Citegeist: Automated Generation of Related Work Analysis on the arXiv Corpus
作者: Claas Beger, Carl-Leander Henneking
分类: cs.LG
发布日期: 2025-03-29 (更新: 2025-12-14)
💡 一句话要点
Citegeist:提出一种基于动态RAG的arXiv论文相关工作自动生成方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 相关工作生成 检索增强生成 大型语言模型 arXiv 自然语言处理
📋 核心要点
- 现有方法难以有效利用LLM生成高质量、引用可靠的相关工作,主要挑战在于LLM的幻觉问题和缺乏领域知识。
- Citegeist通过动态RAG方法,结合嵌入相似度匹配、摘要和多阶段过滤,从arXiv语料库中检索相关论文并生成相关工作。
- 该研究发布了Citegeist网站和实现工具,方便研究人员使用,并提出了一种优化方法来整合arXiv中不断更新的论文。
📝 摘要(中文)
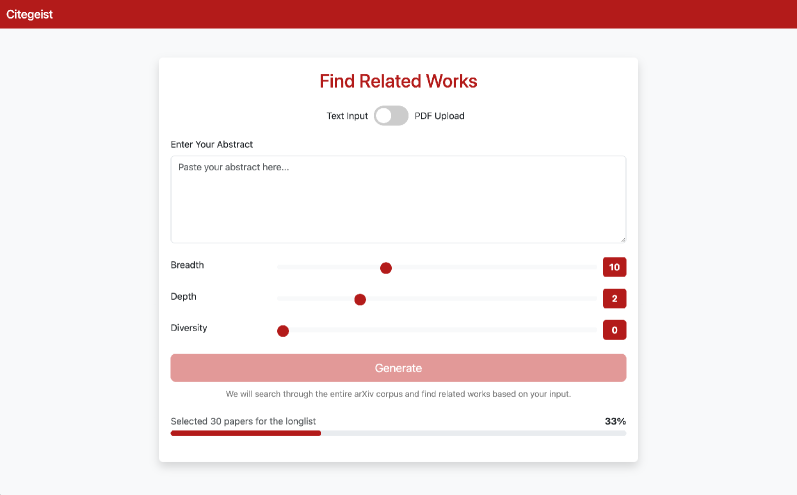
大型语言模型(LLM)为生成高质量的文本内容提供了新的机遇。然而,由于LLM容易产生无效的来源幻觉,并且缺乏对相关科学文章知识库的直接访问,它们在研究社区中的应用受到限制。本文提出了Citegeist:一个应用流水线,它利用arXiv语料库上的动态检索增强生成(RAG)来生成相关工作部分和其他引用支持的输出。为此,我们采用了一种混合方法,包括基于嵌入的相似性匹配、摘要和多阶段过滤。为了适应文档库的持续增长,我们还提出了一种优化方法来整合新的和修改过的论文。为了方便科学界使用,我们发布了一个网站(https://citegeist.org)以及一个与几种不同LLM实现配合使用的实现工具。
🔬 方法详解
问题定义:现有方法在利用大型语言模型生成相关工作时,面临两个主要痛点。一是LLM容易产生“幻觉”,即生成不存在的引用或捏造信息。二是LLM通常缺乏对特定领域(如arXiv论文)的直接访问和深入理解,难以准确找到最相关的文献。
核心思路:Citegeist的核心思路是利用检索增强生成(RAG)框架,通过外部知识库(arXiv语料库)来引导LLM的生成过程,从而减少幻觉并提高生成内容的准确性和相关性。动态RAG是指根据不同的输入和上下文,动态调整检索策略和知识融合方式。
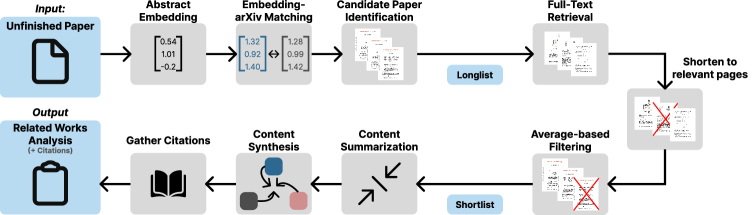
技术框架:Citegeist的整体框架包含以下几个主要模块:1) 嵌入模块:将arXiv论文转换为向量表示,用于相似度匹配。2) 检索模块:基于用户输入(例如论文标题或摘要),使用嵌入相似度匹配从arXiv语料库中检索相关论文。3) 摘要模块:对检索到的论文进行摘要,提取关键信息。4) 过滤模块:使用多阶段过滤策略,去除不相关或质量较低的论文。5) 生成模块:将检索到的相关论文摘要和用户输入一起输入到LLM中,生成相关工作部分。
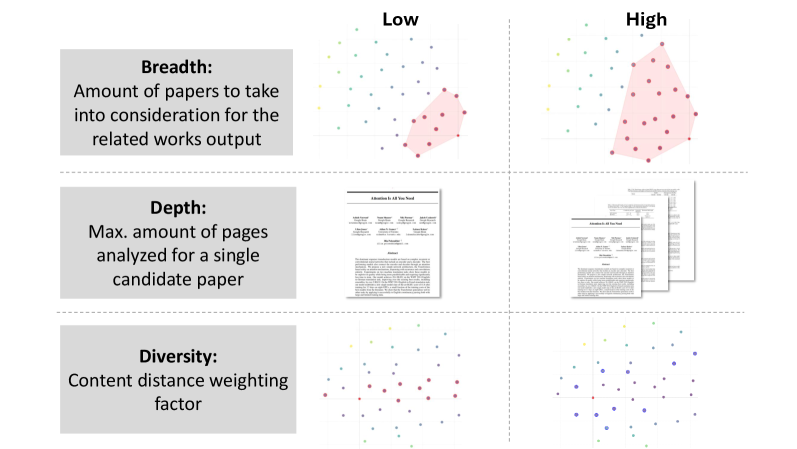
关键创新:Citegeist的关键创新在于其动态RAG策略和针对arXiv语料库的优化。传统的RAG方法通常使用静态的检索策略和知识融合方式,而Citegeist可以根据不同的输入和上下文动态调整这些策略。此外,Citegeist还提出了一种优化方法来整合arXiv中不断更新的论文,保证知识库的时效性。
关键设计:Citegeist的关键设计包括:1) 使用预训练的Transformer模型(例如BERT或Sentence-BERT)来生成论文嵌入。2) 设计多阶段过滤策略,例如基于关键词匹配、引用数量和发表时间等。3) 使用不同的LLM实现(例如GPT-3或开源LLM)进行生成,并评估其性能。4) 优化索引结构,加速检索过程。
🖼️ 关键图片
📊 实验亮点
Citegeist通过动态RAG方法,显著提高了生成相关工作的质量和准确性。虽然论文中没有给出具体的量化指标,但通过用户反馈和案例分析,表明Citegeist能够有效地减少LLM的幻觉问题,并生成更相关、更全面的相关工作内容。该工具的易用性和可扩展性也使其在科研社区具有广泛的应用前景。
🎯 应用场景
Citegeist可应用于科研论文写作、文献综述、研究项目启动等场景,帮助研究人员快速生成高质量的相关工作部分,节省时间和精力。该工具还可以用于发现新的研究方向和潜在的合作者。未来,Citegeist可以扩展到其他领域,例如专利分析、法律研究等。
📄 摘要(原文)
Large Language Models provide significant new opportunities for the generation of high-quality written works. However, their employment in the research community is inhibited by their tendency to hallucinate invalid sources and lack of direct access to a knowledge base of relevant scientific articles. In this work, we present Citegeist: An application pipeline using dynamic Retrieval Augmented Generation (RAG) on the arXiv Corpus to generate a related work section and other citation-backed outputs. For this purpose, we employ a mixture of embedding-based similarity matching, summarization, and multi-stage filtering. To adapt to the continuous growth of the document base, we also present an optimized way of incorporating new and modified papers. To enable easy utilization in the scientific community, we release both, a website (https://citegeist.org), as well as an implementation harness that works with several different LLM implementations.