Embedding Domain-Specific Knowledge from LLMs into the Feature Engineering Pipeline
作者: João Eduardo Batista
分类: cs.LG
发布日期: 2025-03-27
备注: 9 pages, 4 figures, 5 tables
💡 一句话要点
利用LLM领域知识增强特征工程流水线,加速进化计算收敛
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 特征工程 大型语言模型 进化计算 领域知识 特征构建
📋 核心要点
- 进化计算在特征工程中计算开销大,主要原因是缺乏领域知识,导致搜索效率低。
- 利用大型语言模型(LLM)的领域知识,作为特征构建的初始步骤,为进化计算提供先验信息。
- 实验表明,该方法可以加速进化计算的收敛,节省计算资源,并在部分数据集上提升模型性能。
📝 摘要(中文)
为了获得鲁棒的模型,特征工程是机器学习流水线中必不可少的环节。进化计算在特征选择和特征构建方面表现出色,但由于诱导最终模型需要大量的评估,因此计算成本很高。这些算法需要大量评估的部分原因是缺乏领域特定知识,导致进化过程中存在大量随机猜测。本文提出使用大型语言模型(LLM)作为初始特征构建步骤,为数据集添加知识。结果表明,进化可以更快地收敛,从而节省计算资源。该方法仅向LLM提供数据集中特征的名称和目标,即使处理包含私有数据的数据集也适用。虽然只有三分之一的数据集(CSS、PM 和 IM10)观察到测试性能的持续改进,可能是因为这些问题容易被 LLM 探索,但该方法仅在 1/77 个测试用例中降低了模型性能。此外,这项工作将 M6GP 特征工程算法引入符号回归,表明它可以改进随机森林回归器的结果,并产生与其前身 M3GP 具有竞争力的结果。
🔬 方法详解
问题定义:论文旨在解决特征工程中进化计算方法因缺乏领域知识而导致的计算效率低下的问题。现有方法在特征选择和构建过程中需要大量的评估,计算成本高昂,难以应用于大规模数据集或复杂问题。
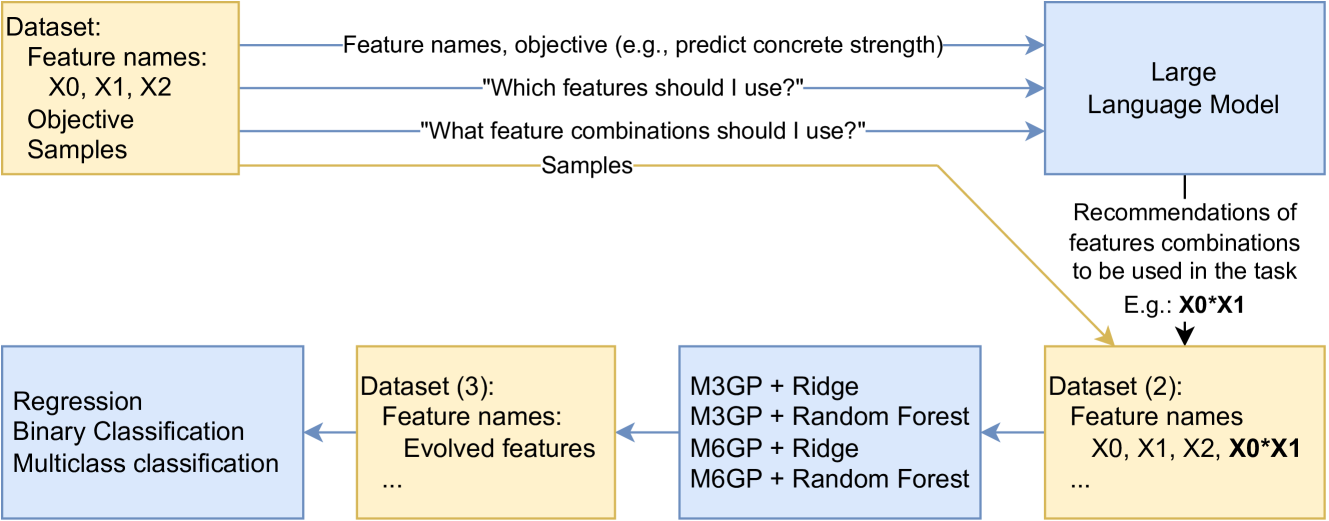
核心思路:论文的核心思路是利用大型语言模型(LLM)的领域知识,在进化计算之前进行初步的特征构建,为进化过程提供一个更优的起点。通过LLM的先验知识,减少进化过程中的随机搜索,从而加速收敛,降低计算成本。
技术框架:该方法主要包含两个阶段:1) LLM辅助的特征构建阶段:将数据集的特征名称和目标变量输入LLM,LLM根据其内部知识生成新的候选特征。2) 进化计算阶段:将LLM生成的特征与原始特征合并,然后使用进化计算算法(如M6GP)进行特征选择和构建,最终得到优化后的特征集合。
关键创新:该方法最重要的创新点在于将LLM的领域知识融入到特征工程的流水线中,利用LLM的语义理解和知识推理能力,为进化计算提供有价值的先验信息。这种方法避免了传统进化计算中的盲目搜索,提高了特征工程的效率和效果。
关键设计:该方法的关键设计在于如何有效地利用LLM的知识。论文中,作者仅向LLM提供特征名称和目标变量,避免了直接暴露原始数据,从而保护了数据的隐私。此外,作者还提出了M6GP算法,并将其应用于符号回归任务,验证了该方法的有效性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在部分数据集(CSS、PM 和 IM10)上取得了持续的测试性能提升。虽然并非所有数据集都观察到显著提升,但该方法几乎没有降低模型性能(仅在 1/77 个测试用例中)。此外,论文提出的 M6GP 算法在符号回归任务中表现出色,能够改进随机森林回归器的结果,并与 M3GP 算法具有竞争力。
🎯 应用场景
该研究成果可广泛应用于各种机器学习任务的特征工程阶段,尤其适用于领域知识丰富的场景。例如,在金融风控、医疗诊断、自然语言处理等领域,可以利用LLM的专业知识,自动构建高质量的特征,提升模型性能,降低人工特征工程的成本。该方法还有助于解决数据隐私问题,因为LLM只需要特征名称和目标,无需访问原始数据。
📄 摘要(原文)
Feature engineering is mandatory in the machine learning pipeline to obtain robust models. While evolutionary computation is well-known for its great results both in feature selection and feature construction, its methods are computationally expensive due to the large number of evaluations required to induce the final model. Part of the reason why these algorithms require a large number of evaluations is their lack of domain-specific knowledge, resulting in a lot of random guessing during evolution. In this work, we propose using Large Language Models (LLMs) as an initial feature construction step to add knowledge to the dataset. By doing so, our results show that the evolution can converge faster, saving us computational resources. The proposed approach only provides the names of the features in the dataset and the target objective to the LLM, making it usable even when working with datasets containing private data. While consistent improvements to test performance were only observed for one-third of the datasets (CSS, PM, and IM10), possibly due to problems being easily explored by LLMs, this approach only decreased the model performance in 1/77 test cases. Additionally, this work introduces the M6GP feature engineering algorithm to symbolic regression, showing it can improve the results of the random forest regressor and produce competitive results with its predecessor, M3GP.