Quamba2: A Robust and Scalable Post-training Quantization Framework for Selective State Space Models
作者: Hung-Yueh Chiang, Chi-Chih Chang, Natalia Frumkin, Kai-Chiang Wu, Mohamed S. Abdelfattah, Diana Marculescu
分类: cs.LG, cs.AI, cs.CL, cs.PF
发布日期: 2025-03-28 (更新: 2025-11-06)
🔗 代码/项目: GITHUB
💡 一句话要点
Quamba2:一种稳健且可扩展的后训练量化框架,用于选择性状态空间模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 模型量化 后训练量化 低比特量化 模型压缩 Mamba 推理加速
📋 核心要点
- 现有SSM模型部署面临存储和计算挑战,尤其是在资源受限设备上,需要有效的量化方法。
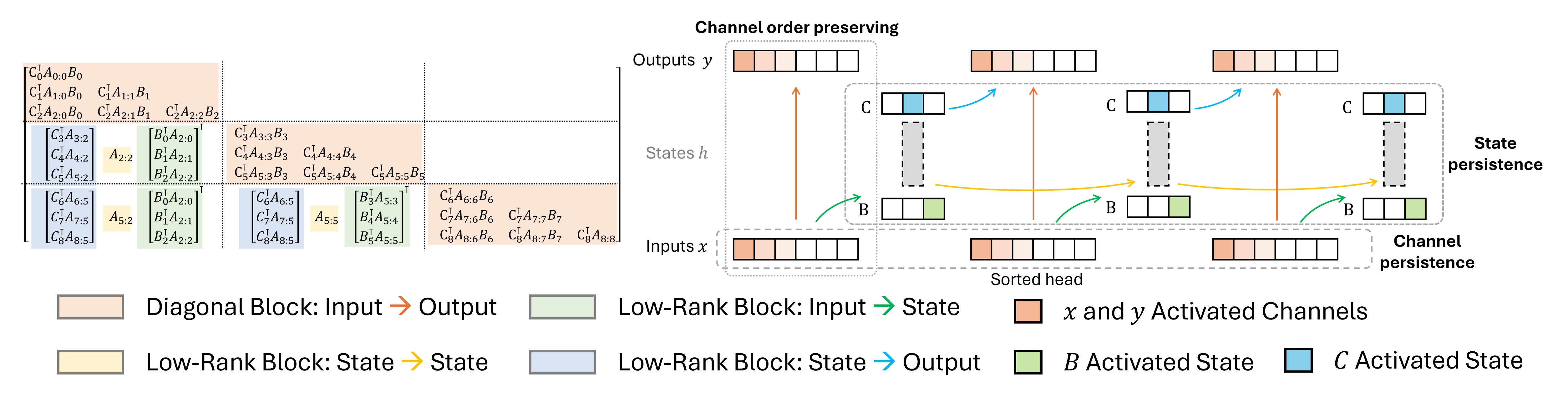
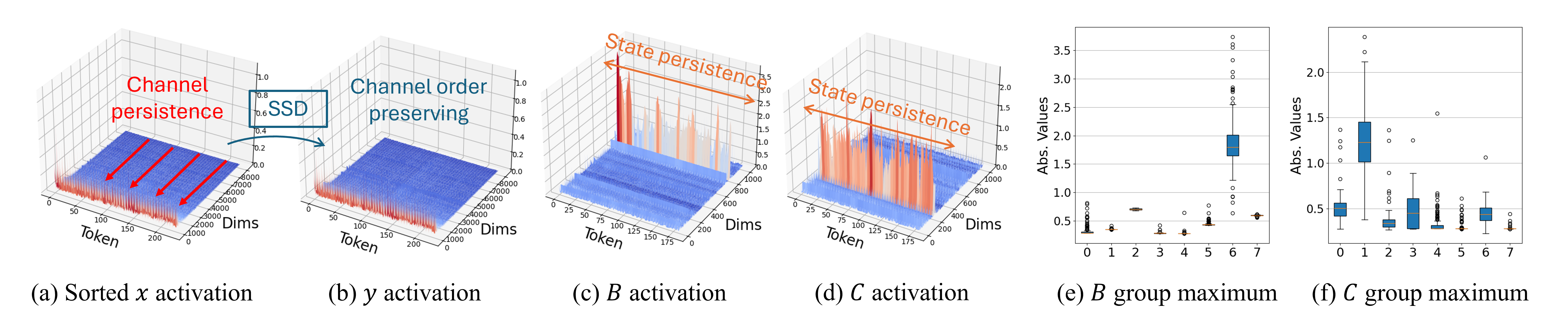
- Quamba2利用SSM的特性,通过离线排序聚类和每状态组量化,实现低比特量化并保持计算不变性。
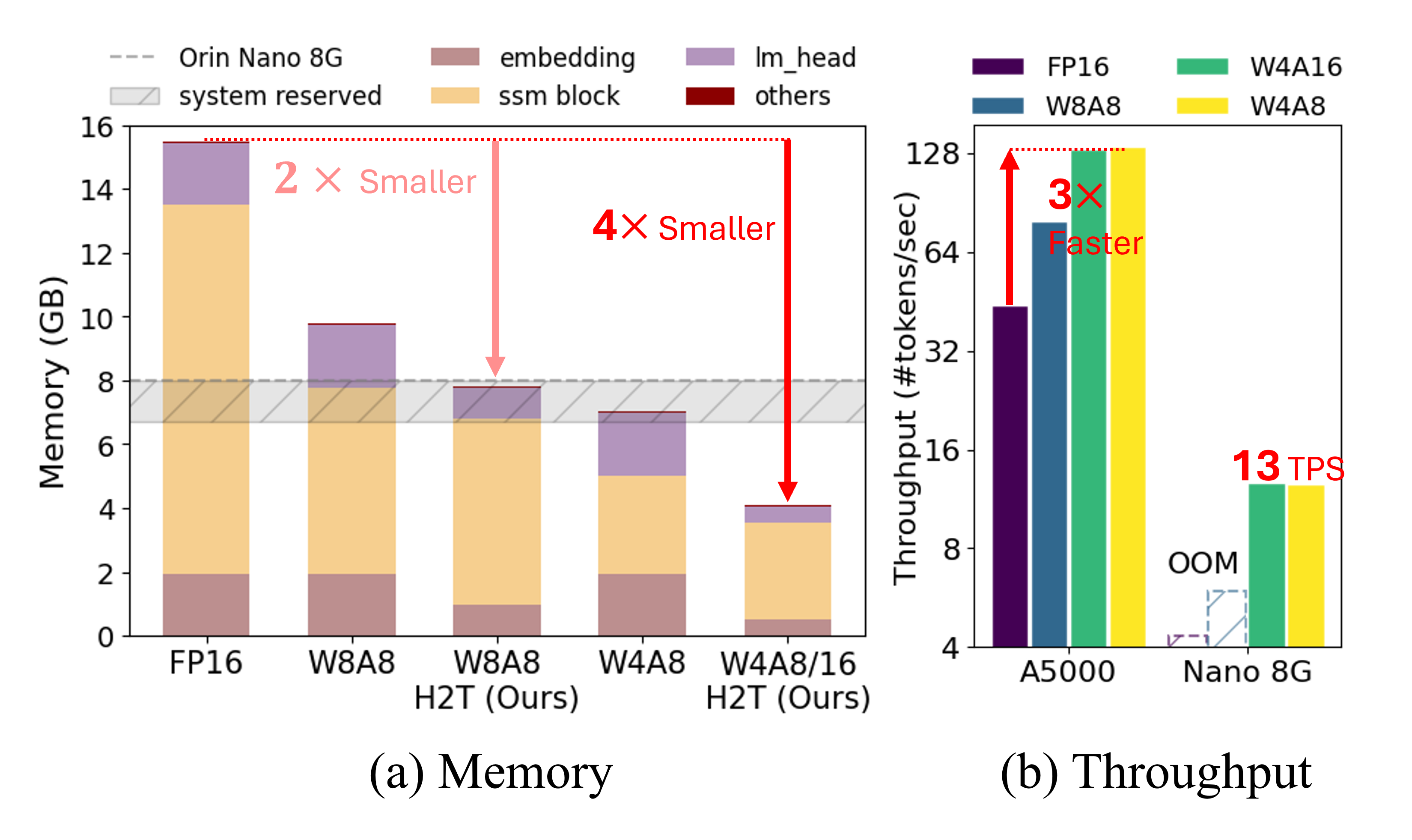
- 实验表明,Quamba2在保持精度的情况下,显著提升了SSM的推理速度和内存效率,优于现有方法。
📝 摘要(中文)
状态空间模型(SSMs)因其一致的内存使用和高性能,正成为Transformer引人注目的替代方案。然而,由于其存储需求和计算能力,在云服务或资源受限设备上扩展SSM具有挑战性。为了克服这个问题,使用低比特宽度数据格式量化SSM可以减少模型大小并受益于硬件加速。由于SSM容易出现量化引起的误差,最近的研究集中在优化特定模型或比特宽度以提高效率而不牺牲性能。然而,不同的比特宽度配置对于不同的场景至关重要,例如W4A8用于提高大批量解码速度,W4A16用于增强单个用户的短提示应用中的生成速度。为此,我们提出了Quamba2,它与Mamba1和Mamba2主干的W8A8、W4A8和W4A16兼容,满足了对在各种平台上部署SSM日益增长的需求。基于SSM的通道顺序保持和激活持久性,我们提出了一种离线方法,通过对输入x进行排序和聚类,结合对输入相关参数B和C进行每状态组量化,以8位量化线性递归的输入。为了确保SSM输出中的计算不变性,我们根据聚类序列离线重新排列权重。实验表明,Quamba2-8B优于两种最先进的SSM量化方法,并在预填充和生成阶段分别提供1.3倍和3倍的加速,同时提供4倍的内存减少,平均精度下降仅为1.6%。在MMLU上的评估表明了我们框架的通用性和鲁棒性。代码和量化模型将在https://github.com/enyac-group/Quamba发布。
🔬 方法详解
问题定义:论文旨在解决状态空间模型(SSM)在资源受限设备上部署时面临的存储和计算挑战。现有的SSM量化方法通常针对特定模型或比特宽度进行优化,缺乏通用性和灵活性,无法适应不同的应用场景需求。此外,直接量化SSM容易引入误差,导致性能下降。
核心思路:Quamba2的核心思路是利用SSM的通道顺序保持和激活持久性特性,设计一种离线量化方法,在降低模型大小和提高计算效率的同时,尽可能地保持模型的精度。通过对输入进行排序和聚类,并对输入相关参数进行每状态组量化,可以有效地减少量化误差。同时,通过离线重新排列权重,确保SSM输出的计算不变性。
技术框架:Quamba2的整体框架主要包括以下几个阶段:1) 离线分析SSM的激活分布,特别是输入x的分布;2) 对输入x进行排序和聚类,生成聚类序列;3) 对输入相关参数B和C进行每状态组量化;4) 根据聚类序列离线重新排列权重,以保持计算不变性;5) 使用量化后的模型进行推理。该框架支持W8A8、W4A8和W4A16等多种比特宽度配置,适用于不同的应用场景。
关键创新:Quamba2的关键创新在于:1) 提出了一种基于通道顺序保持和激活持久性的离线量化方法,能够有效地减少量化误差;2) 采用排序聚类和每状态组量化相结合的方式,提高了量化的灵活性和精度;3) 通过离线重新排列权重,确保了SSM输出的计算不变性,避免了量化带来的性能下降。
关键设计:Quamba2的关键设计包括:1) 使用排序和聚类来量化输入x,这允许更精细的量化,同时考虑到激活的分布;2) 对输入相关参数B和C进行每状态组量化,这允许对不同状态组使用不同的量化参数,从而提高量化精度;3) 离线权重重排,根据聚类序列调整权重顺序,以最小化量化对计算结果的影响。
🖼️ 关键图片
📊 实验亮点
Quamba2-8B在8B参数规模下,性能优于现有SSM量化方法,并在预填充阶段实现1.3倍加速,生成阶段实现3倍加速,同时模型大小减少4倍,平均精度下降仅1.6%。在MMLU数据集上的评估也验证了Quamba2的通用性和鲁棒性。
🎯 应用场景
Quamba2适用于各种需要高效部署状态空间模型的场景,例如移动设备上的自然语言处理、边缘计算环境中的实时语音识别、以及云服务中的大规模模型推理。该框架能够显著降低模型大小和提高推理速度,从而降低部署成本并提升用户体验。未来,Quamba2有望推动SSM在更多实际应用中的普及。
📄 摘要(原文)
State Space Models (SSMs) are emerging as a compelling alternative to Transformers because of their consistent memory usage and high performance. Despite this, scaling up SSMs on cloud services or limited-resource devices is challenging due to their storage requirements and computational power. To overcome this, quantizing SSMs with low bit-width data formats can reduce model size and benefit from hardware acceleration. As SSMs are prone to quantization-induced errors, recent efforts have focused on optimizing a particular model or bit-width for efficiency without sacrificing performance. However, distinct bit-width configurations are essential for different scenarios, like W4A8 for boosting large-batch decoding speed, and W4A16 for enhancing generation speed in short prompt applications for a single user. To this end, we present Quamba2, compatible with W8A8, W4A8, and W4A16 for both Mamba1 and Mamba2 backbones, addressing the growing demand for SSM deployment on various platforms. Based on the channel order preserving and activation persistence of SSMs, we propose an offline approach to quantize inputs of a linear recurrence in 8-bit by sorting and clustering for input $x$, combined with a per-state-group quantization for input-dependent parameters $B$ and $C$. To ensure compute-invariance in the SSM output, we rearrange weights offline according to the clustering sequence. The experiments show that Quamba2-8B outperforms two state-of-the-art SSM quantization methods and delivers 1.3$\times$ and 3$\times$ speed-ups in the pre-filling and generation stages, respectively, while offering 4$\times$ memory reduction with only a $1.6\%$ average accuracy drop. The evaluation on MMLU shows the generalizability and robustness of our framework. The code and quantized models will be released at: https://github.com/enyac-group/Quamba.