Reasoning Beyond Limits: Advances and Open Problems for LLMs
作者: Mohamed Amine Ferrag, Norbert Tihanyi, Merouane Debbah
分类: cs.LG, cs.CL
发布日期: 2025-03-26 (更新: 2026-01-03)
备注: The paper is published ICT Express Volume 11, Issue 6, December 2025, Pages 1054-1096
DOI: 10.1016/j.icte.2025.09.003
💡 一句话要点
综述LLM推理能力进展与挑战,聚焦多语言、长文本及无监督推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 多语言模型 状态空间模型 检索增强生成
📋 核心要点
- 现有LLM在多步推理、跨语言理解和长文本处理方面仍面临挑战,尤其是在缺乏人工监督的情况下。
- 本文综述了LLM在推理能力上的最新进展,包括模型架构、训练策略和推理技巧,并分析了其核心创新。
- 论文重点关注了多语言LLM和基于状态空间模型的架构,并探讨了检索增强生成、链式思考等关键技术。
📝 摘要(中文)
生成式推理的最新突破从根本上改变了大型语言模型(LLM)处理复杂任务的方式,使其能够动态地检索、提炼并将信息组织成连贯的多步骤推理链。诸如推理时扩展、强化学习、监督微调和知识蒸馏等技术已有效地应用于最先进的模型,包括DeepSeek-R1、OpenAI o1和o3、GPT-4o、Qwen-32B以及各种Llama变体,从而显著增强了它们的推理能力。本文全面回顾了2023年至2025年间发布的27个顶级LLM,例如Mistral AI Small 3 24B、DeepSeek-R1、Search-o1、QwQ-32B和Phi-4,并分析了它们的核心创新和性能改进。此外,我们还详细概述了多语言大型语言模型(MLLM)的最新进展,重点介绍了改进跨语言推理并解决以英语为中心的训练局限性的方法。同时,我们全面回顾了基于状态空间模型(SSM)的架构的进展,包括Mamba等模型,与基于Transformer的方法相比,这些模型在长上下文处理方面表现出更高的效率。我们的分析涵盖了训练策略,包括通用优化技术、混合专家(MoE)配置、检索增强生成(RAG)、链式思考提示、自我改进方法以及测试时计算缩放和知识蒸馏框架。最后,我们确定了未来研究的关键挑战,包括在无人为监督的情况下实现多步骤推理,提高链式任务执行的鲁棒性,平衡结构化提示与生成灵活性,以及加强长上下文检索和外部工具的集成。
🔬 方法详解
问题定义:现有的大型语言模型在复杂推理任务中,尤其是在多步骤推理、跨语言推理和长文本处理方面,仍然面临诸多挑战。现有的方法往往依赖于大量的人工标注数据和监督信号,限制了其泛化能力和在低资源场景下的应用。此外,现有模型在处理长上下文时,计算效率较低,并且容易出现信息丢失或注意力分散的问题。
核心思路:本文的核心思路是对现有LLM的推理能力进行全面的综述和分析,重点关注模型架构、训练策略和推理技巧等关键方面。通过对不同模型的性能和特点进行比较,揭示了LLM在推理能力上的优势和不足,并为未来的研究方向提供了指导。此外,本文还关注了多语言LLM和基于状态空间模型的架构,旨在探索更高效、更通用的推理方法。
技术框架:本文采用了一种系统性的综述方法,首先对2023年至2025年间发布的27个顶级LLM进行了全面的回顾,包括Mistral AI Small 3 24B、DeepSeek-R1、Search-o1、QwQ-32B和Phi-4等。然后,对多语言LLM和基于状态空间模型的架构进行了详细的概述,并分析了它们在跨语言推理和长上下文处理方面的优势。最后,对各种训练策略和推理技巧进行了总结,包括通用优化技术、混合专家(MoE)配置、检索增强生成(RAG)、链式思考提示等。
关键创新:本文的创新之处在于对LLM推理能力的全面综述和分析,涵盖了模型架构、训练策略和推理技巧等多个方面。此外,本文还关注了多语言LLM和基于状态空间模型的架构,并探讨了它们在跨语言推理和长上下文处理方面的潜力。通过对不同模型的性能和特点进行比较,揭示了LLM在推理能力上的优势和不足,并为未来的研究方向提供了指导。
关键设计:本文主要关注现有模型的架构和训练方法,并未提出新的模型或算法。然而,本文对各种训练策略和推理技巧进行了详细的总结,包括通用优化技术、混合专家(MoE)配置、检索增强生成(RAG)、链式思考提示等。这些技术细节对于提高LLM的推理能力至关重要。
🖼️ 关键图片


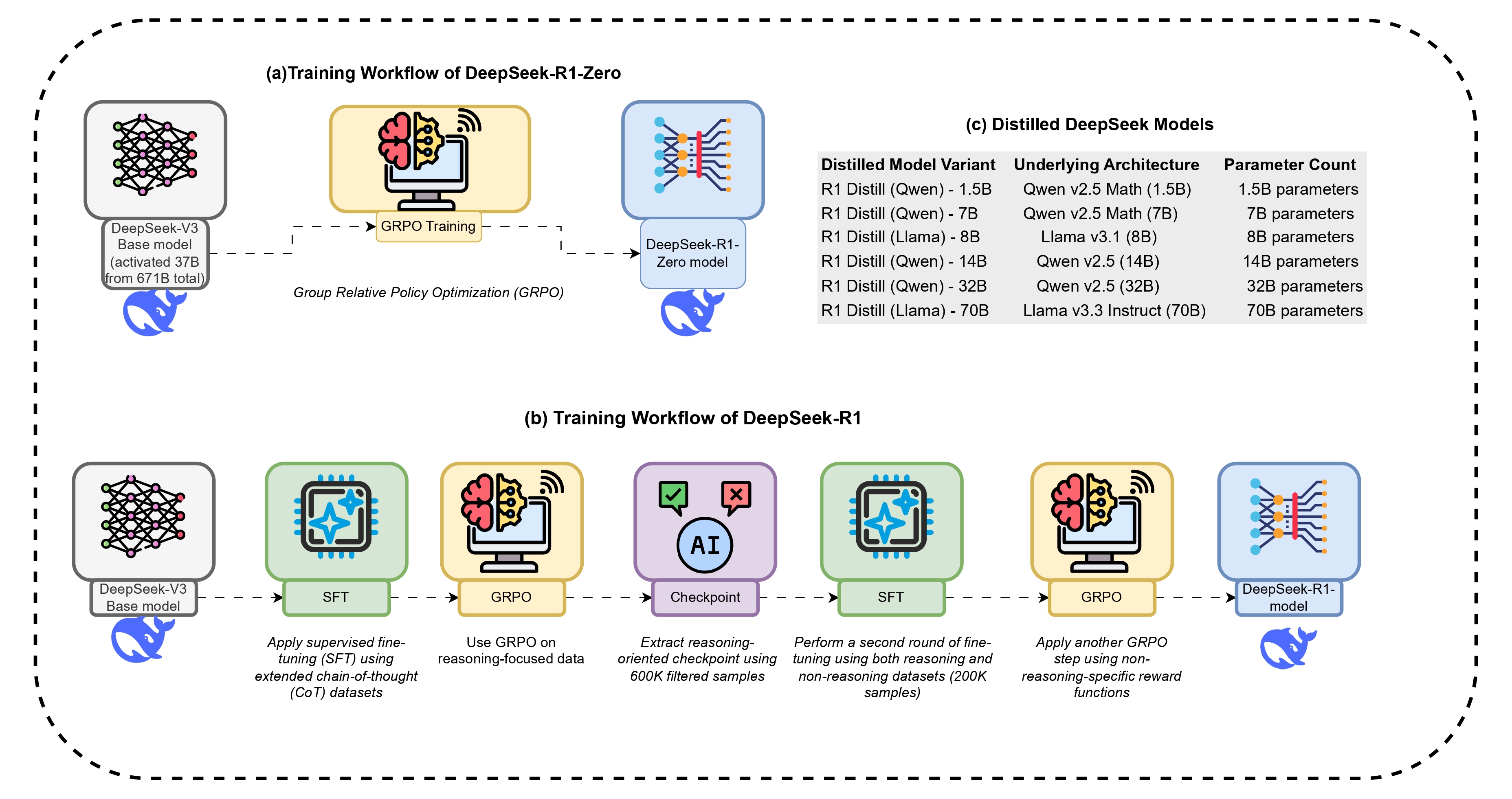
📊 实验亮点
论文分析了27个顶级LLM,并总结了多语言LLM和基于状态空间模型的架构的最新进展。强调了检索增强生成(RAG)、链式思考提示等技术在提升推理能力方面的作用。指出了未来研究的关键挑战,包括无监督多步推理、鲁棒性提升和长上下文集成。
🎯 应用场景
该研究成果可应用于智能问答、机器翻译、文本摘要、代码生成等多个领域。通过提升LLM的推理能力,可以更好地理解用户意图,生成更准确、更流畅的文本,并解决更复杂的实际问题。未来的研究方向包括开发更高效的推理算法、增强模型的鲁棒性和泛化能力,以及实现更智能的人机交互。
📄 摘要(原文)
Recent breakthroughs in generative reasoning have fundamentally reshaped how large language models (LLMs) address complex tasks, enabling them to dynamically retrieve, refine, and organize information into coherent multi-step reasoning chains. Techniques such as inference-time scaling, reinforcement learning, supervised fine-tuning, and distillation have been effectively applied to state-of-the-art models, including DeepSeek-R1, OpenAI o1 and o3, GPT-4o, Qwen-32B, and various Llama variants, significantly enhancing their reasoning capabilities. In this paper, we present a comprehensive review of the top 27 LLMs released between 2023 and 2025, such as Mistral AI Small 3 24B, DeepSeek-R1, Search-o1, QwQ-32B, and Phi-4, and analyze their core innovations and performance improvements. We also provide a detailed overview of recent advancements in multilingual large language models (MLLMs), emphasizing methods that improve cross-lingual reasoning and address the limitations of English-centric training. In parallel, we present a comprehensive review of progress in state space model (SSM)-based architectures, including models such as Mamba, which demonstrate improved efficiency for long-context processing compared to transformer-based approaches. Our analysis covers training strategies including general optimization techniques, mixture-of-experts (MoE) configurations, retrieval-augmented generation (RAG), chain-of-thought prompting, self-improvement methods, and test-time compute scaling and distillation frameworks. Finally, we identify key challenges for future research, including enabling multi-step reasoning without human supervision, improving robustness in chained task execution, balancing structured prompting with generative flexibility, and enhancing the integration of long-context retrieval and external tools.