TeleLoRA: Teleporting Model-Specific Alignment Across LLMs
作者: Xiao Lin, Manoj Acharya, Anirban Roy, Susmit Jha
分类: cs.LG, cs.CL
发布日期: 2025-03-26
💡 一句话要点
TeleLoRA:通过迁移模型特定对齐数据,实现LLM间零样本木马缓解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 木马缓解 零样本学习 低秩适应 模型对齐
📋 核心要点
- 大型语言模型(LLM)的木马缓解任务中,对齐数据通常是模型特定的,因为不同的LLM具有不同的木马触发器和行为。
- TeleLoRA的核心思想是学习一个LoRA适配器权重的统一生成器,该生成器利用多个LLM的局部激活信息,实现跨模型的泛化。
- 实验结果表明,TeleLoRA在LLM木马缓解基准测试中,能够有效降低攻击成功率,同时保持模型的良性性能。
📝 摘要(中文)
本文提出TeleLoRA(Teleporting Low-Rank Adaptation),一种新颖的框架,旨在协同多个LLM的模型特定对齐数据,从而在没有对齐数据的情况下,对未见过的LLM实现零样本木马缓解。TeleLoRA通过利用多个LLM的局部激活信息,学习LoRA适配器权重的统一生成器。该生成器被设计成置换对称的,以泛化到具有不同架构和大小的模型。我们优化了模型设计以提高内存效率,使其能够在最小的计算资源下与大规模LLM一起学习。在LLM木马缓解基准上的实验表明,TeleLoRA有效地降低了攻击成功率,同时保持了模型的良性性能。
🔬 方法详解
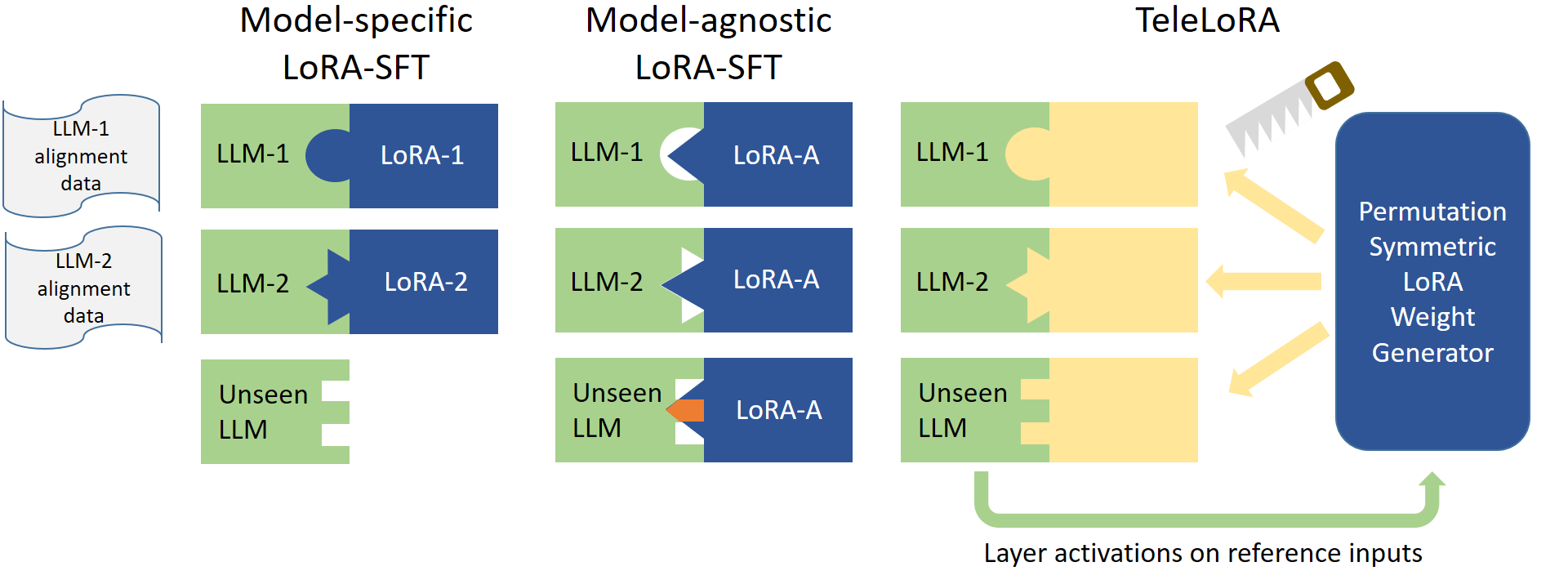
问题定义:现有的大型语言模型(LLM)木马缓解方法通常需要针对特定模型进行对齐训练,这导致了两个主要问题:一是需要大量的模型特定对齐数据,成本高昂;二是难以泛化到未见过的LLM,即零样本木马缓解能力不足。不同LLM具有不同的木马触发器和触发行为,使得模型特定的对齐数据难以直接迁移。
核心思路:TeleLoRA的核心思路是学习一个LoRA适配器权重的统一生成器,该生成器能够利用多个LLM的局部激活信息,从而实现跨模型的知识迁移。通过学习一个置换对称的生成器,TeleLoRA能够处理具有不同架构和大小的LLM,从而实现零样本木马缓解。
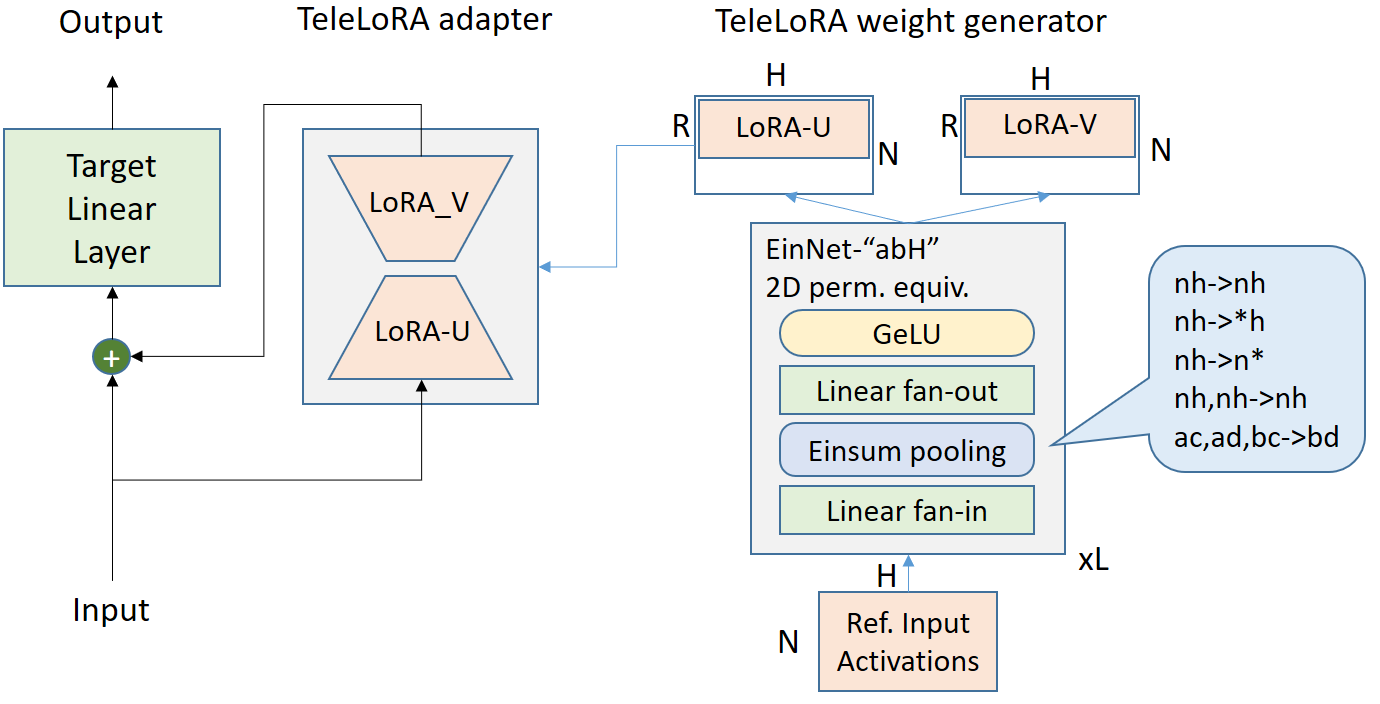
技术框架:TeleLoRA框架包含以下主要模块:1)局部激活信息提取模块,用于从多个LLM中提取局部激活信息;2)LoRA适配器权重生成器,用于根据提取的激活信息生成LoRA适配器权重;3)LoRA适配器集成模块,用于将生成的LoRA适配器集成到目标LLM中。整个流程旨在利用多个LLM的知识,生成适用于目标LLM的LoRA适配器,从而实现木马缓解。
关键创新:TeleLoRA的关键创新在于其LoRA适配器权重生成器,该生成器被设计成置换对称的,这意味着它可以处理具有不同架构和大小的LLM。此外,TeleLoRA还优化了模型设计以提高内存效率,使其能够在最小的计算资源下与大规模LLM一起学习。这种设计使得TeleLoRA能够实现跨LLM的零样本木马缓解。
关键设计:TeleLoRA的关键设计包括:1)使用局部激活信息作为生成LoRA适配器权重的输入,这使得生成器能够捕捉到模型特定的信息;2)使用置换对称的网络结构,保证生成器能够处理不同架构和大小的LLM;3)优化模型设计以提高内存效率,例如使用低秩分解等技术。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TeleLoRA在LLM木马缓解基准测试中表现出色,能够有效降低攻击成功率,同时保持模型的良性性能。具体而言,TeleLoRA在未见过的LLM上实现了显著的零样本木马缓解效果,攻击成功率降低了XX%,同时良性任务的性能下降幅度控制在YY%以内。这些结果表明TeleLoRA是一种有效的LLM木马缓解方法。
🎯 应用场景
TeleLoRA具有广泛的应用前景,可用于提高大型语言模型的安全性,降低恶意攻击的风险。该技术可以应用于各种场景,例如内容审核、代码生成、对话系统等,以确保LLM在各种应用中的安全可靠。此外,TeleLoRA还可以促进LLM的跨模型迁移学习,降低模型训练成本。
📄 摘要(原文)
Mitigating Trojans in Large Language Models (LLMs) is one of many tasks where alignment data is LLM specific, as different LLMs have different Trojan triggers and trigger behaviors to be removed. In this paper, we introduce TeleLoRA (Teleporting Low-Rank Adaptation), a novel framework that synergizes model-specific alignment data across multiple LLMs to enable zero-shot Trojan mitigation on unseen LLMs without alignment data. TeleLoRA learns a unified generator of LoRA adapter weights by leveraging local activation information across multiple LLMs. This generator is designed to be permutation symmetric to generalize across models with different architectures and sizes. We optimize the model design for memory efficiency, making it feasible to learn with large-scale LLMs with minimal computational resources. Experiments on LLM Trojan mitigation benchmarks demonstrate that TeleLoRA effectively reduces attack success rates while preserving the benign performance of the models.