Zero-Shot LLMs in Human-in-the-Loop RL: Replacing Human Feedback for Reward Shaping
作者: Mohammad Saif Nazir, Chayan Banerjee
分类: cs.LG, cs.AI
发布日期: 2025-03-26 (更新: 2025-09-18)
备注: 20 pages, 3 figures, 4 Tables
💡 一句话要点
提出LLM-HFBF框架,利用零样本LLM进行强化学习奖励塑造,并纠正人类反馈偏差。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 奖励塑造 人机协同 大型语言模型 偏差纠正
📋 核心要点
- 强化学习中奖励函数与真实目标不一致导致性能下降,人机协同方法引入了人类反馈偏差。
- 利用零样本LLM直接提供奖励塑造反馈,无需训练易受偏差影响的替代模型。
- 提出LLM-HFBF框架,结合LLM和人类反馈,纠正偏差,提升强化学习性能。
📝 摘要(中文)
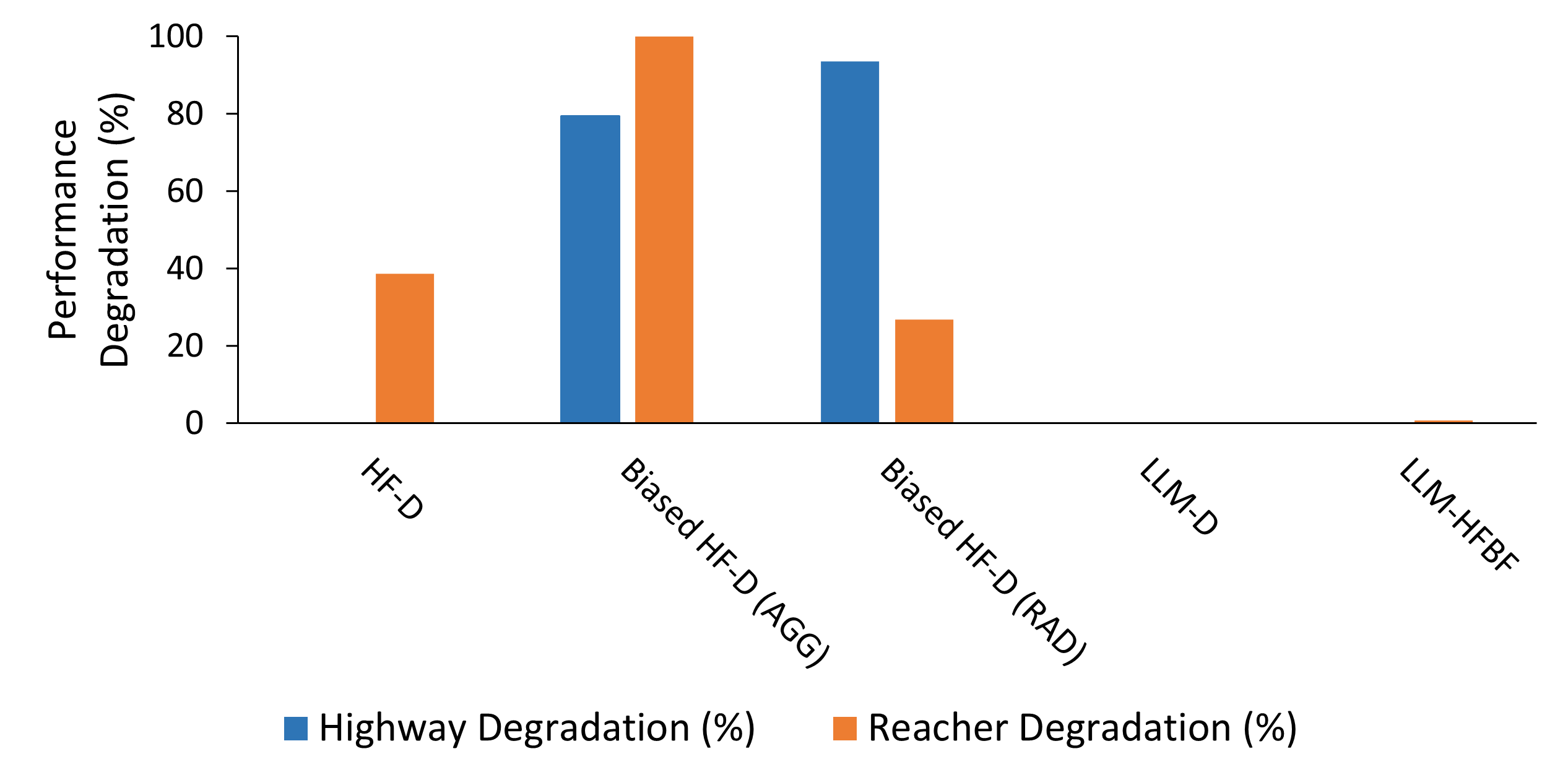
强化学习常面临奖励不一致问题,智能体优化了给定的奖励,但未能表现出期望的行为。当奖励函数激励与真实目标不一致的代理行为时,就会出现这种情况。人机协同(HITL)方法可以缓解这个问题,但也会引入偏差,导致不一致和主观的反馈,从而使学习复杂化。为了解决这些挑战,我们提出了两个关键贡献。首先,我们将零样本、现成的LLM用于奖励塑造,从自然语言处理(NLP)扩展到连续控制任务。使用LLM作为直接反馈提供者,消除了对在人类反馈上训练的替代模型的需求,这些模型通常会继承训练数据的偏差。其次,我们引入了一个混合框架(LLM-HFBF),使LLM能够识别和纠正人类反馈中的偏差,同时将这种反馈纳入奖励塑造过程。LLM-HFBF框架通过解决LLM的局限性(例如,缺乏领域特定知识)和人类监督的局限性(例如,固有的偏差),创建了一个更平衡和可靠的系统。通过启用人类反馈偏差标记和纠正,我们的方法提高了强化学习性能,并减少了对可能存在偏差的人类反馈的依赖。实验表明,有偏差的人类反馈会显著降低性能,平均情节奖励与无偏差方法相比下降了近94%。相比之下,即使在具有挑战性的极端情况下,基于LLM的方法也能将性能维持在与无偏差反馈相似的水平。
🔬 方法详解
问题定义:强化学习中的奖励塑造面临奖励函数与真实目标不一致的问题,导致智能体学习到非期望行为。现有的人机协同方法虽然可以提供指导,但人类反馈本身存在偏差,例如主观性、不一致性等,这些偏差会影响强化学习的性能。
核心思路:利用大型语言模型(LLM)的强大泛化能力和对人类意图的理解,直接作为奖励塑造的反馈提供者,避免了训练代理模型带来的偏差传递。同时,设计一个混合框架,让LLM能够识别并纠正人类反馈中的偏差,从而结合两者的优势。
技术框架:LLM-HFBF框架包含以下几个主要模块:1) 智能体与环境交互,产生状态和动作序列;2) LLM根据状态和动作序列生成奖励信号,用于指导智能体学习;3) 人类专家提供反馈,LLM评估人类反馈的质量,标记潜在的偏差;4) 根据LLM的评估结果,对人类反馈进行修正或加权,最终生成用于奖励塑造的信号。
关键创新:该论文的关键创新在于将零样本LLM应用于连续控制任务的奖励塑造,并设计了一个混合框架来纠正人类反馈中的偏差。与传统的基于人类反馈训练代理模型的方法相比,该方法避免了偏差传递,提高了奖励塑造的准确性和可靠性。
关键设计:LLM的prompt设计至关重要,需要清晰地描述任务目标和期望行为,以便LLM能够生成合适的奖励信号。人类反馈偏差的评估和纠正机制需要仔细设计,以平衡LLM的判断和人类专家的知识。具体的参数设置和损失函数未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,有偏差的人类反馈会导致强化学习性能显著下降,平均情节奖励下降近94%。而基于LLM的方法即使在具有挑战性的场景下,也能保持与无偏差反馈相似的性能水平。这表明LLM在奖励塑造方面具有潜力,并且LLM-HFBF框架能够有效纠正人类反馈中的偏差。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域,通过结合LLM的理解能力和人类专家的知识,可以更有效地进行奖励塑造,引导智能体学习到期望的行为。该方法降低了对大量高质量人类反馈的依赖,有望加速强化学习在实际场景中的应用。
📄 摘要(原文)
Reinforcement learning (RL) often struggles with reward misalignment, where agents optimize given rewards but fail to exhibit the desired behaviors. This arises when the reward function incentivizes proxy behaviors misaligned with the true objective. While human-in-the-loop (HITL) methods can mitigate this issue, they also introduce biases, leading to inconsistent and subjective feedback that complicates learning. To address these challenges, we propose two key contributions. First, we extend the use of zero-shot, off-the-shelf large language models (LLMs) for reward shaping beyond natural language processing (NLP) to continuous control tasks. Using LLMs as direct feedback providers eliminates the need for surrogate models trained on human feedback, which often inherit biases from training data. Second, we introduce a hybrid framework (LLM-HFBF) that enables LLMs to identify and correct biases in human feedback while incorporating this feedback into the reward shaping process. The LLM-HFBF framework creates a more balanced and reliable system by addressing both the limitations of LLMs (e.g., lack of domain-specific knowledge) and human supervision (e.g., inherent biases). By enabling human feedback bias flagging and correction, our approach improves reinforcement learning performance and reduces reliance on potentially biased human feedback. Empirical experiments show that biased human feedback significantly reduces performance, with Average Episodic Reward dropping by nearly 94% compared to unbiased approaches. In contrast, LLM-based methods sustain performance at a similar level to unbiased feedback, even in challenging edge-case scenarios.