Maya: Optimizing Deep Learning Training Workloads using GPU Runtime Emulation
作者: Srihas Yarlagadda, Amey Agrawal, Elton Pinto, Hakesh Darapaneni, Mitali Meratwal, Shivam Mittal, Pranavi Bajjuri, Srinivas Sridharan, Alexey Tumanov
分类: cs.LG, cs.DC
发布日期: 2025-03-26 (更新: 2025-11-15)
期刊: European Conference on Computer Systems (EuroSys) 2026, Edinburgh, Scotland Uk
💡 一句话要点
Maya:利用GPU运行时模拟优化深度学习训练工作负载
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度学习训练 性能建模 GPU模拟 运行时优化 模型优化
📋 核心要点
- 现有训练优化方法依赖手动试错,成本高昂且易出错,缺乏高效的自动化探索手段。
- Maya通过透明的设备运行时模拟,在框架和硬件间捕获完整工作负载行为,无需修改代码。
- 实验表明,Maya预测误差小于5%,能有效降低训练成本,最高可达56%。
📝 摘要(中文)
训练大型基础模型耗资巨大,优化部署至关重要。目前的方法依赖机器学习工程师在昂贵的计算集群上通过易错的试错法手动设计训练方案。为了高效探索训练配置,研究人员开发了性能建模系统。然而,这些系统迫使用户将工作负载转换为自定义规范语言,在实际工作负载及其表示之间造成了根本的语义鸿沟。这种差距导致固有的权衡:系统要么必须支持狭窄的工作负载范围以保持可用性,要么需要复杂的规范限制实际应用,要么通过简化的性能模型牺牲预测准确性。我们提出了Maya,一种通过透明设备模拟消除这些权衡的性能建模系统。通过在训练框架和加速器设备之间的狭窄接口上运行,Maya无需代码修改或转换即可捕获完整的工作负载行为。Maya拦截来自未修改训练代码的设备API调用,以直接观察底层操作,从而在保持易用性和通用性的同时实现准确的性能预测。我们的评估表明,Maya在不同的模型和优化策略中实现了小于5%的预测误差,与现有方法相比,识别出的配置可将训练成本降低高达56%。
🔬 方法详解
问题定义:论文旨在解决深度学习模型训练过程中,由于缺乏有效的性能建模工具,导致训练配置探索效率低下、成本高昂的问题。现有方法主要依赖人工试错或需要用户将工作负载转换为自定义规范语言,存在语义鸿沟,难以准确预测实际训练性能,且通用性不足。
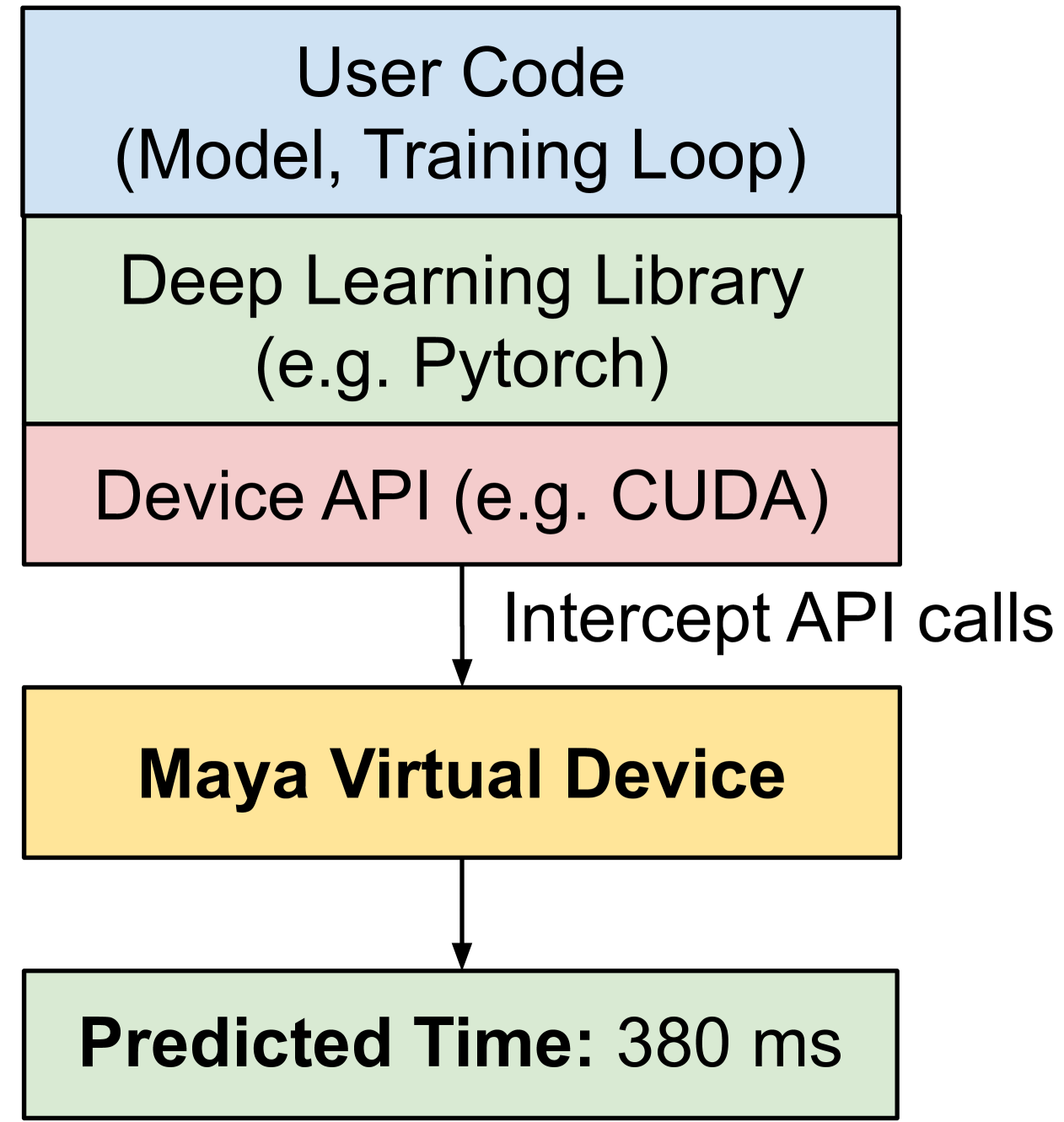
核心思路:Maya的核心思路是采用透明的设备运行时模拟技术,在训练框架和加速器设备之间建立一个桥梁,无需修改训练代码即可捕获完整的工作负载行为。通过拦截设备API调用,Maya能够直接观察底层操作,从而实现准确的性能预测。
技术框架:Maya的整体架构包含以下几个主要模块:1) 训练框架接口:负责与现有的深度学习训练框架(如TensorFlow、PyTorch)进行交互,拦截设备API调用。2) 设备运行时模拟器:模拟GPU等加速器设备的运行时行为,包括计算、内存访问、通信等。3) 性能建模器:基于模拟的运行时信息,建立性能模型,预测不同训练配置下的训练时间和成本。4) 优化器:根据性能模型的预测结果,自动搜索最优的训练配置。
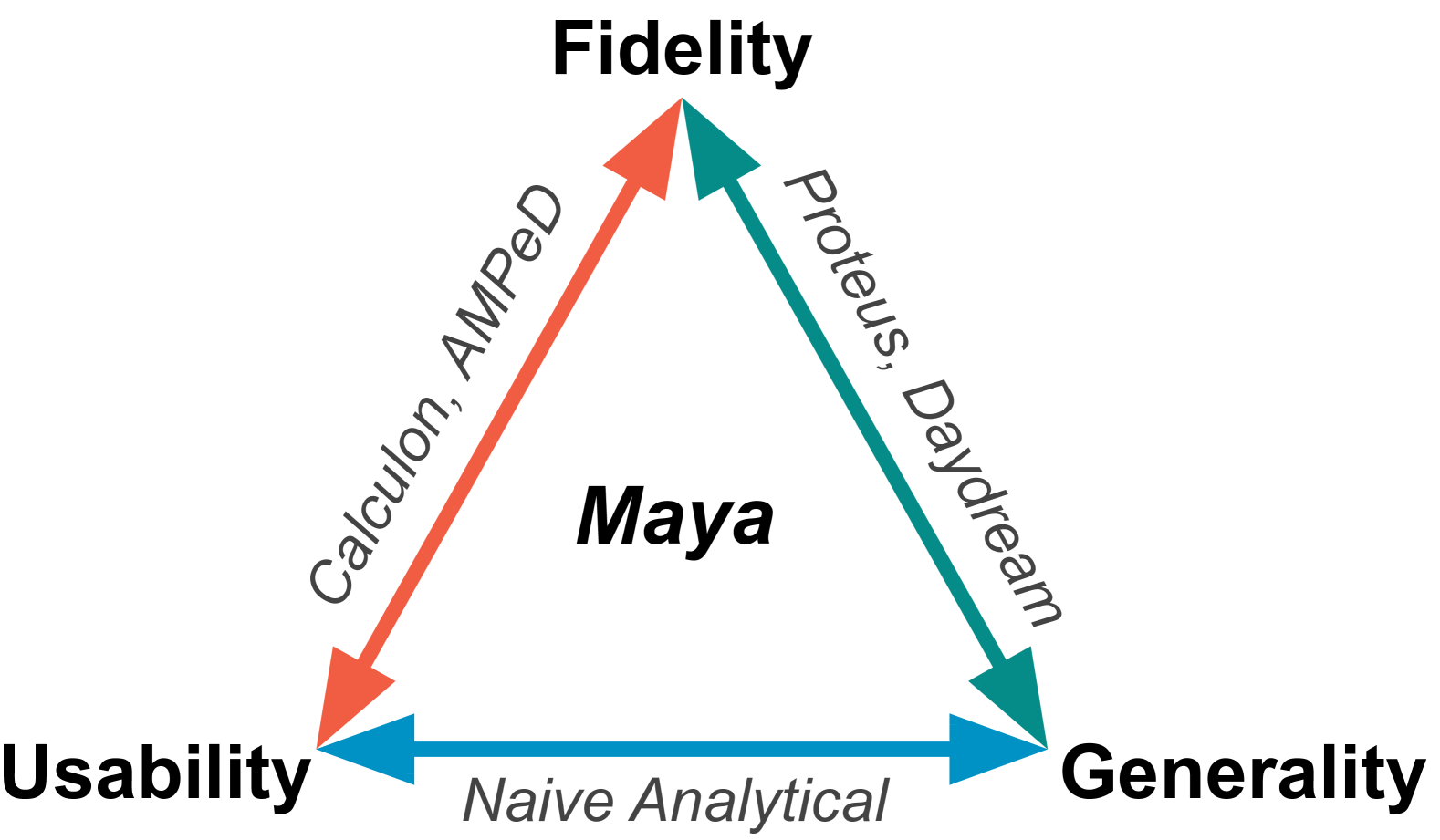
关键创新:Maya的关键创新在于其透明的设备运行时模拟技术,它无需用户修改代码或提供复杂的规范,即可捕获完整的工作负载行为。这消除了现有性能建模方法中存在的语义鸿沟,提高了预测准确性和通用性。与现有方法相比,Maya能够更准确地预测实际训练性能,并自动搜索最优的训练配置。
关键设计:Maya的关键设计包括:1) 设备API拦截机制:通过hook技术拦截训练框架对设备API的调用,获取底层操作信息。2) 精细化的设备运行时模拟:模拟GPU的计算、内存访问、通信等行为,考虑了硬件架构的细节。3) 性能模型的构建:基于模拟的运行时信息,建立性能模型,可以使用机器学习方法或基于规则的方法。4) 优化算法的选择:使用合适的优化算法(如遗传算法、贝叶斯优化)搜索最优的训练配置。
🖼️ 关键图片
📊 实验亮点
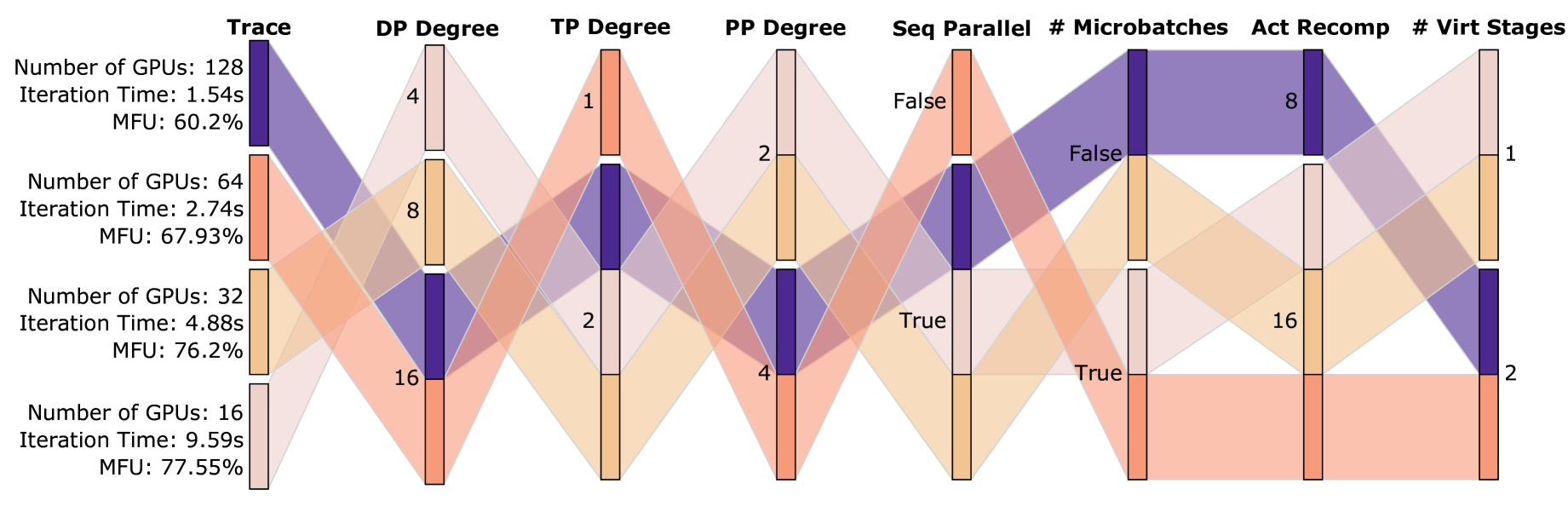
Maya在多种模型和优化策略上进行了评估,结果表明其预测误差小于5%。与现有方法相比,Maya能够识别出将训练成本降低高达56%的配置。这些实验结果表明Maya在深度学习训练优化方面具有显著优势。
🎯 应用场景
Maya可应用于各种深度学习模型的训练优化,尤其适用于大型基础模型的训练。通过自动搜索最优训练配置,可以显著降低训练成本,缩短训练时间,提高资源利用率。该研究成果对AI研究机构和企业具有重要价值,有助于加速AI模型的开发和部署。
📄 摘要(原文)
Training large foundation models costs hundreds of millions of dollars, making deployment optimization critical. Current approaches require machine learning engineers to manually craft training recipes through error-prone trial-and-error on expensive compute clusters. To enable efficient exploration of training configurations, researchers have developed performance modeling systems. However, these systems force users to translate their workloads into custom specification languages, introducing a fundamental semantic gap between the actual workload and its representation. This gap creates an inherent tradeoff: systems must either support a narrow set of workloads to maintain usability, require complex specifications that limit practical adoption, or compromise prediction accuracy with simplified performance models. We present Maya, a performance modeling system that eliminates these tradeoffs through transparent device emulation. By operating at the narrow interface between training frameworks and accelerator devices, Maya can capture complete workload behavior without requiring code modifications or translations. Maya intercepts device API calls from unmodified training code to directly observe low-level operations, enabling accurate performance prediction while maintaining both ease of use and generality. Our evaluation shows Maya achieves less than 5% prediction error across diverse models and optimization strategies, identifying configurations that reduce training costs by up to 56% compared to existing approaches.