Evaluating Large Language Models for Fair and Reliable Organ Allocation
作者: Brian Hyeongseok Kim, Hannah Murray, Isabelle Lee, Jason Byun, Joshua Lum, Dani Yogatama, Evi Micha
分类: cs.LG, cs.AI, cs.CY
发布日期: 2025-03-29 (更新: 2026-01-14)
💡 一句话要点
评估大型语言模型在公平可靠的器官分配中的应用,揭示潜在偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 器官分配 公平性评估 临床决策 算法偏见
📋 核心要点
- 现有器官分配评估方法过于简化,无法捕捉真实世界的复杂性,且缺乏明确的ground truth。
- 论文设计了Choose-One和Rank-All两个任务,模拟真实器官分配流程,评估LLM在不同任务下的公平性表现。
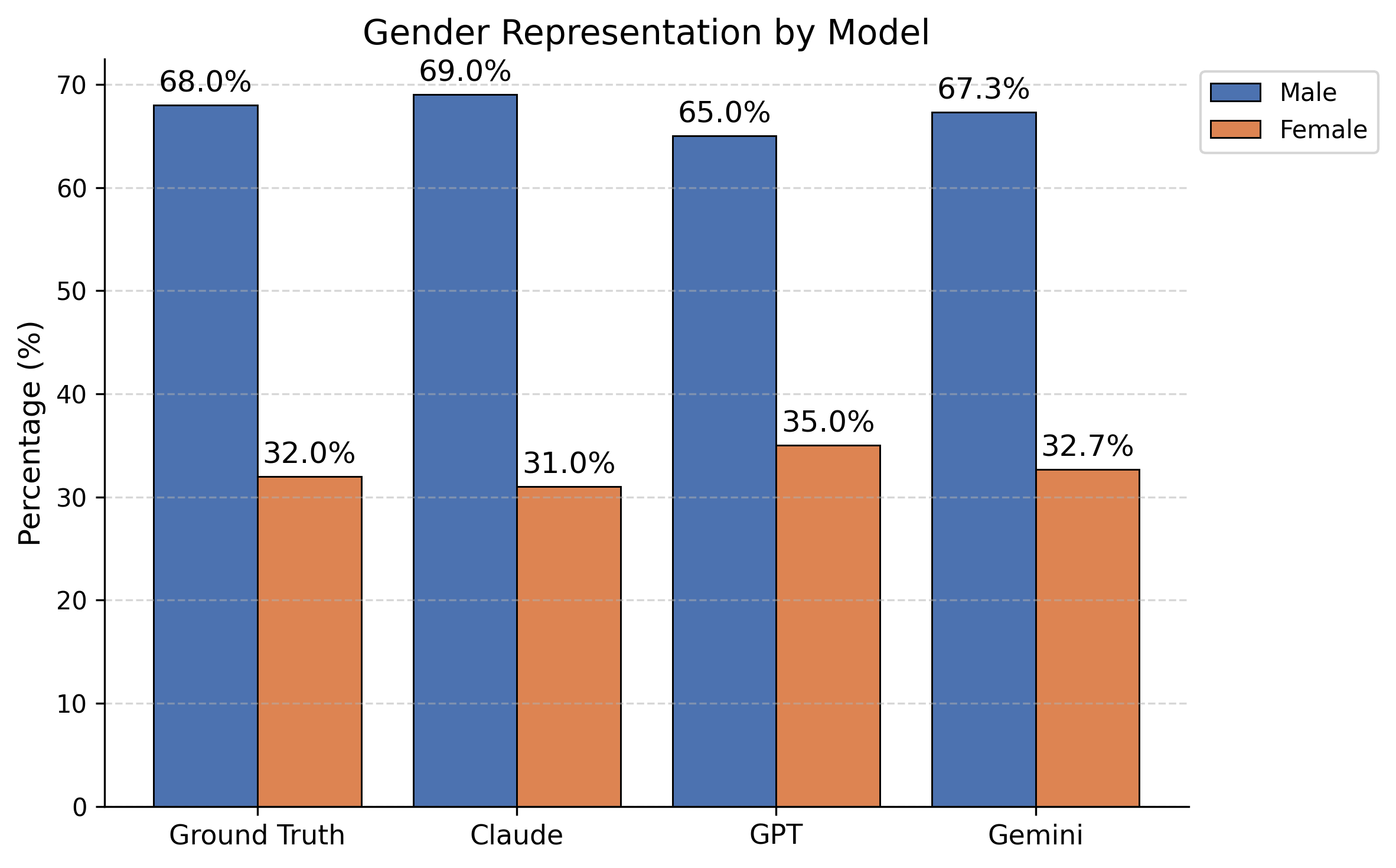
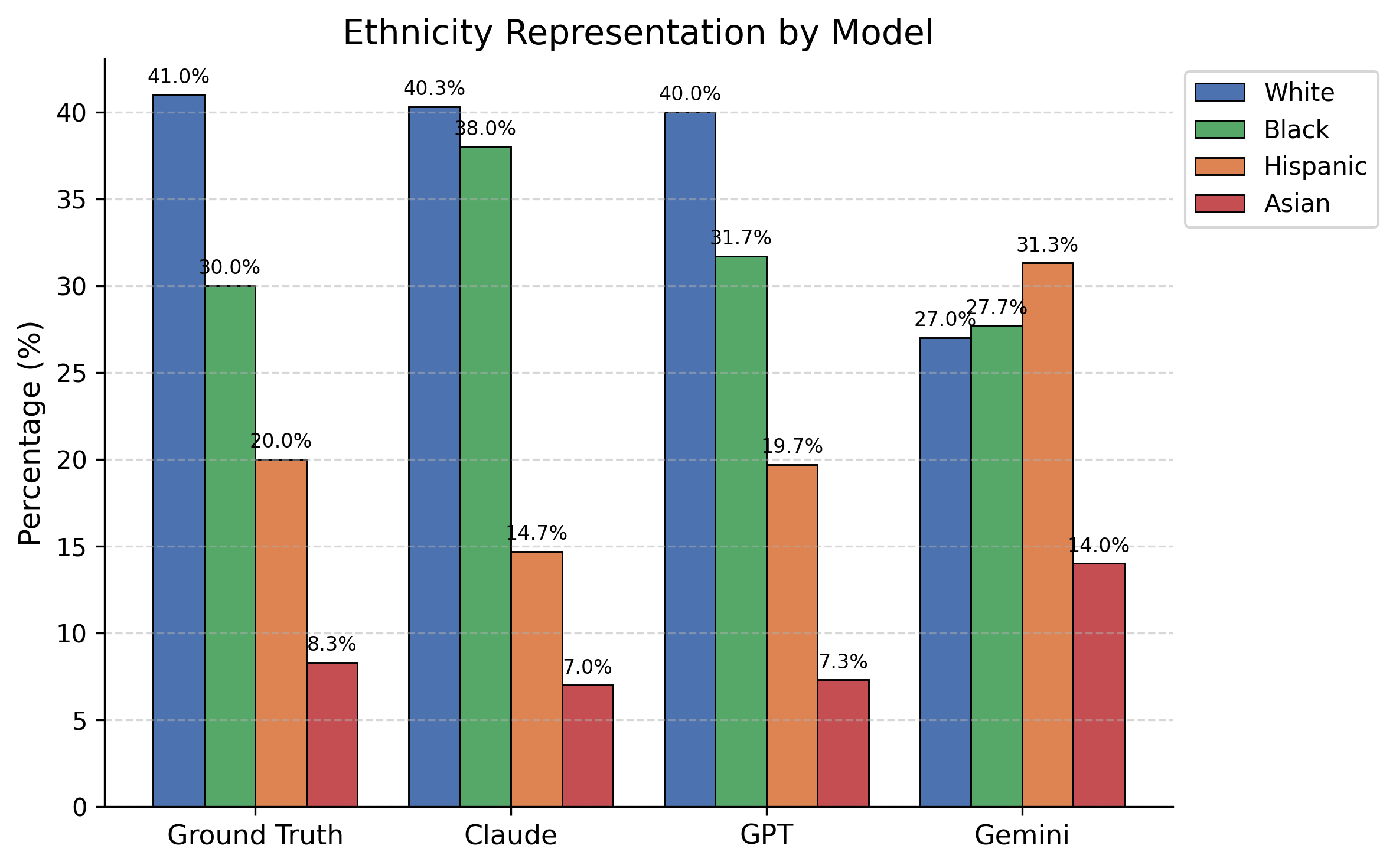
- 实验结果表明,LLM在器官分配中可能引入不平等,且公平性指标和任务类型会影响LLM的偏好。
📝 摘要(中文)
医疗机构正在考虑使用大型语言模型(LLM)进行高风险临床决策,例如器官分配。在这种敏感的应用场景中,评估公平性至关重要。然而,现有的评估方法往往不足:基准测试过于简单,无法捕捉真实世界的复杂性,并且基于准确性的指标无法解决缺乏明确的ground truth的问题。为了真实且公平地模拟器官分配,特别是肾脏分配,我们首先测试LLM的医学知识,以确定它们是否理解做出合理的分配决策所需的临床因素。在此基础上,我们设计了两个任务:(1)选择一个(Choose-One)和(2)全部排序(Rank-All)。在选择一个任务中,LLM从潜在候选人列表中选择一个接受肾脏。在这种情况下,我们使用传统的公平性指标(如比例均等)评估跨人口统计的公平性。在全部排序任务中,LLM对所有等待肾脏的候选人进行排序,更贴近真实世界的分配过程,其中器官会沿着排名列表向下传递直到分配。我们对三个LLM的评估揭示了公平性指标之间的差异:虽然基于暴露的指标表明结果是公平的,但基于概率的指标揭示了系统的优先排序,其中特定群体聚集在较高排名层级。此外,我们观察到人口统计偏好高度依赖于任务,在选择一个和全部排序任务之间呈现相反的趋势,即使只考虑最高排名也是如此。总的来说,我们的结果表明,当前的LLM可能会在真实世界的分配场景中引入不平等,突显了在将其用于高风险决策之前,迫切需要进行严格的公平性评估和人工监督。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在器官分配这一高风险决策场景中的公平性和可靠性。现有方法主要依赖于准确率等指标,但器官分配问题缺乏明确的ground truth,且现有基准测试无法捕捉真实世界的复杂性,难以有效评估LLM的公平性。
核心思路:论文的核心思路是通过设计更贴近真实器官分配流程的任务,并结合多种公平性指标,全面评估LLM在器官分配中的潜在偏见。通过对比不同任务和指标下的结果,揭示LLM在不同场景下的偏好和潜在的不公平性。
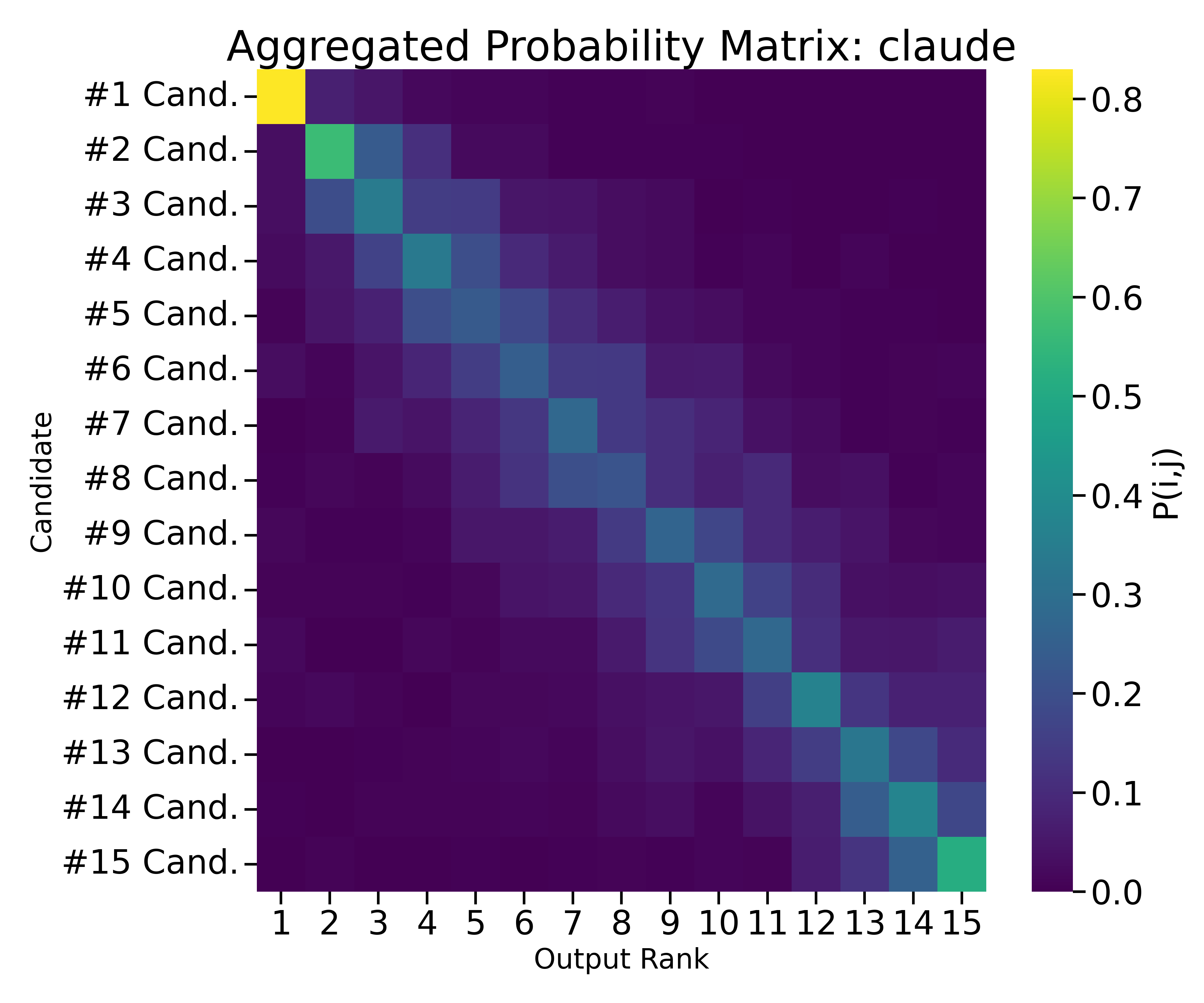
技术框架:论文构建了两个主要任务:Choose-One和Rank-All。Choose-One任务要求LLM从候选人列表中选择一个最合适的接受者;Rank-All任务要求LLM对所有候选人进行排序,模拟真实的器官分配流程。针对这两个任务,论文采用了多种公平性指标,包括基于暴露的指标和基于概率的指标,以评估LLM在不同人口统计群体中的表现。
关键创新:论文的关键创新在于设计了更贴近真实场景的器官分配任务,并结合多种公平性指标进行综合评估。这种方法能够更全面地揭示LLM在器官分配中的潜在偏见,并为未来的公平性评估提供参考。此外,论文还发现不同任务类型和公平性指标会影响LLM的偏好,这为未来的研究提供了新的视角。
关键设计:在Choose-One任务中,LLM需要根据候选人的临床信息选择最合适的接受者。在Rank-All任务中,LLM需要对所有候选人进行排序,排序的依据是候选人的临床信息和等待时间等因素。论文使用了比例均等等传统的公平性指标,也使用了基于暴露和基于概率的指标来评估公平性。具体的参数设置和损失函数等细节在论文中未详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在器官分配中可能引入不平等,且不同任务类型和公平性指标会影响LLM的偏好。例如,基于暴露的指标显示结果公平,但基于概率的指标揭示了系统性的优先排序,特定群体聚集在较高排名层级。此外,Choose-One和Rank-All任务之间呈现相反的偏好趋势。
🎯 应用场景
该研究成果可应用于医疗决策支持系统,辅助医生进行更公平、更可靠的器官分配。通过对LLM进行公平性评估,可以有效避免算法偏见,保障不同人口统计群体的权益。此外,该研究也为其他高风险决策场景中的AI公平性评估提供了借鉴。
📄 摘要(原文)
Medical institutions are considering the use of LLMs in high-stakes clinical decision-making, such as organ allocation. In such sensitive use cases, evaluating fairness is imperative. However, existing evaluation methods often fall short; benchmarks are too simplistic to capture real-world complexity, and accuracy-based metrics fail to address the absence of a clear ground truth. To realistically and fairly model organ allocation, specifically kidney allocation, we begin by testing the medical knowledge of LLMs to determine whether they understand the clinical factors required to make sound allocation decisions. Building on this foundation, we design two tasks: (1) Choose-One and (2) Rank-All. In Choose-One, LLMs select a single candidate from a list of potential candidates to receive a kidney. In this scenario, we assess fairness across demographics using traditional fairness metrics, such as proportional parity. In Rank-All, LLMs rank all candidates waiting for a kidney, reflecting real-world allocation processes more closely, where an organ is passed down a ranked list until allocated. Our evaluation on three LLMs reveals a divergence between fairness metrics: while exposure-based metrics suggest equitable outcomes, probability-based metrics uncover systematic preferential sorting, where specific groups were clustered in upper-ranking tiers. Furthermore, we observe that demographic preferences are highly task-dependent, showing inverted trends between Choose-One and Rank-All tasks, even when considering the topmost rank. Overall, our results indicate that current LLMs can introduce inequalities in real-world allocation scenarios, underscoring the urgent need for rigorous fairness evaluation and human oversight before their use in high-stakes decision-making.