Invariant Control Strategies for Active Flow Control using Graph Neural Networks
作者: Marius Kurz, Rohan Kaushik, Marcel Blind, Patrick Kopper, Anna Schwarz, Felix Rodach, Andrea Beck
分类: cs.LG, physics.flu-dyn
发布日期: 2025-03-28
DOI: 10.13140/RG.2.2.35286.77125
💡 一句话要点
提出基于图神经网络的流体主动控制策略,提升泛化性并降低计算成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 图神经网络 强化学习 主动流动控制 泛化能力 流体动力学 Relexi FLEXI
📋 核心要点
- 现有基于强化学习的流动控制方法计算成本高昂,且泛化能力不足,难以适应不同的输入配置。
- 利用图神经网络处理非结构化三维流动数据,并融入旋转、反射和置换不变性,提升控制策略的泛化能力。
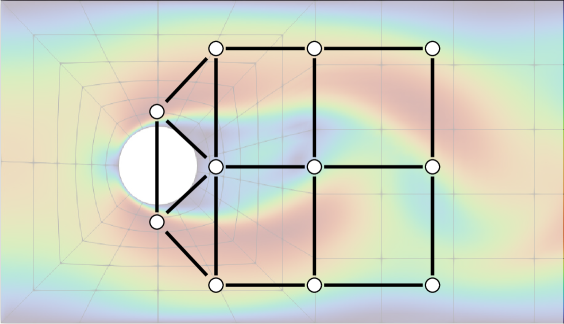
- 在二维圆柱体流动控制基准问题上,验证了基于图神经网络的控制策略的有效性,性能与现有方法相当。
📝 摘要(中文)
强化学习在主动流动控制任务中日益受到关注,最初的应用探索了通过二维圆柱体周围流场增强来减轻阻力。强化学习已被扩展到更复杂的湍流,并在学习复杂控制策略方面显示出巨大潜力。然而,由于其样本效率低下和相关的模拟成本,此类应用在计算上仍然具有挑战性。更糟糕的是,这些训练策略网络缺乏泛化能力,通常与训练条件的输入配置隐式相关。本文提出使用图神经网络来解决这一特定限制,有效地扩大适用范围,并从前期的强化学习训练成本中获得更多价值。图神经网络可以自然地处理非结构化的三维流动数据,在没有笛卡尔网格约束的情况下保持空间关系。此外,它们将旋转、反射和置换不变性融入到学习的控制策略中,从而提高泛化能力,从而消除常用卷积神经网络或多层感知机架构的缺点。为了证明这种方法的有效性,我们重新审视了用于主动流动控制的成熟的二维圆柱体基准问题。强化学习训练使用高性能强化学习框架Relexi实现,流动模拟使用高阶不连续伽辽金框架FLEXI并行进行。结果表明,基于图神经网络的控制策略实现了与现有方法相当的性能,同时受益于改进的泛化特性。这项工作确立了图神经网络作为基于强化学习的流动控制的一种有前途的架构,并突出了Relexi和FLEXI在流体动力学中大规模强化学习应用中的能力。
🔬 方法详解
问题定义:现有基于强化学习的流动控制方法,如使用卷积神经网络(CNN)或多层感知机(MLP),在处理复杂流动数据时,计算量大,且对训练数据的依赖性强,泛化能力差。当流动条件发生变化时,需要重新训练模型,成本高昂。
核心思路:利用图神经网络(GNN)处理非结构化的三维流动数据,GNN能够自然地捕捉节点之间的关系,并且通过设计可以具备旋转、反射和置换不变性,从而提高控制策略的泛化能力。这样,训练好的策略可以应用于不同的流动条件,而无需重新训练。
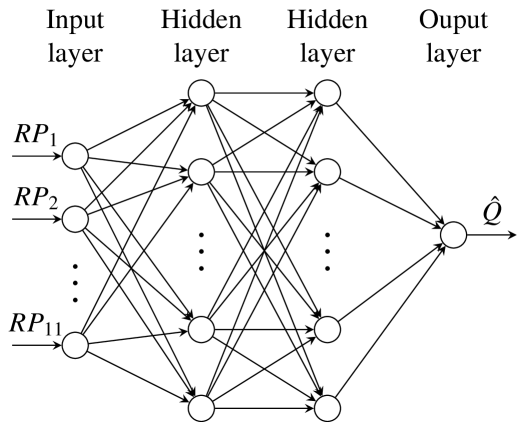
技术框架:整体流程包括:1) 使用强化学习(RL)训练基于GNN的控制策略。2) 使用Relexi框架进行RL训练,该框架具有高性能。3) 使用FLEXI框架进行并行流动模拟,该框架采用高阶不连续伽辽金方法。4) 将流动模拟数据输入GNN,GNN输出控制信号,作用于流动系统,形成闭环控制。
关键创新:最重要的创新点在于将图神经网络引入到流动控制领域,并利用其不变性特性来提高控制策略的泛化能力。与传统的CNN或MLP相比,GNN能够更好地处理非结构化的流动数据,并且能够学习到与流动条件无关的控制策略。
关键设计:GNN的网络结构需要根据具体的流动问题进行设计。关键的设计包括:1) 如何将流动数据表示为图结构,例如将流体网格节点作为图的节点,节点之间的连接关系反映流体之间的相互作用。2) 如何设计GNN的消息传递机制,使得节点能够有效地聚合邻居节点的信息。3) 如何设计损失函数,使得GNN能够学习到最优的控制策略。论文中使用了Relexi和FLEXI框架,这两个框架提供了高性能的RL训练和流动模拟能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于图神经网络的控制策略在二维圆柱体流动控制问题上,实现了与现有方法相当的性能,同时显著提高了泛化能力。这意味着训练好的策略可以应用于不同的流动条件,而无需重新训练,从而降低了计算成本。具体性能数据未知,但论文强调了泛化能力的提升。
🎯 应用场景
该研究成果可应用于各种流动控制场景,例如飞行器减阻、提高发动机效率、优化管道设计等。通过提高控制策略的泛化能力,可以降低开发成本,加速产品迭代。未来,该方法有望应用于更复杂的湍流控制问题,并与其他人工智能技术相结合,实现更智能化的流动控制。
📄 摘要(原文)
Reinforcement learning has gained traction for active flow control tasks, with initial applications exploring drag mitigation via flow field augmentation around a two-dimensional cylinder. RL has since been extended to more complex turbulent flows and has shown significant potential in learning complex control strategies. However, such applications remain computationally challenging due to its sample inefficiency and associated simulation costs. This fact is worsened by the lack of generalization capabilities of these trained policy networks, often being implicitly tied to the input configurations of their training conditions. In this work, we propose the use of graph neural networks to address this particular limitation, effectively increasing the range of applicability and getting more value out of the upfront RL training cost. GNNs can naturally process unstructured, threedimensional flow data, preserving spatial relationships without the constraints of a Cartesian grid. Additionally, they incorporate rotational, reflectional, and permutation invariance into the learned control policies, thus improving generalization and thereby removing the shortcomings of commonly used CNN or MLP architectures. To demonstrate the effectiveness of this approach, we revisit the well-established two-dimensional cylinder benchmark problem for active flow control. The RL training is implemented using Relexi, a high-performance RL framework, with flow simulations conducted in parallel using the high-order discontinuous Galerkin framework FLEXI. Our results show that GNN-based control policies achieve comparable performance to existing methods while benefiting from improved generalization properties. This work establishes GNNs as a promising architecture for RL-based flow control and highlights the capabilities of Relexi and FLEXI for large-scale RL applications in fluid dynamics.