Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL
作者: Mohammadreza Pourreza, Shayan Talaei, Ruoxi Sun, Xingchen Wan, Hailong Li, Azalia Mirhoseini, Amin Saberi, Sercan "O. Arik
分类: cs.LG, cs.AI, cs.DB, cs.PL
发布日期: 2025-03-29 (更新: 2025-04-01)
备注: Mohammadreza Pourreza and Shayan Talaei contributed equally to this work
💡 一句话要点
提出 Reasoning-SQL,利用定制化SQL部分奖励强化学习提升Text-to-SQL性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 强化学习 部分奖励 大型语言模型 数据库查询 推理能力 组相对策略优化
📋 核心要点
- 现有 Text-to-SQL 方法依赖手工推理路径,存在归纳偏置,限制了模型的效果和泛化能力。
- 论文提出 Reasoning-SQL,设计了模式链接、AI反馈等定制化部分奖励,解决强化学习中的奖励稀疏性问题。
- 实验结果表明,使用 Reasoning-SQL 训练的 14B 模型在 BIRD 基准上超越了更大的专有模型,验证了方法的有效性。
📝 摘要(中文)
Text-to-SQL 是一项具有挑战性的任务,涉及多个推理密集型子任务,包括自然语言理解、数据库模式理解和精确的 SQL 查询公式制定。现有方法通常依赖于具有归纳偏置的手工推理路径,这会限制它们的整体有效性。受到 DeepSeek R1 和 OpenAI o1 等推理增强模型的成功启发,这些模型有效地利用奖励驱动的自我探索来增强推理能力和泛化能力,我们提出了一组专门为 Text-to-SQL 任务量身定制的新型部分奖励。我们的奖励集包括模式链接、AI 反馈、n-gram 相似性和语法检查,这些奖励集经过明确设计,旨在解决强化学习 (RL) 中普遍存在的奖励稀疏性问题。利用组相对策略优化 (GRPO),我们的方法明确地鼓励大型语言模型 (LLM) 发展准确生成 SQL 查询所需的内在推理技能。通过不同规模的模型,我们证明了仅使用我们提出的奖励进行 RL 训练始终比监督微调 (SFT) 获得更高的准确性和卓越的泛化能力。值得注意的是,我们经过 RL 训练的 14B 参数模型在 BIRD 基准测试中显着优于更大的专有模型,例如 o3-mini 高出 4%,Gemini-1.5-Pro-002 高出 3%。这些突出了我们提出的带有部分奖励的 RL 训练框架在增强 Text-to-SQL 任务中的准确性和推理能力方面的有效性。
🔬 方法详解
问题定义:Text-to-SQL任务旨在将自然语言描述转换为可执行的SQL查询。现有方法的痛点在于依赖手工设计的推理路径,这些路径带有固有的归纳偏置,限制了模型的泛化能力和对复杂场景的适应性,同时强化学习训练中存在奖励稀疏的问题。
核心思路:论文的核心思路是通过设计一系列针对Text-to-SQL任务定制化的部分奖励,来引导大型语言模型(LLM)进行有效的自我探索和学习,从而提升其推理能力和SQL查询生成精度。这些部分奖励旨在解决强化学习中的奖励稀疏性问题,并鼓励模型学习更通用的推理策略。
技术框架:整体框架采用强化学习(RL)方法,使用大型语言模型作为策略网络。训练过程中,模型根据自然语言描述生成SQL查询,然后根据预先定义的部分奖励函数获得奖励信号。利用组相对策略优化(GRPO)算法,鼓励模型探索不同的策略,并学习更优的SQL查询生成方式。框架包含以下主要模块:自然语言编码器、SQL查询生成器、部分奖励计算模块、策略优化模块。
关键创新:最重要的技术创新点在于提出了针对Text-to-SQL任务定制化的部分奖励机制。这些奖励包括:模式链接奖励(鼓励模型正确链接自然语言中的实体与数据库模式)、AI反馈奖励(利用AI模型对生成的SQL查询进行评估并提供反馈)、n-gram相似度奖励(衡量生成SQL查询与参考查询的相似度)、语法检查奖励(确保生成的SQL查询符合语法规范)。与现有方法相比,该方法无需手工设计推理路径,而是通过奖励驱动的方式让模型自主学习推理策略。
关键设计:部分奖励的权重需要仔细调整,以平衡不同奖励之间的影响。例如,模式链接奖励的权重需要足够大,以确保模型能够正确理解数据库模式。AI反馈奖励需要选择合适的AI模型,并对其输出进行适当的过滤和处理,以避免引入噪声。GRPO算法中的组大小和学习率等参数也需要进行调整,以获得最佳的训练效果。
🖼️ 关键图片
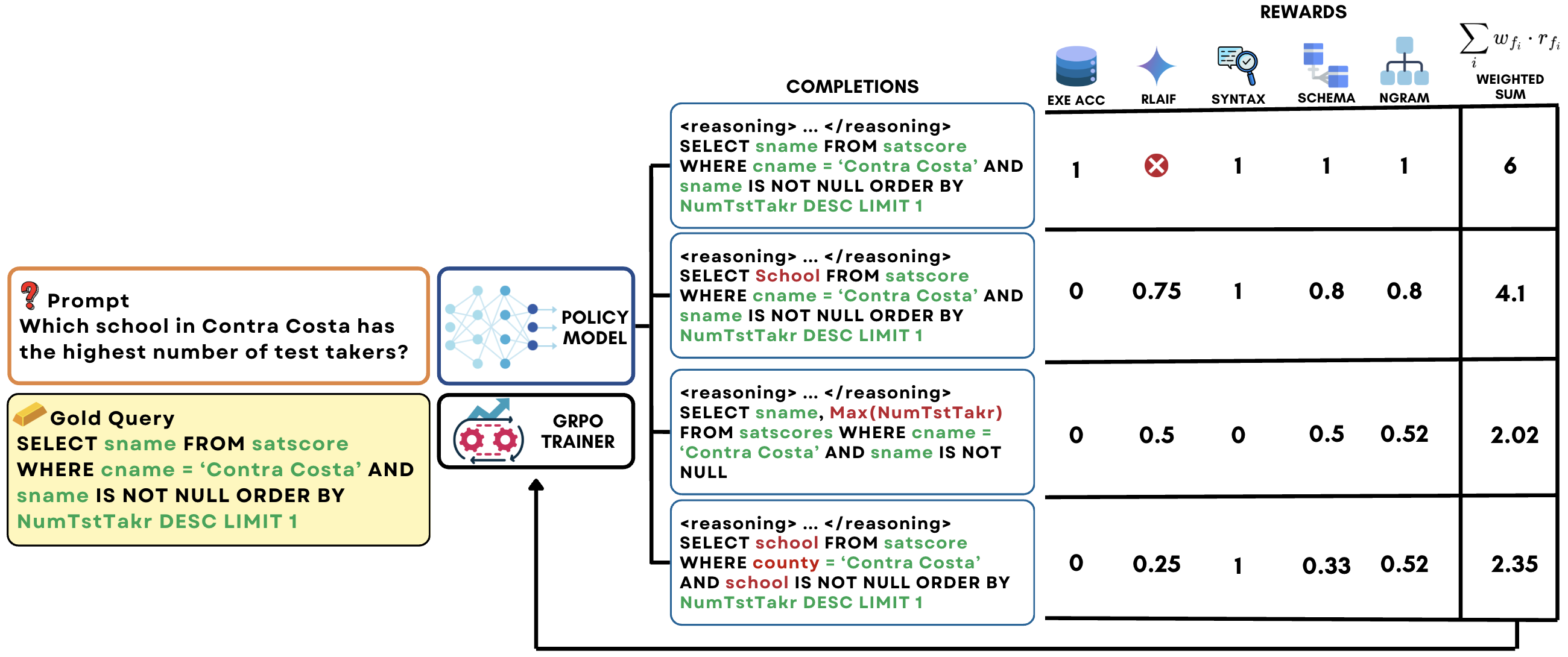
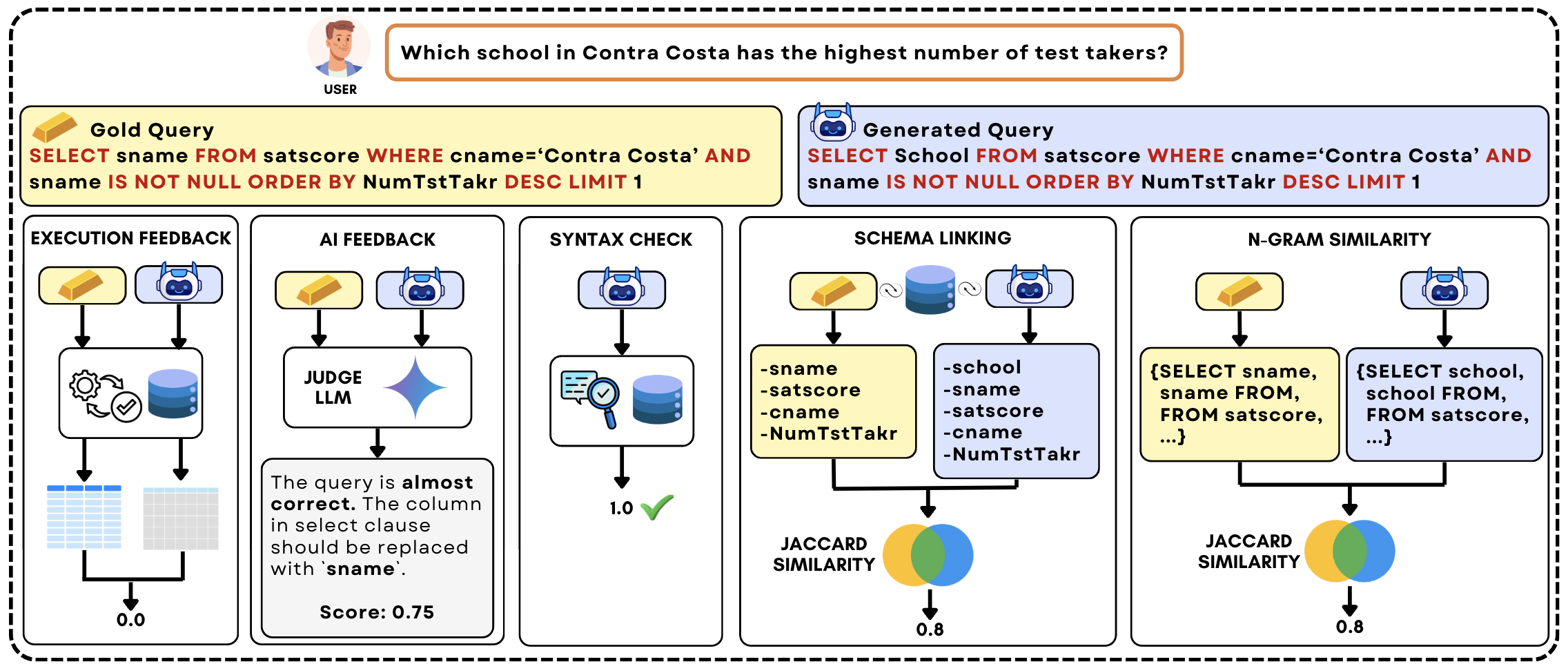

📊 实验亮点
实验结果表明,使用 Reasoning-SQL 训练的 14B 参数模型在 BIRD 基准测试中取得了显著的性能提升,超越了更大的专有模型,例如 o3-mini 高出 4%,Gemini-1.5-Pro-002 高出 3%。这表明该方法在提升 Text-to-SQL 任务的准确性和泛化能力方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于智能问答系统、数据库查询接口、数据分析平台等领域。通过将自然语言转换为SQL查询,用户可以更方便地访问和分析数据库中的数据,无需掌握复杂的SQL语法。未来,该技术有望进一步扩展到更复杂的数据库操作和数据分析任务中,提升数据处理的效率和智能化水平。
📄 摘要(原文)
Text-to-SQL is a challenging task involving multiple reasoning-intensive subtasks, including natural language understanding, database schema comprehension, and precise SQL query formulation. Existing approaches often rely on handcrafted reasoning paths with inductive biases that can limit their overall effectiveness. Motivated by the recent success of reasoning-enhanced models such as DeepSeek R1 and OpenAI o1, which effectively leverage reward-driven self-exploration to enhance reasoning capabilities and generalization, we propose a novel set of partial rewards tailored specifically for the Text-to-SQL task. Our reward set includes schema-linking, AI feedback, n-gram similarity, and syntax check, explicitly designed to address the reward sparsity issue prevalent in reinforcement learning (RL). Leveraging group relative policy optimization (GRPO), our approach explicitly encourages large language models (LLMs) to develop intrinsic reasoning skills necessary for accurate SQL query generation. With models of different sizes, we demonstrate that RL-only training with our proposed rewards consistently achieves higher accuracy and superior generalization compared to supervised fine-tuning (SFT). Remarkably, our RL-trained 14B-parameter model significantly outperforms larger proprietary models, e.g. o3-mini by 4% and Gemini-1.5-Pro-002 by 3% on the BIRD benchmark. These highlight the efficacy of our proposed RL-training framework with partial rewards for enhancing both accuracy and reasoning capabilities in Text-to-SQL tasks.