F-INR: Functional Tensor Decomposition for Implicit Neural Representations
作者: Sai Karthikeya Vemuri, Tim Büchner, Joachim Denzler
分类: cs.LG
发布日期: 2025-03-27 (更新: 2025-11-26)
备注: Accepted at WACV 2026. Website: https://f-inr.github.io Supplementary Material can be found there. 12 pages, 6 figures, 5 tables
💡 一句话要点
提出F-INR,通过函数张量分解加速高维隐式神经表示训练并提升性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 隐式神经表示 函数张量分解 高维信号建模 图像表示 3D重建
📋 核心要点
- 单体隐式神经表示在高维数据下训练成本高昂,扩展性差,限制了其应用。
- F-INR通过函数张量分解将高维INR分解为多个低维子网络,降低计算复杂度并提升表示能力。
- 实验表明,F-INR在图像表示、3D重建和神经辐射场等任务上,显著加速训练并提升了性能。
📝 摘要(中文)
隐式神经表示(INRs)将信号建模为连续可微函数。然而,单体INRs在高维数据下扩展性差,导致训练成本过高。我们提出了F-INR,一个通过基于函数张量分解将高维INR分解为一组紧凑的、轴特定的子网络的框架,以解决这一限制。这些子网络学习低维函数组件,然后通过张量运算组合。这种分解降低了计算复杂度,同时提高了表示能力。F-INR与架构和分解方式无关。它可以与各种现有的INR骨干网络(例如,SIREN, WIRE, FINER, Factor Fields)和张量格式(例如,CP, TT, Tucker)集成,通过张量秩和模式提供对速度-精度权衡的细粒度控制。我们的实验表明,与最先进的INRs相比,F-INR加速了高达20倍的训练速度,并提高了超过6.0 dB PSNR的保真度。我们在各种任务上验证了这些增益,包括图像表示、3D几何重建和神经辐射场。我们进一步展示了F-INR通过建模复杂的物理模拟在科学计算中的适用性。因此,F-INR为高维信号建模提供了一个可扩展、灵活和高效的框架。
🔬 方法详解
问题定义:论文旨在解决高维数据下隐式神经表示(INRs)训练成本高、扩展性差的问题。现有的单体INRs在高维输入空间中需要大量的参数和计算资源,导致训练速度慢,且容易过拟合。
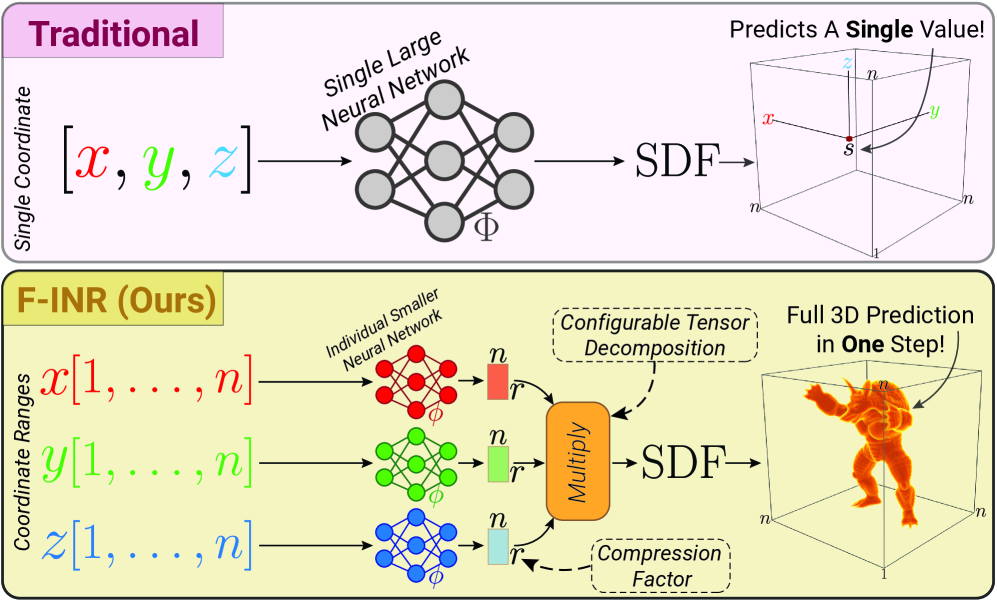
核心思路:论文的核心思路是利用函数张量分解,将一个高维的INR分解为多个低维的、轴对齐的子网络。每个子网络负责学习输入空间的一个或多个维度上的函数组件,然后通过张量运算将这些组件组合起来,从而近似原始的高维函数。这种分解降低了每个子网络的复杂度,减少了参数数量和计算量。
技术框架:F-INR的整体框架包含以下几个主要步骤:1. 输入数据被送入一组轴特定的子网络。2. 每个子网络学习对应维度上的低维函数组件。3. 通过张量分解(如CP, TT, Tucker)指定的方式,将这些低维组件组合成一个高维表示。4. 使用损失函数优化整个网络,使得输出尽可能逼近目标信号。该框架具有架构无关性,可以与多种INR骨干网络和张量分解格式集成。
关键创新:F-INR的关键创新在于将函数张量分解应用于隐式神经表示。与传统的单体INR相比,F-INR通过分解降低了计算复杂度,提高了表示能力,并且能够灵活地控制速度-精度权衡。与直接对参数进行张量分解的方法不同,F-INR是对函数本身进行分解,从而更好地利用了INR的连续表示特性。
关键设计:F-INR的关键设计包括:1. 选择合适的INR骨干网络作为子网络,例如SIREN, WIRE, FINER等。2. 选择合适的张量分解格式,例如CP, TT, Tucker等,不同的分解格式对应不同的计算复杂度和表示能力。3. 设置合适的张量秩和模式,以控制速度-精度权衡。4. 使用标准的监督学习损失函数,例如均方误差(MSE)或峰值信噪比(PSNR),来优化网络。
🖼️ 关键图片

📊 实验亮点
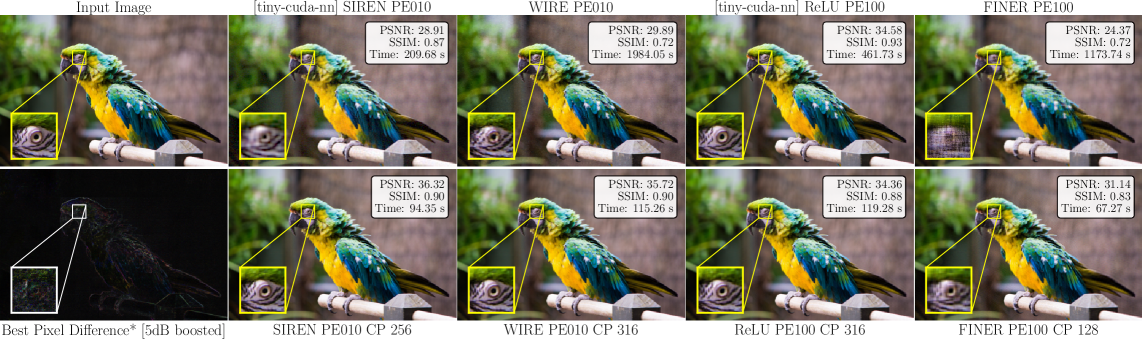
实验结果表明,F-INR在多个任务上取得了显著的性能提升。例如,在图像表示任务中,F-INR相比于最先进的INRs,训练速度提升了高达20倍,并且PSNR提高了超过6.0 dB。在3D几何重建和神经辐射场任务中,F-INR也取得了类似的性能提升。这些结果验证了F-INR在高维信号建模方面的有效性和优越性。
🎯 应用场景
F-INR具有广泛的应用前景,包括图像和视频表示、3D几何重建、神经辐射场、科学计算等领域。它可以用于加速高分辨率图像和视频的压缩和传输,提高3D模型的重建质量和效率,以及模拟复杂的物理现象。此外,F-INR还可以应用于其他高维信号建模任务,例如音频处理和时间序列分析。
📄 摘要(原文)
Implicit Neural Representations (INRs) model signals as continuous, differentiable functions. However, monolithic INRs scale poorly with data dimensionality, leading to excessive training costs. We propose F-INR, a framework that addresses this limitation by factorizing a high-dimensional INR into a set of compact, axis-specific sub-networks based on functional tensor decomposition. These sub-networks learn low-dimensional functional components that are then combined via tensor operations. This factorization reduces computational complexity while additionally improving representational capacity. F-INR is both architecture- and decomposition-agnostic. It integrates with various existing INR backbones (e.g., SIREN, WIRE, FINER, Factor Fields) and tensor formats (e.g., CP, TT, Tucker), offering fine-grained control over the speed-accuracy trade-off via the tensor rank and mode. Our experiments show F-INR accelerates training by up to $20\times$ and improves fidelity by over \num{6.0} dB PSNR compared to state-of-the-art INRs. We validate these gains on diverse tasks, including image representation, 3D geometry reconstruction, and neural radiance fields. We further show F-INR's applicability to scientific computing by modeling complex physics simulations. Thus, F-INR provides a scalable, flexible, and efficient framework for high-dimensional signal modeling. Project page: https://f-inr.github.io