting.